
8 Most Important Data Structures Every Programmer Must Know
Knowledge of data structures and algorithms defines the programmers and their coding skills. Hence, it inevitably becomes essential to learn and implement the data structure for a software engineer. The below article informs you about the most important and widely used data structures.

Contents
So, let’s begin with understanding the data structures definition first.
Best-suited Data Structures and Algorithms courses for you
Learn Data Structures and Algorithms with these high-rated online courses

What are Data Structures?
The data structures in computer science are a way to demonstrate, organize, process, and manipulate the data in a system. It also shows the relationship between data elements.
Data structure enhances efficiency, reusability, and abstraction. It provides a better management way to store and access data. It plays a vital role in enhancing code performance.
For more information, read: What is Data structure?

8 Most Important Data Structures to know
Following are the 8 most important and widely used data structures.
Arrays in Data Structure
An array is a linearly-ordered data structure that holds the same type of elements in contiguous memory addresses. For instance, an integer array will store only integer values, whereas a character array will store characters only.
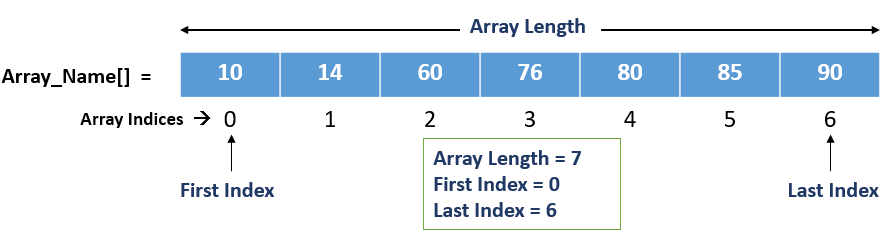
There are 2 types of Arrays:
- Single-Dimensional Array – One-dimensional arrays are organized in a linear list in memory. Their indexes run from 0 total array size-1.
- Multidimensional Array – Arrays can be extended to any number of dimensions, such as two dimensions, three dimensions, etc.
Applications of Arrays:
- A stage for other data structures like ArrayLists, heap, matrices, and vectors.
- Used for various sorting algorithms.
- CPU Scheduling
Linked Lists in Data Structures
A linked list data structure represents a sequence of nodes. In a singly linked list, each node points to the next node in the linked list. A doubly linked list gove each node pointers to both the next node and the previous node.
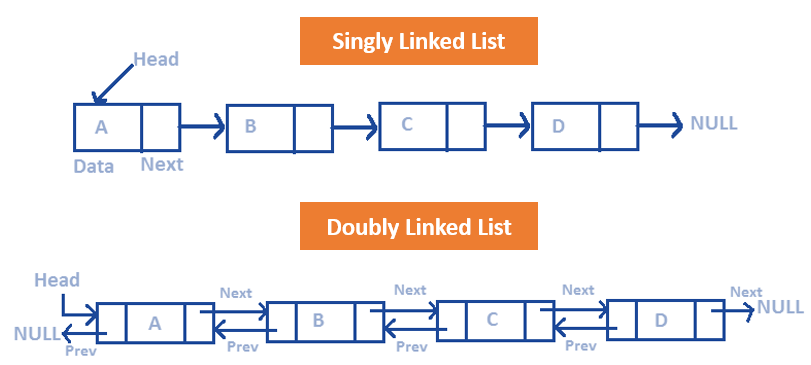
Unlike an array, a linked list does not provide constant-time access to a particular “index” within the list. If you want to find the Kth element in the list, you’ll need to iterate through K elements.
Advantage:- You can add and remove items from the beginning of the list in constant time.
Applications of Linked Lists:
- Searching, insertion, and deletion
- Linked Allocation of Files
- Polynomial Manipulation Representation
- Sparse Matrices Representation
Stacks in Data Structures
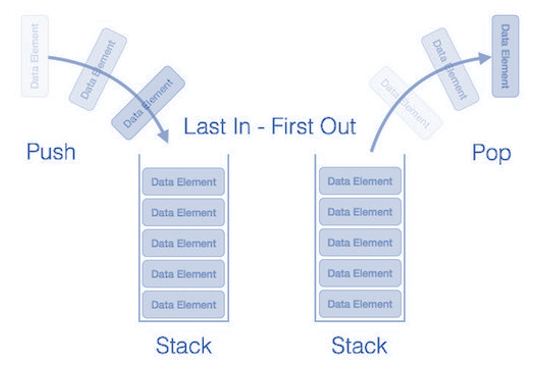
The stack data structure is precisely like the stack of data. In certain kinds of problems, it’s favorable to store the data in a stack rather than in an array. A stack use LIFO (last-in-first-out) ordering. Just like a stack of plates, the most recent item added to the stack is the first item to be removed.
It uses the following operations:
- Pop(): To remove the top item from the stack.
- Push(item): To add an item to the top of the stack.
- Peek(): Return the top of the stack.
- isEmpty(): To return true if and only if the stack is empty.
Unlike an array, a stack does not offer constant-time access to the ith item. However, it does allow constant-time adds and removes, as it doesn’t require time to shift elements.
A stack implementation can use an array or linked list. Note: stack implementation using a linked list is efficient if items were added and removed from the same side.
Applications of Stacks:
- Used for implementing certain recursive algorithms iteratively.
- Backtracking
- Processing Function Calls
- Expression Evaluation
Queues in Data Structures
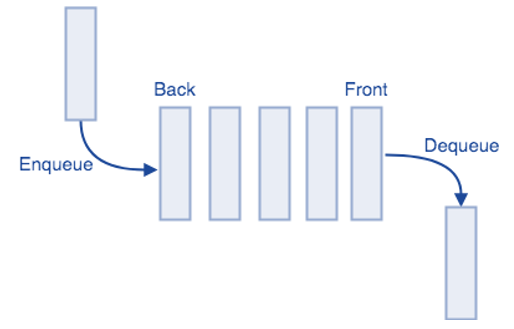
A queue implements FIFO (first-in-first-out) ordering. Similar to a line or queue at the ticket counter, items are removed from the data structure in the same order they got added.
The following operations by Queues:
- Remove(): To remove the first item in the list.
- Add(item): To add an item to the end of the list.
- Peek(): Return to the top of the queue.
- isEmpty(): To return true if the queue is empty.
Queues can be implemented using arrays and linked lists both.
Applications of Queues:
- Used for breadth-first search
- Implementing a cache
- CPU and Disk Scheduling
- Thread Management in Multithreading
Hash Tables in Data Structures
A hash table is a data structure that maps keys to values for a high efficient lookup. It aims to reduce the space problem faced during direct addressing or one-to-one mapping between keys and values.
There are several ways to implement hash tables. We’ll here show the simplest and most used way–an array of linked lists and a hash code function to insert a key and value.
- First, compute the key’s hash code (usually int or long). Note: Two different keys may have the same hash code, as there may be an infinite number of keys but a finite number of ints.
- Then, map the hash code to an index in the array. Using, hash (key) % array_length. Remember, two different hash codes can map to the same index.
- There is a linked list of keys and values at the computed index. Store the key and value in this index.
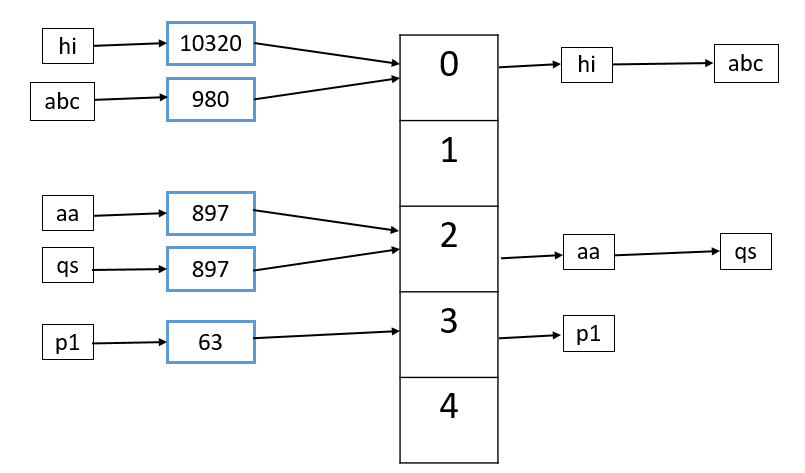
Note: We must use a linked list here because of collisions– Case 1: Two different keys with the same hash code. Case 2: Two different hash codes that map to the same index.
In order to retrieve the value pair by its key, just repeat the process. Compute the hash code from the key. Then compute index using hash code. Finally, search through the linked list for the value and this key.
Best Case Runtime: O(1)
Worst Case Runtime: O(N); where N = Number of Keys
Another way we can implement this is by using hash tables with a balanced binary search tree which gives O(log N) lookup time.
Advantage:- Use less space. We no longer need to allocate a large array.
Applications of Hash Tables:
- Database Indexing
- Pattern Matching
- Password Verification
- Implementing Associative Arrays and Sets in Data structures
Trees in Data Structures
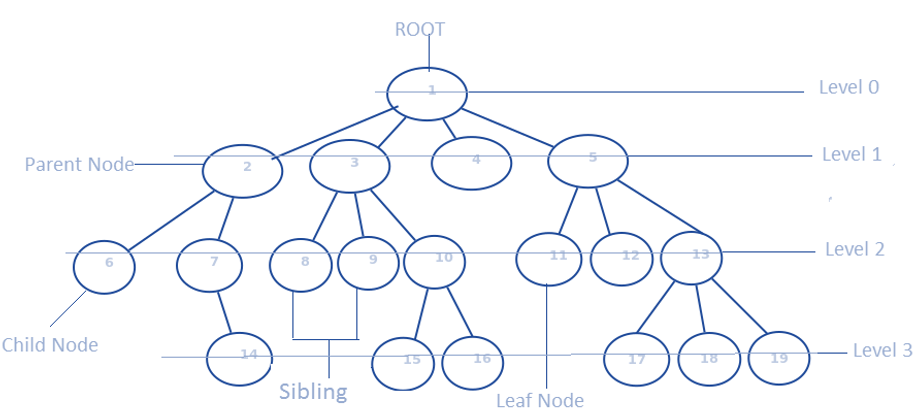
A tree is a data structure built up of nodes in hierarchical order.
- Each tree has a root node on top.
- The root node can have zero or more child nodes.
- Each child node also can have zero or more child nodes, and so on.
A tree can not contain cycles. Moreover, the nodes may or may not be in a particular order; they could have any data type as values. Also, they may or may not have links back to their parent nodes.
There are several types of trees to suit different requirements and constraints. A few examples are binary search tree, B tree, treap, red-black tree, splay tree, AVL tree, and n-ary tree.
Also, read: Types of Binary Tree in Data Structure
Moreover, A tree is a type of graph, but not all graphs are trees. In short, a tree is a connected graph without cycles.
Applications of Trees:
- Implementation of expression parsers and expression solvers
- JVM (Java Virtual Machine) uses trees to store Java objects
- For wireless networking
- Decision-based algorithms implementation in Machine Learning
Heaps in Data Structures
Heaps are a special case of binary trees in which the parent nodes get compared to their child nodes with their values and are arranged accordingly. It can be represented using trees and arrays both.
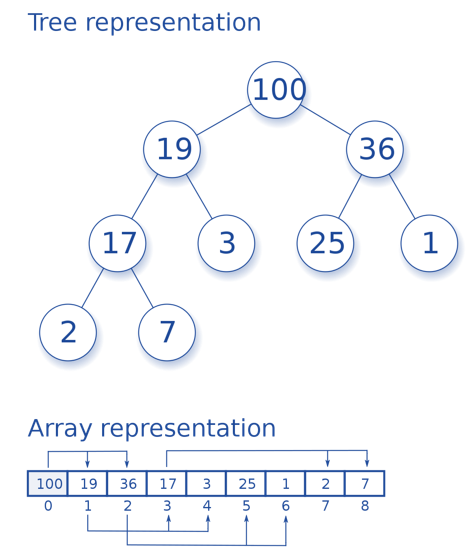
There are two types of Heaps:
- Min Heap: Here, the key of the parent is less than or equal to its children. It’s the min-heap property. The root contains the minimum value of the heap.
- Max Heap: Here, the parent’s key is greater than or equal to its children. It’s the max-heap property. The root contains the maximum value of the heap.
Applications of Heaps:
- Building Priority Queues
- Heap Sort Algorithm
- Queue functions implementation using heaps within O(log n) time.
- To search for the kᵗʰ smallest (or largest) value in a given array.
Graphs in Data Structures
A graph is a collection of nodes (vertices) with edges between them.
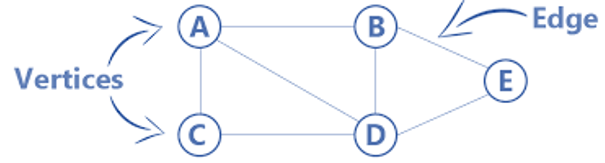
- Graphs can be directed (with directional edges) or undirected (without directions). The directed edges are like a one-way street; undirected edges are like a two-way road.
- A graph can consist of multiple isolated subgraphs. In case there is a path between every pair of vertices, it’s called a connected graph.
- Graphs can also have cycles (or not); an acyclic graph is the one without cycles.

Applications of Graphs:
- Built social media networks. Here, each user is a vertex, and when users connect, they create an edge.
- They are used for page ranking on Google Search. Representing web pages and links by search engines. Here, each page is a vertex, and the hyperlink between two pages is an edge.
- Used to show the locations and routes in GPS. Here, locations are vertices, and the routes connecting locations are edges. Graphs help to calculate the shortest route between two locations.
Conclusion
Learning Data Structure plays an essential role in the software engineer’s career journey. Hope the above article helped you map an understanding of the essential and most used data structures better. If you face any queries, kindly share them in the link below.
Recently completed any professional course/certification from the market? Tell us what liked or disliked in the course for more curated content.
Click here to submit its review with Shiksha Online.
FAQs
What is an ArrayList?
An ArrayList is an array that resizes itself as needed. A typical implementation is when the array is full, the array doubles in size.
What is a Binary Search Tree?
It is a binary tree in which every node fits a specific ordering property: all left descendants <= n <= all right descendants.
What are Complete Binary Tree, Full Binary Tree, and Perfect Binary Tree?
1. Complete Binary Tree: It is a binary tree in which every level of the tree is fully filled, excluding the last level. Even if it's filled, it is filled from left to right. 2. Full Binary Tree: A tree where every node has either zero to two children. That means no node has only one child. 3. Perfect Binary Tree: These trees are both complete and full. A perfect binary tree must have (2^k-1) nodes where k is the number of levels.
