
Stable Diffusion: Is it the Next Best Image Generation Tool?
All about Stable Diffusion is mentioned in this blog. By the end, you will also gain some insights on how it has been trained.

The open way that Stable Diffusion’s image generation model was released — allowing users to run it on their own machines, not just via API — has made it a landmark event for AI.
Andrew Ng
While the world divides itself between naysayers and optimists about AI, the convenience outweighs the challenges. In all this rage, you should take advantage of the open-source generative model, Stable Diffusion.
It creates photorealistic images based on text prompts, similar to everyone’s favourites – Dall-E 2 and Midjourney, but will be forever free. Unbelievable right? Keep reading.
What is Stable Diffusion?
Stable Diffusion from Stability AI is a groundbreaking, open-source image generator from text prompts launched in 2022. It has a lightweight architecture that can deliver amazing speed and quality on consumer-grade GPUs with less than 10 GB of VRAM, generating images of 512×512 pixels in the blink of an eye.
You will still need a gaming PC with a minimum of 6.9 GB VRAM and a modern graphics card like NVIDIA to install and use. Don’t expect it to run on smartphones yet. Otherwise, you can use the website.
How to Use Stable Diffusion Without Installing?
Go to stablediffusionweb.com just to get the hang of the possibilities quickly. You don’t have to login like you have to do with Midjourney or while generating images in Dall-E 2.

On stablediffusionweb.com, you can start putting prompts in a few different ways.
You can enter the Prompt or choose from the examples below on the same page.
You can also set the Guidance scale from 0 to 50. This classifier-free guidance scale follows to what degree the text prompt should guide the image generation process. Folks from Hugging Face state that values between 7 and 8.5 give great results.
In the below screenshot, the Prompt is ‘Cosmos of Cthulhu and Guy Fawkes’ with the Guidance Scale in 9.1.
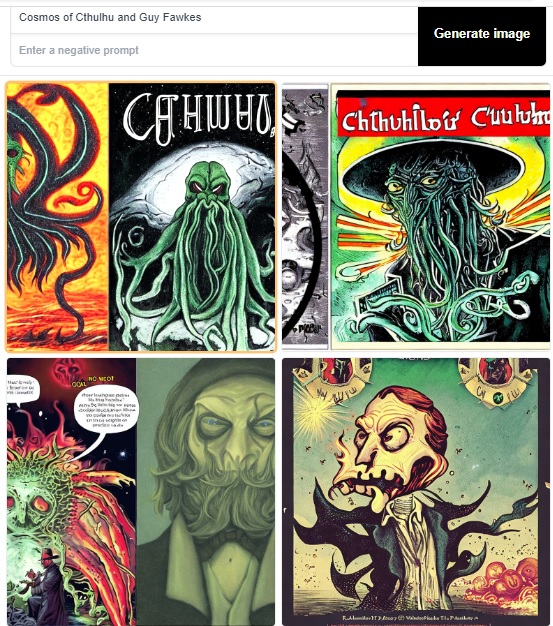
You will see four variations; you can click on each image to get a full view, or right-click on the image and open it in a new tab.
How to Install Stable Diffusion?
There are two ways to use. From your browser, you can visit the site – Stable Diffusion Web. Again, make sure you are running it on a good system.
If you are planning to install it, follow these steps
- Download the latest versions of Python and Git for Windows.
- Add Python to the PATH variable.
- Download the Stable Diffusion project file from GitHub and extract it.
- Download and extract the “768-v-ema.ckpt” checkpoint file from Hugging Face.
- Download and rename the config yaml file to “768-v-ema.ckpt” and place it in the same folder as the checkpoint file.
- Run the webui-user.bat file in the Stable Diffusion folder and wait for dependencies to install.
- Copy and paste the URL provided into a web browser to access the Stable Diffusion web interface.
- Input an image text prompt, adjust settings, and click “Generate” to create an image with Stable Diffusion.
And when you are using it on your PC and see the Stable Diffusion runtime error, it will need the recommended VRAM size.
Stable Diffusion Model Cards and Versions
Stable Diffusion has come up with two different versions, SD 1 and SD 2.
SD 1 versions
The model card on the Hugging Face website mentions these checkpoints of the generator.
Stable-diffusion-v1-1
This checkpoint was randomly initialized and trained for 237,000 steps at 256×256 resolution on laion2B-en. It was also trained for 194,000 steps at 512×512 resolution on laion-high-resolution, using 170 million examples with a resolution of at least 1024×1024.
Stable-diffusion-v1-2
This checkpoint continued training from stable-diffusion-v1-1. It was trained for 515,000 steps at 512×512 resolution on “laion-improved-aesthetics”, a filtered subset of laion2B-en that includes images with an original size of at least 512×512, an estimated aesthetics score above 5.0, and an estimated watermark probability below 0.5. The watermark estimate is based on LAION-5B metadata, and the aesthetics score is estimated using an improved estimator.
Stable-diffusion-v1-3
This checkpoint continued training from stable-diffusion-v1-2. It was trained for 195,000 steps at 512×512 resolution on “laion-improved-aesthetics”, with 10% less text-conditioning to improve classifier-free guidance sampling.
Stable-diffusion-v1-4
This checkpoint also continued training from stable-diffusion-v1-2. It was trained for 195,000 steps at 512×512 resolution on “laion-improved-aesthetics”, with 10% less text-conditioning to improve classifier-free guidance sampling.
Stable-diffusion-v1-4 (updated)
This checkpoint resumed training from stable-diffusion-v1-2 and was trained for an additional 225,000 steps at 512×512 resolution on “laion-aesthetics v2 5+” with 10% less text-conditioning to improve classifier-free guidance sampling.
SD 2
Stable Diffusion 2 has a few changes from the first sub-versions. It uses the open-source version OpenCLIP, instead of CLIP. The next changes are the better performance of negative prompts and textual inversions.
Why is Stable Diffusion Free?
Stability AI is making image creation using machine learning more democratic by making Stable Diffusion completely free. This image generation tool has no limitations on what you can prompt or create. Dall-E 2 and Midjourney, on the other hand, have set limitations on inappropriate prompts that lead to NSFW images.
Also, the CreativeML OpenRAIL++ licence is free. The authors do not assert rights over the outputs you create using the model. You have the permission to use them as you wish.
But you will be responsible for ensuring that your use of the outputs complies with the terms of this licence. The openrail m licence also prohibits you from sharing any content that would violate any laws.
How Stable Diffusion Works?
While based on natural language, it combines the latent diffusion model derived from Runway and CompVis with conditional diffusion models developed by lead generative AI developer Katherine Crowson from Dall-E 2, Imagen, and others.
It has been trained on LAION-Aesthetics, a dataset from LAION 5B that has 5.85 billion images. Also, images are publicly available.
Since Stability AI is partners with Amazon Web Services, it has access to the world’s fifth-largest supercomputer, 4000 A1 EZRA-1 Ultracluster. And, it is trained on this using the machine learning system – latent diffusion model (LDM) that is now set to replace GANs (Generative Adversarial Networks). There have also been 10,000 beta testers generating 1.7 billion images per day, since its launch.
Stability AI chose to use a latent diffusion model to reduce computational power. LDM can generate compressed image representations, which standard diffusion models cannot; because of this, they need a high GPU.
This tool’s latent diffusion model is trained on the frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
According to Hugging Face, there are three components in the latent diffusion model of Stable Diffusion.
VAE, an Autoencoder
VAE has two parts: an encoder and a decoder. The encoder changes the image into a low-dimensional latent representation that becomes the input for the U-Net model. The decoder turns the latent representation back into an image. To do latent diffusion training, the encoder creates the latents for the images for the forward diffusion process, which adds more noise at each step. For inference, the VAE decoder changes the denoised latents produced by the reverse diffusion process back into images. We only need the VAE decoder during inference.
U-Net
The U-Net is a tool used for making images less noisy. It does this by first making a lower quality version of the image, and then using that to predict what the less noisy version should look like. To make sure important information isn’t lost in the process, connections are added between different parts of the tool.
Text Encoder
The text-encoder changes the input prompt like “Horse riding a bicycle” into a language that U-Net can understand. It’s a simple transformer-based encoder that transforms input tokens into text-embeddings. Stability AI’s model follows Imagen and doesn’t train the text-encoder during training. It uses the already trained text-encoder of CLIPTextModel.
Parting Thoughts
Stable Diffusion is an amazing tool for text-to-image creation using the power of artificial intelligence. Making this an open-source licence and allowing users to install and run on consumer laptops are reasons why it is a great alternative to Midjourney and Dall-E 2.
