
Decision Tree Algorithm for Classification
The article gives an introduction to decision tree algorithm for classification, with example in Python.

Imagine, you got a new job offer and need to decide whether you are going to take it or leave it. You consider several factors; starting from Salary, distance and commute time to the office, other perks and benefits, career growth, and so on. But you don’t choose all the factors at one time. Your brain processes the information through a series of if-else branches like the picture below:
You start thinking about the salary first; which becomes the main factor or starting point for your analysis.
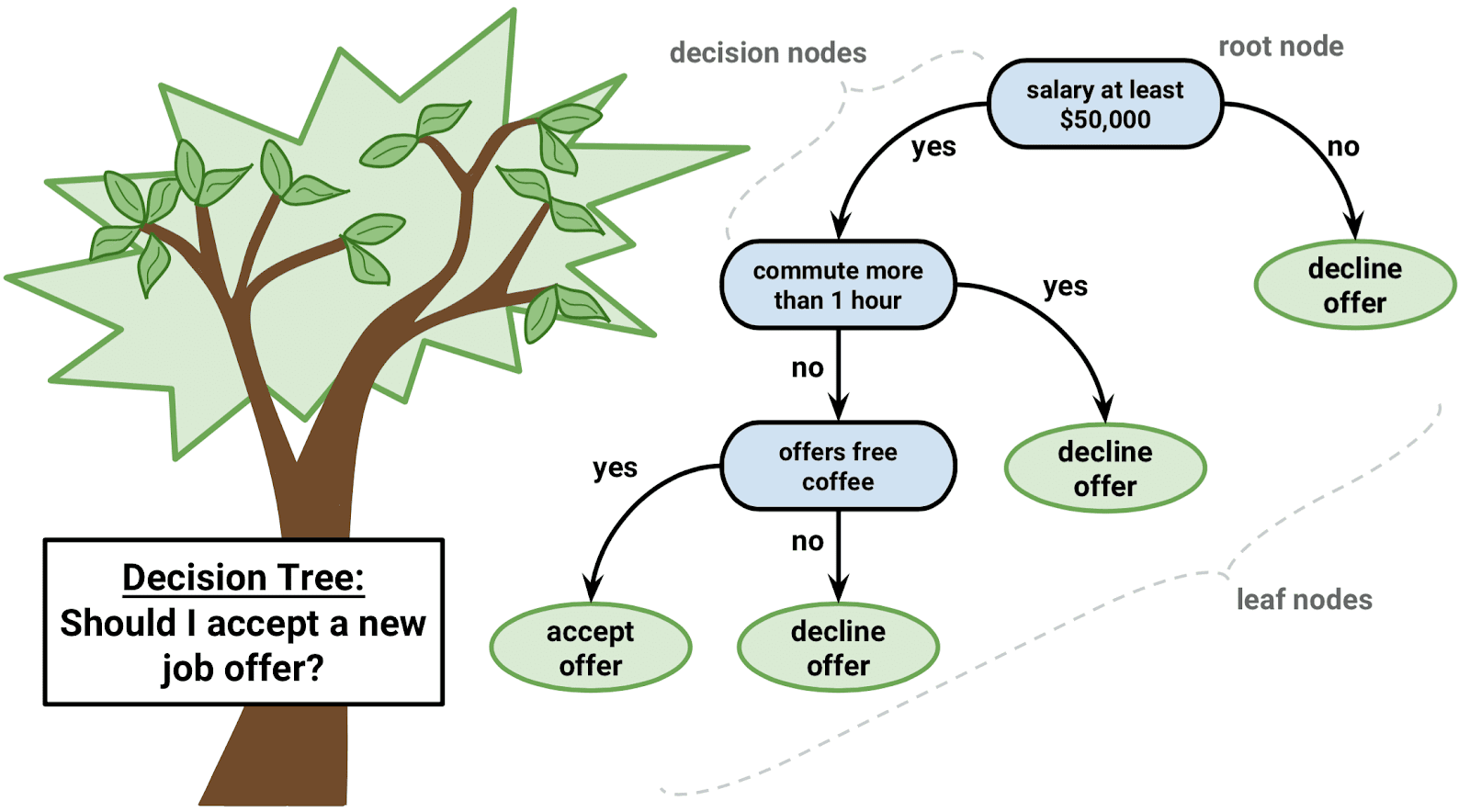
If salary criteria are met and it’s above $50K then do you think the commute time to the office is more than an hour or less? If the office is nearby and you can reach it easily, then you start thinking about whether the office offers you coffee and other perks. Gradually if all those conditions are met, you finally go ahead and accept the offer.
The decision tree algorithm works exactly in the same fashion. In some sense, it’s the real-world replica of how a human brain makes decisions with series of clarifications and asks processing each one at a time in a sequential manner.

Table of Content
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
Introduction to Decision tree algorithm:
A decision tree is a machine learning algorithm that is used for classification and regression tasks. It works by creating a tree-like model of decisions and their possible consequences, with the goal of accurately predicting the outcome of a given input.
To create a decision tree, the algorithm begins by considering all the available features (also called “attributes”) of the input data. It then selects the feature that best splits the data into different classes or categories. This process is repeated for each split, with the algorithm choosing the feature that best divides the data at each step. The process continues until the tree is fully grown, or until a stopping criterion is reached (such as a maximum tree depth or a minimum number of samples in a leaf node).
Once the decision tree is created, it can be used to make predictions on new input data by following the path down the tree based on the feature values of the input data.
Decision trees are easy to interpret and understand, and they can handle both continuous and categorical data. However, they can be prone to overfitting, particularly if the tree is allowed to grow too deep. To mitigate this, techniques such as pruning (removing branches from the tree) or limiting the maximum depth of the tree can be used.
In machine learning, a decision tree may be defined as a non-parametric supervised algorithm. This algorithm uses a series of the if-else-based flowchart-like tree structures. This obtains the predictions that result from a sequence of feature-based splits. It starts with a root node, your first point of consideration: Salary. It ends with a decision made by leaves (Terminal nodes: Whether you accept or decline the offer)
Important Terminologies related to a Decision Tree algorithm
Here are some terms and terminologies related to decision trees:
- Root node: The top node of a decision tree, representing the entire population or sample.
- Splitting: The process of dividing a node into two or more sub-nodes based on a feature or attribute value.
- Decision node: A node that represents a decision to be made based on the value of a feature or attribute.
- Leaf node: A terminal node that does not have any sub-nodes, representing a classification or prediction.
- Pruning: The process of removing branches from a decision tree to reduce overfitting and improve generalization to new data.
- Decision boundary: The line or plane that separates different classes or categories in the data.
- Gini index: A measure of the purity of the nodes in a decision tree, based on the proportion of samples belonging to a particular class.
- Information gain: A measure of the reduction in entropy (randomness or uncertainty) caused by splitting the data based on a particular feature.
- Overfitting: The phenomenon where a model fits the training data too well and does not generalize well to new data.
- Underfitting: The phenomenon where a model does not fit the training data well and therefore performs poorly on both the training and test data.
A decision tree in general is termed a Classification and Regression Tree (CART). It can be used for both classification problems as well as for continuous variable predictions too. However, in this article, we will restrict ourselves to a real-world example in classification only.

 Read Later
Read Later

Application of Decision Tree
There are multiple real-life applications of Decision trees. Some examples include:
- Medical diagnosis: Make medical diagnoses based on a set of symptoms or test results.
- Credit approval: Banks and financial institutions can use decision trees to predict the likelihood of an individual defaulting on a loan or credit card based on their credit history and other factors.
- Marketing: Predict customer behavior and make targeted marketing campaigns based on factors such as age, income, and purchasing history.
- Fraud detection: Identify fraudulent transactions in areas such as credit card use or insurance claims.
- Oil reservoir characterization: Predict the characteristics of an oil reservoir based on data such as rock type and porosity.
- Customer churn prediction: Predict the likelihood of a customer churning (leaving a company) based on factors such as their usage patterns and customer service interactions.
Growing a tree
The decision tree algorithm starts at the root node and progresses downward in search of the purest set of data points. Speaking simply, the objective of a decision tree algorithm is to create splits at different nodes such that the resulting nodes (set of observations or points) are as homogeneous as possible.
As can be seen in the below figure, node A is an equal mix of blue and yellow dots and the most impure node in that sense, node C is all blue and the purest set of data points, and node B falls in-between node A and C.

Concept of Entropy and Splits:
In decision tree analysis, entropy is a measure of the impurity or randomness of a set of data. It is commonly used to evaluate the quality of a split in a decision tree. The idea is that a split that results in pure, homogeneous subsets (low entropy) is more useful for making accurate predictions than a split that results in mixed or heterogeneous subsets (high entropy).
In information theory, entropy is a measure of the uncertainty or randomness of a random variable. In decision tree analysis, it is used to measure the impurity or randomness of a set of data. The entropy of a set of data is calculated using the following formula:
Entropy = – ∑(p(i) * log2(p(i)))
where p(i) is the proportion of data points in the set that belong to class i.
For example, consider a set of data with two classes, A and B. If the data is perfectly balanced, with 50% of the data points belonging to class A and 50% belonging to class B, the entropy would be 1. If the data is completely imbalanced, with all data points belonging to class A or all data points belonging to class B, the entropy would be 0.
In a decision tree, the entropy of a set of data is used to evaluate the quality of a split. A split that results in pure, homogeneous subsets (low entropy) is more useful for making accurate predictions than a split that results in mixed or heterogeneous subsets (high entropy). The goal of the decision tree is to find the split that results in the lowest possible entropy, so that the resulting subsets are as pure as possible.
Methods of splitting and growing a tree (concept of information gain):
While building a decision tree it becomes very important in choosing the right feature or predictor for splitting and growing the treetop to down. To obtain the right set of features, the concept of Information gain is used which is developed on the principle of maximum entropy reduction while traversing from the top node to the bottom node by choosing the right set of features.

The concept of information gain is presented below:
Say in a real-life problem, you need to decide which factor is more important among Energy level and motivation for going to the gym. While exploring this the following set of responses in the form of a decision tree were observed.



Therefore, it’s evident that information gain or reduction in entropy would be higher if we chose Energy as the next feature. Therefore, the tree would select “Energy” as the next splitting criteria.
The split with the highest information gain will be taken as the first split. The process will continue until all children nodes are pure, or until the information gain is 0. That’s the reason, decision tree algorithms are termed greedy algorithms. They build the tree until each and every node becomes completely pure.
However, growing a tree to reach the purest set of nodes may not be always feasible owing to computational challenges and overfitting problems on the training data. That is why the concept of pruning comes into the picture. The growth of the decision tree can be restricted by cutting the branches using hyperparameter tuning or by cost complexity pruning. The details of this are outside the scope of this article. However, we should have a clear understanding of these aspects as well while building a model using the CART algorithm.
Example with python implementation:
We will now focus on a real-world problem and implementation of a decision tree algorithm using the Scikit learn package of python.
We introduce a dataset from the UCI Machine Learning repository. It’s called “Pima Indians Diabetes Database “.
This dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. This dataset aims to diagnostically predict if a patient has diabetes, based on certain diagnostic measurements. Predictor variables include – the number of pregnancies the patient has had, their BMI, insulin level, age, and so on. The label variable or the dependent variable in this case is a 0/1 binary flag. Where 0 means the patient is non-diabetic and 1 means the patient is diabetic.
Sklearn decision tree
# Load librariesimport pandas as pdfrom sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifierfrom sklearn.model_selection import train_test_split # Import train_test_split functionfrom sklearn import metrics #Import scikit-learn metrics module for accuracy calculationcol_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']# load datasetpima = pd.read_csv("diabetes.csv", header=0, names=col_names)pima.head()
First, we import the required libraries and also set the column names for the dataset for easy interpretation.
The first 5 rows of the dataset look like below:

After loading the data, we understand the structure and variables. We determine the target and feature variables and divide the data into training and testing sets in 70:30.
#split dataset in features and target variablefeature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']X = pima[feature_cols] # Featuresy = pima.label # Target variable # Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
Post the data set is split between the training and testing part we now apply the decision tree model on the training set; predict the results on the training and testing set both and then check the accuracy. We have also restricted the max_depth which is one of the key hyperparameters for a decision tree model. It depicts the longest path from the root node to the leaf node. By doing this we are also introducing the concept of hyper-parameter tuning in order to restrict the tree from overfitting.
# Create Decision Tree classifier objectclf = DecisionTreeClassifier(criterion="entropy", max_depth=3)# Train Decision Tree Classifierclf = clf.fit(X_train,y_train)#Predict the response for test datasety_pred_train = clf.predict(X_train)y_pred_test = clf.predict(X_test) # Model Accuracy, how often is the classifier correct?print("Accuracy in training set:",metrics.accuracy_score(y_train, y_pred_train))print("Accuracy in testing set:",metrics.accuracy_score(y_test, y_pred_test))
Model Accuracy
The model accuracy as obtained in the training and testing data set is as below:

With a maximum depth of 3, the decision tree algorithm here achieves a very similar accuracy. in both training and testing datasets. This can be considered a very good fit.
In the next and final step; we visualize the model using pydotplus and graphviz packages within the sklearn framework.
from sklearn.externals.six import StringIO from IPython.display import Image from sklearn.tree import export_graphvizimport pydotplusdot_data = StringIO()export_graphviz(clf, out_file=dot_data, filled=True, rounded=True, special_characters=True, feature_names = feature_cols,class_names=['0','1'])graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_png('diabetes.png')Image(graph.create_png())
The final structure of the model looks like the below :
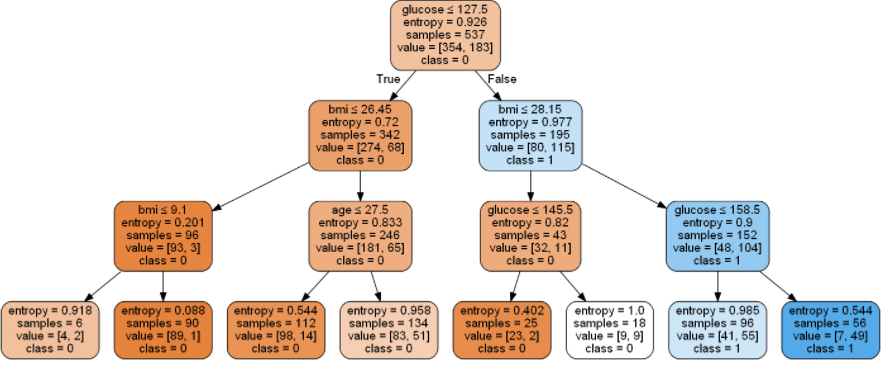
Interpretation of the model: As can be seen the branching starts with the first factor as “glucose”. Depending on the level of glucose in someone’s blood the next factor that the model considers is “BMI” or Body Mass Index. Finally, when someone’s BMI is also checked post glucose level the third most important variable here is “age”
From the color-coding of the different nodes, it’s evident that with less entropy on the class=0 side. It suggests that in the non-diabetic side the nodes turn dark orange; whereas for the class=1 side or for the diabetic cases, with less entropy, the color turns dark blue.
End notes:
In this article, we have discussed and introduced the concept of a decision tree for the classification problem. We have also touched upon how a tree is built with a real-world example. I hope this would be a good starting point for everyone to learn and apply the decision tree. Further reading materials can be explored on hyperparameter tuning and application for continuous variables also.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst
