
Deep Learning Interview Questions and Answers
Deep learning is the technique that comes closest to the way we humans learn. It has become increasingly important in the field of artificial intelligence (AI) and jobs are being created across domains. The article covers some of the most popular deep learning interview questions and answers.

Deep learning is one of the most trending skills of the century. It is all about using neural networks to improve things such as speech recognition, computer vision, and natural language processing. In recent years, deep learning has helped advance areas as diverse as object perception, machine translation, and speech recognition – all particularly complex areas for AI researchers.
Learn more – What is Deep Learning?
Deep learning has marked a remarkable growth in the past 3-4 years and jobs are emerging across different industries such as automobile, healthcare, software, cybersecurity, electronics, BFSI, etc. If you are looking for job opportunities in this field then below interview questions on deep learning would be really helpful in making your career move.

Top Deep Learning Interview Questions & Answers
Below are some of the most commonly asked deep learning interview questions –
Q1. What is the difference between AI, Machine Learning, and Deep Learning?
Ans. AI (Artificial Intelligence): Artificial Intelligence refers to the study, development, and application of computer techniques that allow computers to acquire certain skills of human intelligence.
ML (Machine Learning): Machine learning is a subset of Artificial Intelligence where people “train” machines to recognize patterns based on data and make their predictions. ML algorithms are mathematical algorithms that allow machines to learn by imitating the way we humans learn.
DL (Deep Learning): Deep Learning is a subset of ML in which the machine is able to reason and draw its own conclusions, learning by itself. Deep Learning uses algorithms that mimic human perception inspired by our brain and the connection between neurons. Most deep learning methods use neural network architecture.
Explore DL courses
Best-suited Interview preparation courses for you
Learn Interview preparation with these high-rated online courses

Q2. What is a neural network?
Ans. A neural network is a system of programs and data structures that approximates the functioning of the human brain. A neural network usually involves a large number of processors operating in parallel, each having its own small sphere of knowledge and access to data in its local memory.
A neural network is initially “trained” or fed with large amounts of data and rules about relationships (e.g. “a grandparent is older than a person’s father”). A program can then tell the network how to behave in response to an external stimulus (e.g. input from a computer user interacting with the network) or it can initiate the activity itself, within limits of their access to the external world.
Deep learning uses neural networks to learn useful representations of features directly from data. For example, you can use a pre-trained neural network to identify and remove artifacts such as noise from images.
Must Read – Deep Learning vs Machine Learning – Concepts, Applications, and Key Differences
Q3. What is the idea behind the GANs?
Ans. The Generative Adversarial Network (GAN) is a very popular candidate in the field of machine learning that has showcased its potential to create realistic-looking images and videos. GANs consist of two networks (D & G) where –
D =”discriminating” network
G = “Generative” network.
The goal is to create data: images, for example, that cannot be distinguished from actual images. Suppose we want to create an adversarial example of a cat. Network G will generate images. Network D will classify the images according to whether it is a cat or not. The cost function of G will be constructed in such a way that it tries to “trick” D into always classifying its output as a cat.

Image – Generative Adversarial Network function
Q4. In the neural network, if the hidden layer has a sufficient number of units, can it approximate any continuous function?
Ans. The Universal Approximation Theorem states that a simple feedforward neural network (i.e. multilayer perceptron) with a single hidden layer and a standard activation function can approximate any continuous function if the hidden layer has a sufficient number of units. If the function jumps around or has large gaps, it cannot be approximated.
Also Read – Top Machine Learning Interview Questions and Answers
Q5. How will you solve the gradient explosion problem?
Ans. There are many ways to solve the gradient explosion problem. Some of the best experimental methods are –
Redesign the network model – In deep neural networks, the gradient explosion can be solved by redesigning the network with fewer layers. Using a smaller batch size is also good for network training. In recurrent neural networks, updating in fewer previous time steps during training (truncated backpropagation over time) can alleviate the gradient burst problem.
Use the ReLU trigger function – In deep multilayer perceptron neural networks, gradient explosion can occur due to activation functions, such as the previously popular Sigmoid and Tanh functions. Using the ReLU trigger function can reduce gradient bursts. Adopting the ReLU trigger function is one of the most popular practices for hidden layers.
Explore Deep Learning and Neural Networks Online Courses
Use short and long-term memory networks – In the recurrent neural network, the gradient explosion may be due to the instability of the training of a certain network. For example, backpropagation over time essentially converts the recurring network into a deep multilayer perceptron neural network. The use of short- and long-term memory units (LSTM) and related gate-like neural structures can reduce the gradient burst problem. The use of LSTM units is the latest best practice for sequence prediction suitable for recurrent neural networks.
Use gradient clipping – In very deep multilayer perceptron networks with large batches and LSTMs with long input sequences, gradient bursts can occur. If the gradient burst still occurs, you can check and limit the size of the gradient during the training process. This process is called gradient truncation. There is a simple and effective solution to dealing with gradient bursts: If the gradients exceed the threshold, cut them off.
Specifically, it checks whether the value of the error gradient exceeds the threshold, and if it exceeds it, the gradient is truncated and the gradient is set as the threshold. Gradient truncation can alleviate the gradient burst problem to some extent (gradient truncation, i.e. the gradient is set as a threshold before the gradient descent step).
Use weight regularization – If the gradient explosion still exists, you can try another method, which is to check the size of the network weights and penalize the loss function that produces a larger weight value. This process is called weight regularization and generally uses either the L1 penalty (the absolute value of the weight) or the L2 penalty (the square of the weight). Using L1 or L2 penalty terms for loop weights can help alleviate gradient bursts.
To learn about data science, read our blog – What is data science?
Q6. What is the difference between Stochastic Gradient Descent (SGD) and Batch Gradient Descent (BGD)?
Ans. Gradient Descent and Stochastic Gradient Descent are algorithms used in linear regression to find the set of parameters that minimize a loss function.
Batch Gradient Descent – BGD involves MULTIPLE calculations over the full training set at each step. It is a slower and expensive process if we have very large training data. However, this is great for convex or relatively smooth error manifolds.
Stochastic Gradient Descent: SGD picks up a RANDOM instance of training data at each step and then computes the gradient. This makes SGD a faster process than BGD.
Q7. What is a confusion matrix and why do you need it?
Ans. A confusion matrix is a tool that allows visualizing the performance of a supervised learning algorithm. Each column of the matrix represents the number of predictions of each class, while each row represents the instances in the real class, that is, in practical terms it allows us to see what types of successes and errors our model is having when it comes to going through the learning process with data. The confusion matrix allows us to check if the algorithm is misclassifying the classes and to what extent.

Image – Confusion Matrix
Must Read – Data Science Interview Questions and Answers
Q8. What is a Fourier transform?
Ans. Fourier Transform is a mathematical technique that transforms any function of time to a function of frequency. Fourier transform uses a time-based pattern for input and calculates the overall cycle offset, rotation speed, and strength for all possible cycles. Fourier transform is best applied to waveforms as it has functions of time and space. A Fourier transform decomposes a waveform into a sinusoid when applied.
Q9. What is the difference between overfitting and underfitting?
Ans. Overfitting – In overfitting, a statistical model describes any random error or noise, and occurs when a model is super complicated. An overfit model has poor predictive performance as it overreacts to minor fluctuations in training data. Overfitting demonstrates good performance on the training data and poor generalization to other data.
Underfitting – In underfitting, a statistical model is unable to capture the underlying data trend. This type of model also shows poor predictive performance. Underfitting demonstrates poor performance on the training data and poor generalization to other data.
Q10. What are the activation functions?
Ans. In artificial neural networks, the activation function of a node translates inputs into outputs. Activation function calculates the weighted sum and adds bias to it, and
decides if a neuron should be activated or not. The main task of the activation function is to introduce non-linearity into the output of a neuron. Various Activation functions are –
- Binary Step Function
- Linear Activation Function
- Sigmoid/Logistic Activation Function
- The derivative of the Sigmoid Activation Function
- Tanh Function (Hyperbolic Tangent)
- Gradient of the Tanh Activation Function
- ReLU Activation Function
- The Dying ReLU problem
11. What are the applications of deep learning?
Ans. Some of the top applications of deep learning across industries are –
- Self Driving Cars
- News Aggregation
- Fraud Detection
- Natural Language Processing
- Virtual Assistants
- Automatic Machine Translation
- Language Translations
- Pixel Restoration
- Demographic Predictions
- Election Predictions
11. What is autonomous learning in deep learning?
Ans. Autonomous learning is the process where machine learning algorithms detect patterns and learn to make predictions and recommendations by processing data and experiences. They do not receive any explicit programming instructions, yet identify groups of data that show similar behavior (for example, they form groups of customers that show similar buying behavior).
12. What are Convolutional neural networks?
Ans. Convolutional Neural Networks are a type of Artificial Neural Networks with supervised learning that processes its layers by imitating the visual cortex of the human eye to identify different characteristics in the inputs that ultimately make it able to identify objects and “see”.
Here “neurons” correspond to receptive fields in a very similar way to neurons in the primary visual cortex (V1) of a human brain. Convolutional neural networks consist of multiple specialized hidden layers of convolutional filters of one or more dimensions. After each layer, a function is added to perform non-linear causal mapping and recognize complex shapes such as a face or the silhouette of a human or an animal.
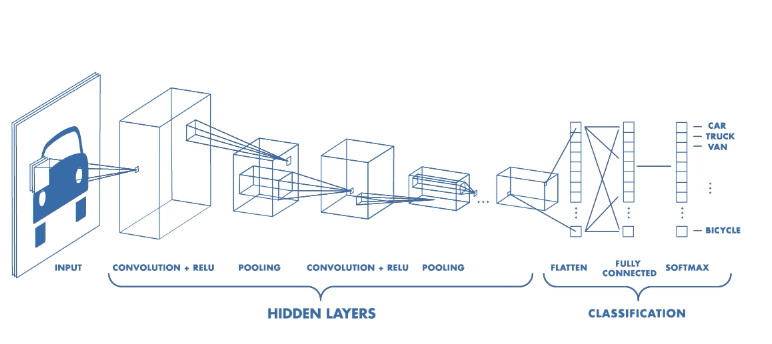
Image – Basic Convolutional Neural Network (Source – Towards Data Science)
13. What are the different types of Convolutional Neural Networks?
Ans. There are five types of Convolutional Neural Networks –
- LeNet
- AlexNet
- VGG-16 Net
- ResNet
- Inception Net
LeNet – LeNet is one of the oldest convolution neural networks designed to classify handwritten digits from 0–9, of the MNIST Dataset. It comprises 7 layers, which include two sets of both convolutional and average pooling layers, a flattening convolutional layer, two fully connected layers, and a softmax classifier.

Image – LeNet Architecture (Original image published in [LeCun et al., 1998]) (Source – Researchgate)
Must Read – Different Types of Neural Networks in Deep Learning
AlexNet – AlexNet is similar to LeNet but has a deeper architecture with 8 layers and added filters. The layers include convolutional layers, max pooling, dropout, data augmentation, ReLU, and SGD.
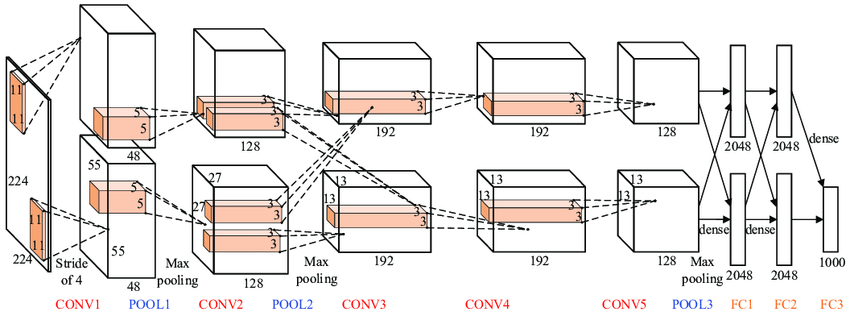
Image – AlexNet Architecture (Source – Medium)
VGG-16 Net– VGG-16 Net is a 16 layers deep convolutional neural network. It has many layers but the architecture is very simple and is among the most preferred type of convolutional neural networks among developers. VGG-16 Net has 140 million parameters to handle, thus ensuring the most efficient output.

Image – VGG-16 Net Architecture (Source – Researchgate)
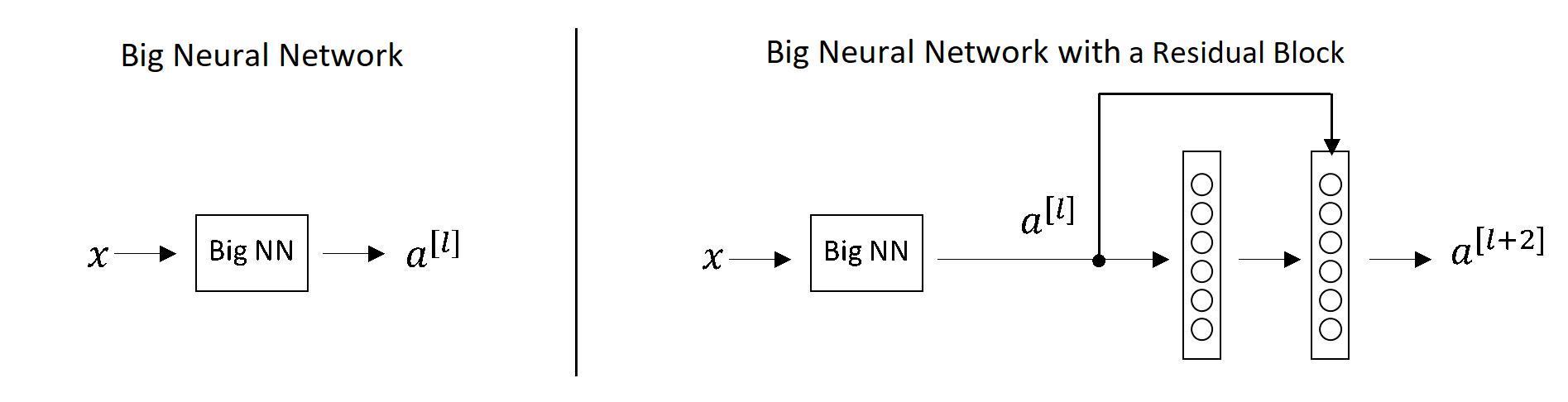
ResNet – ResNet or Residual networks are over 100 layers of deep networks. These networks learn residual functions with reference to the layer inputs and skip connections solve the problem of vanishing gradient in deep neural networks. The below image describes normal deep networks vs networks with skip connections, showing the difference in outputs.
Inception Net – Inception Net or GoogleLeNet has a 27 layers deep architecture and is designed to tackle the loss of data. It uses input data to compute multiple different conversions in parallel, concatenating them in a single output.
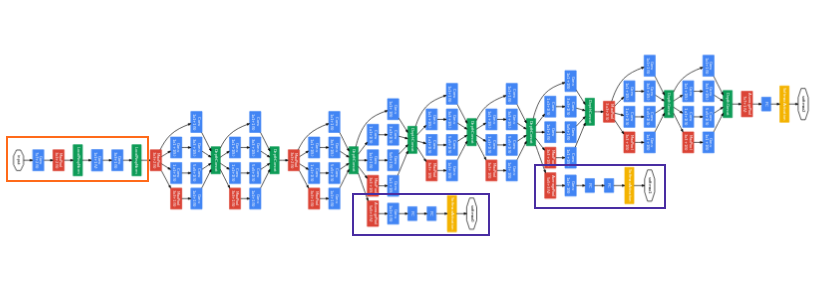
Image – Inception Net or GoogLeNet – Orange box – Stem; Purple boxes – Auxiliary classifiers; Wide parts – Inception modules (Source – Towards Data Science)
If you have recently completed a professional course/certification, click here to submit a review.

Rashmi Karan is a writer and editor with more than 15 years of exp., focusing on educational content. Her expertise is IT & Software domain. She also creates articles on trending tech like data science,