
Gradient Descent in Machine Learning

Gradient Descent is the backbone of many machine learning algorithms, guiding models to find the optimal solutions. In this tutorial, you'll learn how Gradient Descent works, why it's crucial for minimizing errors, and how to apply it effectively in your projects. Whether you're new to machine learning or looking to deepen your understanding, this guide will provide you with the insights and practical knowledge you need to take your models to the next level. Dive in and start optimizing your learning journey!
Table of Contents:
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
Cost Function:
Cost function measures the performance of machine learning models.
It quantifies the error between the actual and predicted value of the observation data.
In linear regression, there are many evaluation metrics (mean absolute error, mean squared error, R squared, RMSLE, RMSE etc) to quantify the error, but we generally use Mean Squared Error:

This Mean squared function is also referred to as Cost Function.
Note: Depending upon the evaluation metrics, cost functions are different.

Gradient Descent:
Gradient Descent is an optimisation algorithm used to find the value of the parameters of a function that minimizes the cost function.
Or
In layman’s terms, Gradient descent is an iterative optimization algorithm to find the local minima of the cost function.
In the gradient descent, we calculate the next point using the gradient of the cost function at the current position.
The process is given by:

Now, we will discuss all the above-mentioned learning rates, gradients in full detail.
Learning Rate:
It is a scaling factor that controls the step size to decide the next position (point).
It is one of the decisive factors for the performance of the model.
- The smaller the learning rate, the smaller the change in step size thus the slower rate of convergence to the optimal value
- Larger the learning rate, the greater the change in step size thus a higher the rate of convergence to the optimal value.
Limitation:
- If the value of the learning rate is very small, we may reach the maximum step before reaching the optimal value.
- If the value of the learning rate is very high, it may lead to converging to any sub-optimal value or completely diverging.
Cost Function Requirement:
The Gradient Descent algorithm does not work for all the functions.
The cost function must be
- Differentiable
- Convex
Differentiable Function: A continuous function, whose derivative exists at all the points of the domain is known as a differentiable function.
Example:
- Polynomial function
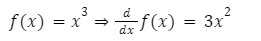
Basic Algebra of Differentiation:
If f(x) and g(x) are two differentiable function, then:
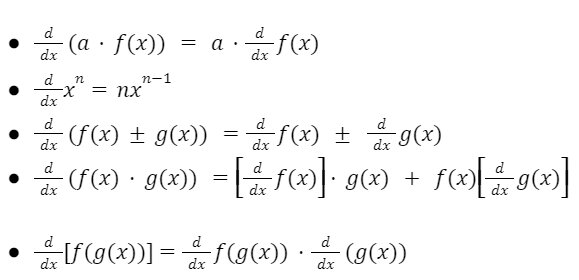
Convex Function:
Any function is convex if any line connecting two points of that function must lay on or above its curve but don’t intersect the curve.

Mathematical Method:


Gradient:
In simple terms, the gradient is the derivative of the function with respect to all the independent variables.
Note: When there is more than one independent variable in the function then,
Partial derivative is defined as the derivative of one variable and remaining as a constant.
Gradient for n-dimensional function f(x) at any point ‘a’ is given by:

Above we have seen the derivative of the univariate function (function having only one variable).
Now, let’s understand the gradient of more than one independent variable (partial derivatives) with an example.
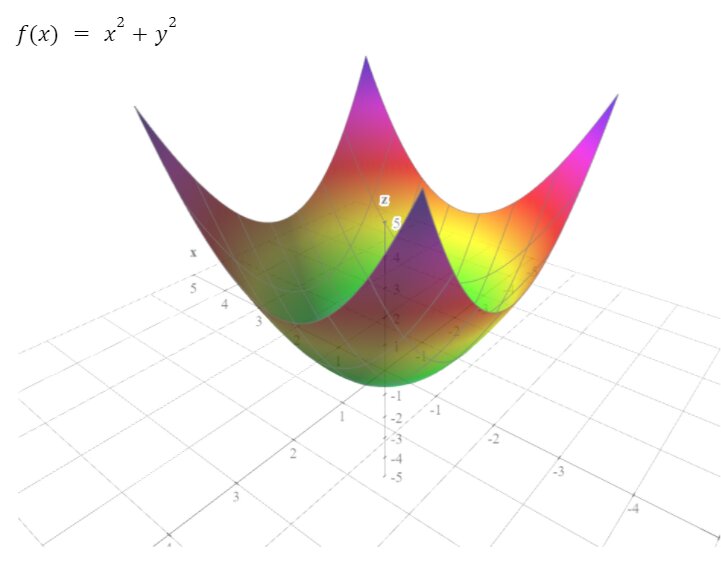

Now, finally, we come to the algorithm, Gradient Descent Algorithm.
Steps for Gradient Descent Algorithm:
- Define the cost function
- Choose the initial (starting) point
- Define learning rate
- Find the gradient of the cost function at this point
- Find the next point using:
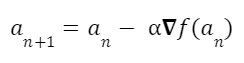
Repeat steps 4 and 5 till
- the Maximum number of iterations or
- Step size is smaller than the defined value.
Let’s understand the Gradient Descent by a simple example:
Example:
The cost function, initial point and learning rate are as:

Perform gradient descent for 5 iterations at both the learning rate.
Solution:
Firstly we will find the gradient (as it is a univariate function so simple differentiation)
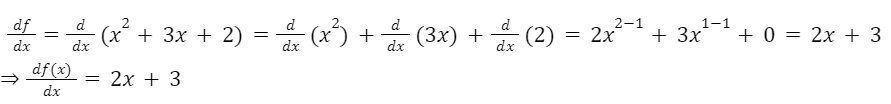
Now, for learning rate
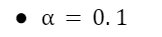
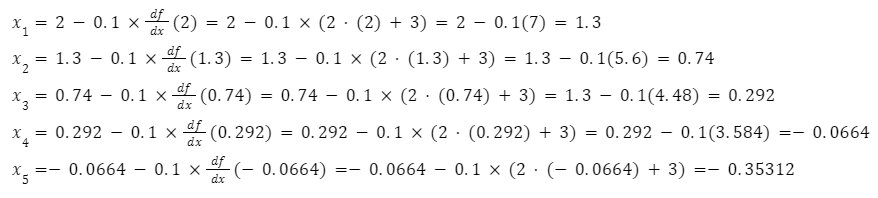

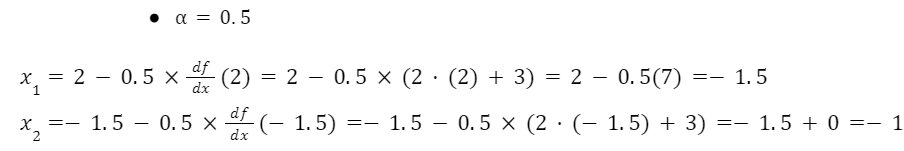

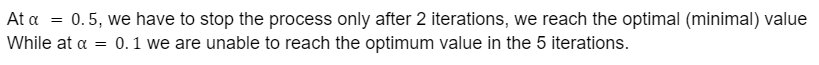
Conclusion:
In this article we briefly discussed about Gradient Descent in machine learning, one of the most useful optimization algorithm for linear regression.
Hope this article will help you in your Data Science and Machine Learning journey.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst

Comments