
Introduction to Recurrent neural networks and the Math behind them
Recurrent neural networks (RNNs) are a type of neural network that can process sequential data. They are particularly useful for tasks such as language translation and speech recognition, where the input data consists of a sequence of words or sounds.

Recurrent Neural Network (RNN) are deep learning algorithms with short-term memory created to deal with sequential data. This algorithm is commonly used in Google Search Suggestion, Apple voice search, Google Translate and many more. Main issue with the traditional feed forward network is its ability to remember the sequence of input fed to it. RNN was one of the first algorithm which was designed to remember the input in the internal memory. This ability of remembering the input makes RNN perfectly suitable for machine learning problems dealing with sequential data like stock market data, text streams, audio input, video streams, and other time-series based data.
In this post, we’ll cover the basic concepts of what a recurrent neural networks is, how does it work, what types of problem it can solve and where does it fail and why.
Table of Content
- What is Recurrent Neural Network
- Application of Recurrent Neural Network (RNN)
- Difference between RNN and Feed Forward Network
- How does Recurrent Neural Network Work?
- Different Types of RNN
- Backpropagation in RNN
- Issues with Recurrent Neural Network
- Conclusion
Let’s understand RNN with a simple example. Assume you are reading a book, while reading you do not sta rt your thinking from scratch every second. You are able to understand what’s written in a book because you are reading it in a proper sequence. Now let’s say you need to create a model which predicts the next word in the sentence. The main problem that you would face would be to understand the context of words being used and generate the next word on the basis of it. The machine needs to remember the order and context of the given words in order to predict the next. This order or sequence of input and remembering the context of previous word is something which lack in Traditional Neural Network and this is where Recurrent Neural Network comes into picture.

The concept of RNNs is not new. It was created way back in 1980s but its true potential has been uncovered recently. There were few limitation of RNN which are dealt with LSTM and GRUs, we will read more about it in the next blog.
What is RNN?
Recurrent neural networks (RNNs) are a type of neural network that can process sequential data, such as text, audio, or time series data. RNNs have a “memory” that allows them to remember information from previous time steps, which enables them to make predictions based on long-term dependencies in the data.
RNNs have a loop structure in which the output of the network at one time step is fed back into the network as input at the next time step. This allows the network to maintain a state that depends on the input it has seen so far, which enables it to process sequential data effectively.
While predicting the next word in a sentence the machine needs to remember the sequence of words in a sentence in order to give a proper context to it.
For example, “Let’s eat Grandpa” is much more different than “Let’s eat, Grandpa”
The traditional neural network cannot remember the previous word in a sentence as all the input and output are independent of each other. While predicting the next word in a sentence one needs to know which words came before it thus maintaining sequence of information is very important.
RNNs have been used for a wide variety of tasks, including language translation, speech recognition, and time series forecasting. They are particularly well-suited for handling variable-length input sequences, as they can continue processing the input until they reach the end of the sequence.
There are several variants of RNNs, including long short-term memory (LSTM) networks and gated recurrent unit (GRU) networks, which are designed to address some of the challenges of training traditional RNNs, such as the vanishing gradient problem.
A recurrent neural network, however, is able to remember those characters because of its internal memory. It produces output, copies that output and loops it back into the network.
Almost all of us have been using some or the other of the application of RNN. I am sure you all must have seen the google autocomplete feature which suggests you the searches related to your query.
Google Autocomplete Feature
How do you think Google’s Autocomplete feature work? Well, Google’s autocomplete feature uses a combination of techniques, including natural language processing and machine learning, to predict the most likely query a user will type based on the letters and words they have already typed.
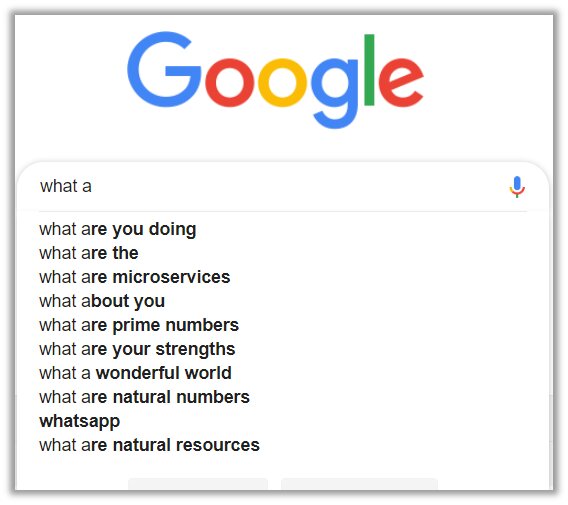
One approach that could be used to implement the autocomplete feature using a recurrent neural network (RNN) is to train the RNN on a large dataset of previous queries and their corresponding completions. The input to the RNN would be the prefix of the query that the user has typed so far, and the output would be the completion of the query.
During training, the RNN would learn to predict the most likely completion of the query based on the input prefix and the patterns it has learned from the training data. Once trained, the RNN could be used to generate completions for new queries in real-time as the user types.
Application of Recurrent Neural Network (RNN)
Recurrent neural networks (RNNs) are a type of neural network that are particularly well-suited for tasks that involve sequential data and the need to model dependencies over time. Here are some examples of the types of tasks that RNNs have been applied to:
- Language translation: RNNs are used to translate text from one language to another, such as Google Translate.
- Speech recognition: Transcribe and translate spoken language into written text, such as Apple’s Siri and Amazon’s Alexa.
- Time series forecasting: Predict future values in a time series, such as stock prices or weather data.
- Text generation: Generate text that is similar to a given input text, such as generating responses to a conversation or summarizing long documents.
- Sentiment analysis: Classify the sentiment of text, such as determining whether a review is positive or negative.
RNNs have also been applied to other tasks, such as music generation, predictive maintenance, and anomaly detection.
Let’s dive deep into how does a RNN work and how it differs from feed forward network
Difference between RNN and Feed Forward Network
RNN is a special type of feed forward network which contain a feedback loop that allows data to be stored back as the input for the next layer’s output. The traditional feed forward network lacks the internal state or memory and a forward travelling pattern; that is data from previous state cannot be saved. On the other hand, RNN uses a feedback loop for cycling through the data, allowing it to keep a track of both old and new information. Let us understand the difference between Recurrent Neural Network and Feed Forward Network in a tabular form.
| RNN | Feedforward Neural Network | |
|---|---|---|
| Structure | RNNs have a loop structure in which the output of the network at one time step is fed back into the network. | Feedforward neural networks have a linear structure, with the output of one layer serving as input to the next layer. |
| Input | RNNs can process sequential data, such as text, audio, or time series data. | Feedforward neural networks can process static data, such as images or tabular data. |
| Output | RNNs can produce a single output or a sequence of outputs, depending on the task. | Feedforward neural networks produce a single output. |
| Ability to handle dependencies | RNNs can handle long-term dependencies in the data by maintaining a state that depends on the input seen so far. | Feedforward neural networks cannot handle dependencies over time. |
| Training | RNNs can be difficult to train because of the complex structure and the need to backpropagate through time. | Feedforward neural networks are easier to train and converge faster than RNNs. |
Overall, RNNs are well-suited for tasks that involve sequential data and the need to model dependencies over time, such as language translation, speech recognition, and time series forecasting. Feedforward neural networks are better suited for tasks that involve static data, such as image classification and regression.
How does Recurrent Neural Network Work?
Here is a general overview of how an RNN works:
- The input to the RNN is a sequence of vectors, typically representing words or other units of the input data. The vectors are processed one at a time, starting from the first vector in the sequence.
- At each time step, the RNN processes the current input vector and the state from the previous time step to produce an output vector and a new state. The output vector can be used to make a prediction or perform some other task, depending on the specific application of the RNN.
- The new state is a combination of the input and output vectors at the current time step and the state from the previous time step. It is used to store information about the input sequence that has been processed so far and is used to inform the processing of the next input vector.
- The process is repeated until the end of the input sequence is reached. The final output of the RNN is the output at the final time step.
RNN is a type of feed forward network in which the input of one layer is served as the output to the next. In simple terms RNN has two inputs: the current input and the input from last layer. In the diagram below, the image on the left is a rolled back version of the image on the right.
Here Xt is the input layer, H is the hidden layer and Yt is the output layer at time t. The hidden layer H consist a feedback loop. The output of the layer is generated as Yt and the same output is stored back in the hidden layer to be passed on as input to the next layer. The image on right is the unrolled version of the model at different time step t1, t2, t3 and so on. Here X0, X1, X2, Xn represent the input at each time step. At each layer, RNN generates output and the same output is looped back into the network.

The input to an RNN cell at time step t is typically denoted as xt, and the hidden state at time step t is denoted as ht. The output at time step t is denoted as yt. The cell also has parameters, such as weights and biases, that are denoted as W and b, respectively.
Each hidden layer is function of two input Xt and Ht-1. The output Yt is a function of input from hidden layer(ht) at time t. These two functions are given by:
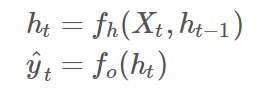
The input, output, and hidden state of an RNN cell are typically computed using the following equations:
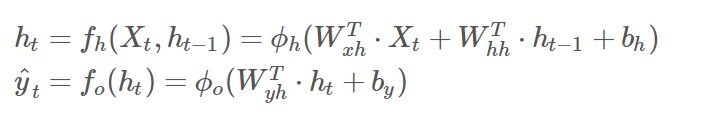
The hidden state at each time step is used to capture the context and dependencies in the data, and it is passed from one time step to the next, allowing the RNN to process the data in a time-dependent manner. This is what allows the RNN to capture patterns and dependencies in the data that span multiple time steps.
In the transition hidden layer function of ϕh is a nonlinear activation function, such as a sigmoid or tanh function. We are doing a dot product of weight with the input Xt and add it to weighted input from previous hidden layer along with bias. The weights and biases are learned during the training process to optimize the performance of the RNN.
ϕo is a non-linear activation function, such as softmax or Relu and is obtained by dot product of weight of output with hidden layer ht and adding bias to it.
Advantages of using RNN
Recurrent neural networks (RNNs) have several advantages that make them well-suited for certain tasks. Here are some key advantages of using RNNs:
- Process sequential data: RNNs are designed to process sequential data, such as time series data or natural language. They are able to take into account the context of previous inputs in the sequence when processing new data, which allows them to capture patterns and dependencies in the data.
- Handle variable-length input sequences: RNNs are able to handle input sequences of variable length, making them more flexible than other types of neural networks that require fixed-length inputs.
- Handle long-term dependencies: RNNs are able to capture long-term dependencies in data, which makes them well-suited for tasks that require a model to consider information from a long time ago.
- Efficient at processing large datasets: RNNs can process large datasets efficiently, making them a good choice for tasks that require handling a large amount of data.
Different Types of RNN
RNN – ONE to ONE
A one-to-one recurrent neural network (RNN) is a type of RNN that maps a single input to a single output. This type of RNN is also known as a “vanilla” RNN or a “fully connected” RNN.
- A one-to-one RNN is a type of RNN that maps a single input to a single output.
- The input to a one-to-one RNN is a fixed-length sequence of vectors, and the output is also a fixed-length sequence of vectors.
- The network processes the input sequence one time step at a time, using the output of the network at one time step as input to the next time step.
- One-to-one RNNs are well-suited for tasks that involve mapping a fixed-length input sequence to a fixed-length output sequence, such as language translation or speech recognition.
- They are not well-suited for tasks that require the network to process variable-length input sequences, such as machine translation or summarization.
- Applications: Text generation, Word Prediction, Sentence Prediction, Stock market predictions
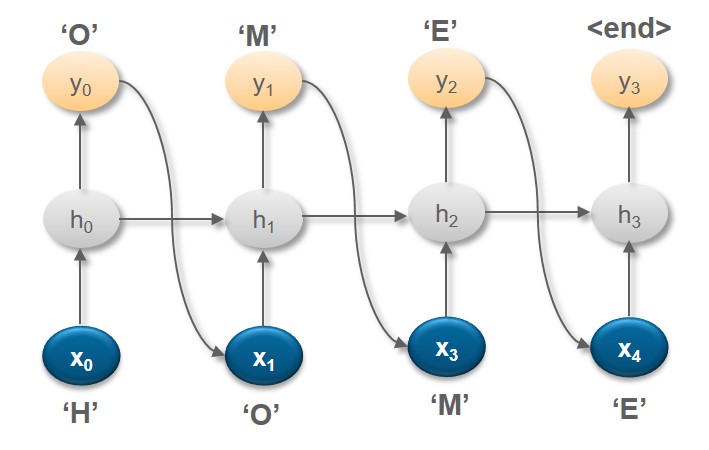
Here, the corpus contains four characters H, O, M, E when the character H is fed as an input, RNN computes the probability of all words in the vocabulary to predict the next letter.
RNN – ONE to MANY
A one-to-many recurrent neural network (RNN) is a type of RNN that maps a single input to a sequence of outputs. This type of RNN is well-suited for tasks that involve generating a sequence of outputs based on a single input, such as image captioning or music generation.
- A one-to-many RNN takes a single input and produces a sequence of outputs.
- The input to a one-to-many RNN is typically a fixed-length vector, such as an image or a piece of text.
- The output of a one-to-many RNN is a sequence of vectors, such as a sequence of words or notes.
- One-to-many RNNs are often used for tasks that involve generating text or other types of sequential data based on a single input.
- They can be more complex to train than one-to-one RNNs, which map a single input to a single output.
- In the below example, same image is passed as input to different layers. Here ‘cat’ predicted at time step t0 is used in the next time step t1 , previous hidden state h0 is used to predict the next word which is ‘is’
- Application: Auto Image captioning
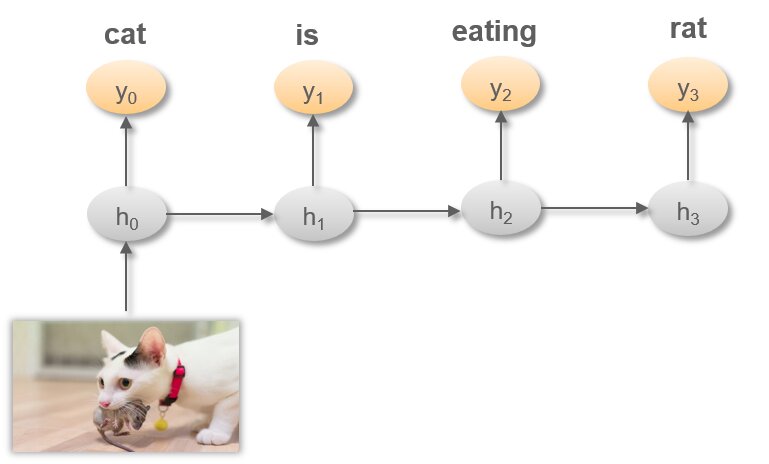
RNN – MANY to ONE
A many-to-one recurrent neural network (RNN) is a type of RNN that maps a sequence of inputs to a single output. This type of RNN is well-suited for tasks that involve processing a sequence of inputs and producing a single output, such as sentiment analysis or language translation.
Here are some key points about many-to-one RNNs:
- A many-to-one RNN takes a sequence of inputs and produces a single output.
- The input to a many-to-one RNN is typically a sequence of vectors, such as a sequence of words or time series data.
- The output of a many-to-one RNN is a single vector, such as a classification label or a numerical prediction.
- Many-to-one RNNs are often used for tasks that involve classifying or predicting based on a sequence of inputs.
- They can be simpler to train than many-to-many RNNs, which map a sequence of inputs to a sequence of outputs.
- At each time step t, single word is passed as input along with the previous hidden state and finally model predicts the sentiment of the sentence (positive or negative)
- Application: Sentiment Analysis
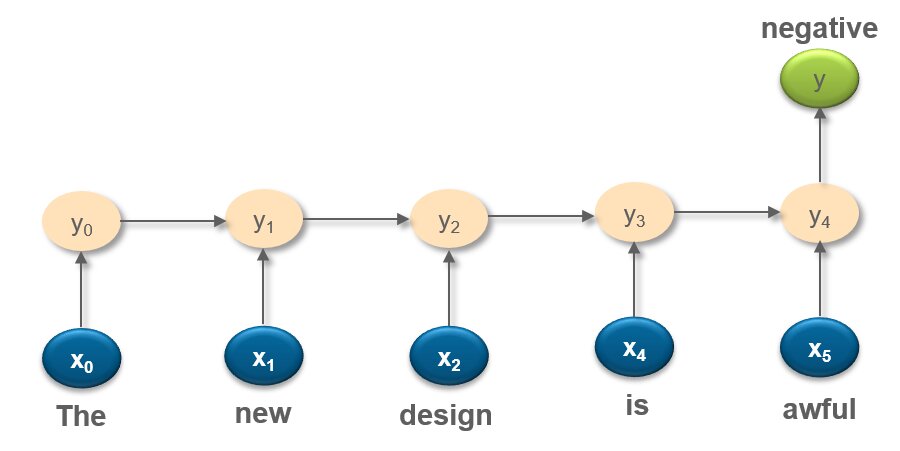
RNN – MANY to MANY
A many-to-many recurrent neural network (RNN) is a type of RNN that maps a sequence of inputs to a sequence of outputs. This type of RNN is well-suited for tasks that involve processing a sequence of inputs and producing a sequence of outputs, such as machine translation or summarization.
Here are some key points about many-to-many RNNs:
- A many-to-many RNN takes a sequence of inputs and produces a sequence of outputs.
- The input to a many-to-many RNN is typically a sequence of vectors, such as a sequence of words or time series data.
- The output of a many-to-many RNN is also a sequence of vectors, such as a sequence of words or notes.
- Many-to-many RNNs are often used for tasks that involve translating or summarizing a sequence of inputs.
- They can be more complex to train than many-to-one RNNs, which map a sequence of inputs to a single output.
- Consider the sentence from Spanish ‘casa de papel’ to English which means ‘paper house’
- Application: Machine Translation, Text Summarization
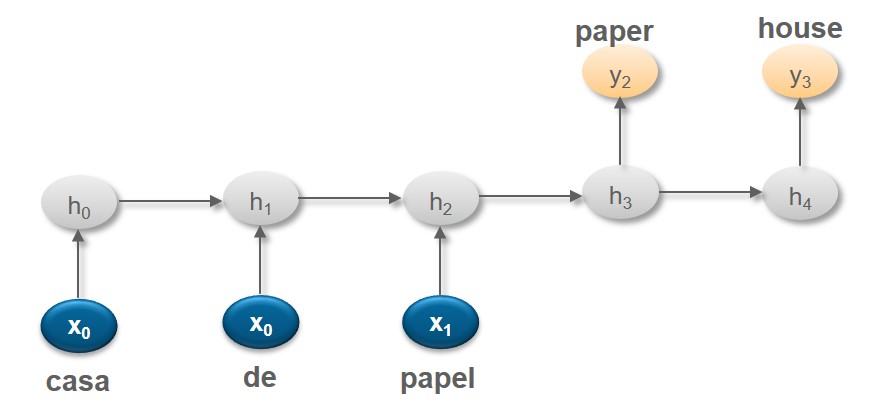
Backpropagation in RNN
In a neural network, the forward-propagation lets you get the output of the model with a certain accuracy. Backpropagation is the same but in a backward direction. It goes back updating weights (gradient) of each node to reduce the error. The partial derivative of the error w.r.t weight is calculated and is subtracted from the weights. Applying this backpropagation in RNNs is called backpropagation
Backpropagation is an algorithm used to train neural networks, including recurrent neural networks (RNNs). It involves calculating the gradient of the loss function with respect to the network’s weights, and using this gradient to update the weights in a way that reduces the loss.
In a RNN, the gradient of the loss function is calculated using the chain rule of differentiation, which allows the gradient to be backpropagated through time. This is necessary because the output of the RNN at each time step depends on the inputs and outputs at all previous time steps.
To perform backpropagation in a RNN, the gradient of the loss function is first calculated with respect to the output of the network at the final time step. This gradient is then used to calculate the gradients at the previous time steps, and so on, until the gradients at all time steps have been calculated. These gradients are then used to update the weights of the network.
Backpropagation is an important algorithm for training RNNs, as it allows the network to learn from sequential data by adjusting its weights based on the errors it makes when predicting the outputs. It is a key component of many popular optimization algorithms, such as stochastic gradient descent and Adam.
Summarizing How Backpropagation works in RNN:
- Initialize the weights of the network randomly.
- Feed the input sequence into the network and forward propagate to calculate the output at each time step.
- Calculate the error between the predicted output and the true output at the final time step.
- Calculate the gradient of the loss function with respect to the output at the final time step.
- Backpropagate the gradient through the network, using the chain rule of differentiation to calculate the gradients at each previous time step.
- Update the weights of the network using the calculated gradients.
- Repeat the above steps until the loss is minimized or a stopping criterion is reached.
Backpropagation Through Time (BPTT) in RNN
Backpropagation through time (BPTT) is an algorithm that is used to train recurrent neural networks (RNNs) by calculating the gradients of the network’s parameters with respect to the loss function and using these gradients to update the parameters.
Here are some key points about BPTT in RNNs:
- BPTT is an extension of the backpropagation algorithm that is used to train feedforward neural networks.
- It is used to train RNNs by unrolling the loop structure of the RNN and treating it as a feedforward neural network with many layers.
- The gradients of the network’s parameters are then calculated using backpropagation, which involves propagating the error signal backwards through the unrolled network and updating the weights at each time step.
- BPTT can be computationally intensive and may require a large amount of memory, particularly for long sequences or deep networks.
- There are several variations of BPTT, such as truncated BPTT and online BPTT, which aim to reduce the computational complexity and memory requirements of the algorithm.
- BPTT is an important tool for training RNNs, but it can be difficult to implement and may suffer from the vanishing or exploding gradient problem. Alternative algorithms, such as the hybrid approach and the real-time recurrent learning (RTRL) algorithm, have been proposed to address these issues.
Issues with Recurrent Neural Network
- Exploding gradient problem: This occurs when the gradients of the parameters of the network become too large, leading to unstable and rapidly increasing values.
- Vanishing gradient problem: This occurs when the gradients of the parameters of the network become very small, leading to slow or stagnant learning.
- Training instability: RNNs can be difficult to train because they have a complex structure and depend on the input at all previous time steps. This can make the training process unstable, and the network may not converge to a good solution.
- Overfitting: RNNs can be prone to overfitting, especially when working with small datasets. This can lead to poor generalization to new data.
- Long training times: Training RNNs can be computationally intensive, especially for large datasets or when using deep networks. This can lead to long training times, which can be a drawback.
- Difficulty in parallelizing: RNNs are typically trained sequentially, meaning that the output at one time step must be calculated before the input at the next time step can be processed. This makes it difficult to parallelize the training process, which can be inefficient.
Despite these issues, RNNs can be very powerful and have been used to achieve state-of-the-art results on a wide variety of tasks, including language translation, speech recognition, and time series forecasting.
Exploding Gradient Problem
The exploding gradient problem is a problem that can occur when training deep neural networks, including recurrent neural networks (RNNs). It occurs when the gradients of the parameters of the network become too large, leading to unstable and rapidly increasing values. This can cause the parameters of the network to become very large, resulting in poor generalization and performance.

The exploding gradient problem is often caused by the use of very deep networks, or by the use of activation functions that have large output ranges, such as the hyperbolic tangent function. It can also be caused by the use of large learning rates, which can cause the gradients to become very large.
To address the exploding gradient problem, there are several techniques that can be used, such as gradient clipping and weight normalization. Gradient clipping involves setting a threshold for the maximum value of the gradients and scaling down the gradients if they exceed this threshold. Weight normalization involves normalizing the weights of the network to prevent them from becoming too large.
Another approach to addressing the exploding gradient problem is to use alternative optimization algorithms, such as Adam or RMSProp, which can help stabilize the gradients and prevent them from becoming too large.
Summarizing Exploding Gradient Descent
- The exploding gradient problem is caused by the gradients of the network’s parameters becoming very large during training.
- This can occur when the network has many layers and/or the gradients are not properly controlled during training.
- The exploding gradient problem can lead to unstable training and poor generalization to new data.
- It can be difficult to diagnose the exploding gradient problem, as it can occur even when the loss function is still decreasing.
- There are several ways to address the exploding gradient problem, including using techniques such as gradient clipping and weight normalization, and using architectures such as long short-term memory (LSTM) networks and gated recurrent unit (GRU) networks that are less prone to the problem.
Vanishing Gradient Problem
The vanishing gradient problem is a problem that can occur when training deep neural networks, including recurrent neural networks (RNNs), using gradient-based optimization algorithms such as stochastic gradient descent (SGD). It occurs when the gradients of the parameters of the network become very small, leading to slow or stalled learning. This can cause the parameters of the network to change very slowly, resulting in poor generalization and performance.
The vanishing gradient problem is often caused by the use of very deep networks, or by the use of activation functions that have small output ranges, such as the sigmoid function. It can also be caused by the use of small learning rates, which can cause the gradients to become very small.
To address the vanishing gradient problem, there are several techniques that can be used, such as using alternative activation functions, such as the ReLU function, which has a larger output range and does not saturate for positive inputs. Another approach is to use alternative optimization algorithms, such as Adam or RMSProp, which can help stabilize the gradients and prevent them from becoming too small.
Long short-term memory (LSTM) networks and gated recurrent unit (GRU) networks are variants of RNNs that have been designed specifically to address the vanishing gradient problem by introducing gating mechanisms that allow the network to selectively store and access information from previous time steps. These mechanisms can help the network maintain long-term dependencies and prevent the gradients from vanishing.
Summarizing Vanishing Gradient Problem
- The vanishing gradient problem is caused by the gradients of the network’s parameters becoming very small during training.
- This can occur when the network has many layers and/or the activation functions used in the network have a saturation region, such as the sigmoid function.
- The vanishing gradient problem can make it difficult for the network to learn and improve, leading to poor performance on the training task.
- It can be difficult to diagnose the vanishing gradient problem, as it can occur even when the loss function is still decreasing.
- There are several ways to address the vanishing gradient problem, including using activation functions that do not have a saturation region, such as the ReLU function, and using architectures such as long short-term memory (LSTM) networks and gated recurrent unit (GRU) networks that are less prone to the problem.
Conclusion
In conclusion, recurrent neural networks (RNNs) are a powerful tool for processing sequential data and modeling dependencies over time. They have been applied to a wide range of tasks, including language translation, speech recognition, time series forecasting, text generation, and sentiment analysis. RNNs have a loop structure in which the output of the network at one time step is fed back into the network as input at the next time step, allowing the network to maintain a state that depends on the input it has seen so far. There are several types of RNNs, including one-to-one, one-to-many, many-to-one, and many-to-many, which are well-suited for different types of tasks. RNNs can be more difficult to train than other types of neural networks due to the complexity of the loop structure and the need to backpropagate through time, but they have been shown to achieve state-of-the-art results on many tasks.
FAQs
What is an RNN?
An RNN is a type of neural network designed to process sequential data, such as language or speech.
How does an RNN work?
An RNN processes sequential data by using the output from one time step as input for the next time step. This allows the network to retain information about the context of the input data and make decisions based on that context.
What are the different types of RNNs?
There are several types of RNNs, including Elman networks, Jordan networks, long short-term memory (LSTM) networks, and gated recurrent units (GRUs). Apart from these there is another category of one to one RNN, one to many RNN, many to one RNN, and many to many RNN
How is an RNN trained?
RNNs can be trained using various methods, such as backpropagation through time or the more recent transformer architecture. The goal is to adjust the network's weights and biases in such a way that it can accurately process and generate the desired output for a given input.
What are some common applications of RNNs?
Some common applications of RNNs include language translation, speech recognition, and natural language processing. They are also used in tasks such as time series prediction and machine translation.
What are the advantages of using an RNN?
RNNs are particularly good at processing sequential data and can retain information about the context of the input data. They are also useful for tasks that involve variable-length input sequences.
What are the limitations of RNNs?
One limitation of RNNs is that they can be computationally intensive, especially for tasks with long input sequences. They can also be difficult to train and may require a large amount of data to achieve good performance.
Can RNNs be used for supervised learning tasks?
Yes, RNNs can be used for supervised learning tasks, such as classification and regression. In these tasks, the network is trained to predict a label or value based on the input data.
Can RNNs be used for unsupervised learning tasks?
Yes, RNNs can also be used for unsupervised learning tasks, such as clustering and dimensionality reduction. In these tasks, the network is not given any labeled data and must learn to discover patterns and relationships in the input data on its own.
Are there any variations of RNNs?
Yes, there are several variations of RNNs, including long short-term memory (LSTM) networks and gated recurrent units (GRUs). These variations are designed to overcome the limitations of vanishing gradient and exploding gradient in traditional RNNs and are particularly useful for tasks with long input sequences.
