
Introduction to Web Scraping using R
Standing in today’s world where we are now talking about the 3rd generation of the web (web3.0) we do not need to introduce what is Web. In short, the web is everywhere. Our lives, our economies our work our health everything is not dependent on this three-letter word.

In this article on web scraping, we will discuss about the concept, its importance, process flow, usage and application. Let us get started:
Table of Contents
What is Web Scraping?
The word “web-scraping” is formed by two components. Web and Scrape. Let us now understand what is scrape. Oxford dictionary defines Scrape as “to remove something from a surface by moving something sharp and hard like a knife across it” (Dictionary, n.d.). while this may sound a little off the track, web scraping in simple terms, is just collecting information from the web. It’s like extracting information, probably with a sharp knife by hovering around the different websites.
Technically, web scraping is the automated process of gathering unstructured information across the different websites of your choice and then converting those into a structured form so that further analysis can be done based on the information from the web.

There can be a few options for collecting data from a website.
- Manual copy-pasting: You go to a website, look for the specific sections (customer reviews on Amazon or historic information in Wikipedia) and then collect information and paste them into your document.
- API Interface: Before understanding API parsing, let us try to have some idea of what exactly is meant by API. API is the acronym for Application Programming Interface. Broadly speaking, an API is nothing but a set of rules that let two different software talk in between them. Websites like Twitter, Facebook, and so on provide access to different APIs which can be used for retrieving the data in the desired shape and format. Web scraping through API is a very common and one of the most used processes as well these days.
- Web scraping using computer programs: This is the part where we are most interested as we will implement a small project through this process. By using computer programs and already established open source packages in R or Python, we can visit a web page and extract all the required information from there through CSS or HTML formats. Once the information is extracted the packages also provide programs that can be used to clean and transform the data into the desired shape and format. Additional text mining packages can also be explored for a different set of ETL tasks.
Explore free R courses
Need for Web Scraping
Imagine a situation where you are the owner of a boutique firm that sells a lot of apparel items on Amazon. On some days you get good reviews of your products and on some days you get very bad ones too. There is a mix of customer ratings too. Some people rate your products and delivery very high whereas few of them do not like your product or service at all.
In today’s world, where e-commerce is the new form of commerce, understanding customers’ thoughts are very important for survival. In simple terms, you as a business owner should have very clear views of what customers are saying about your products. Are they good, bad, are they likening not likening, and so on. Based on these reviews you may devise new strategies, develop new products offer more services, and so on.
The question is how do you get access to tons of reviews and feedback in an automated way? The answer to that lies in the concept of web scraping. In today’s blog, we will introduce the concept of web scraping. We will first make ourselves familiarized with what exactly web scraping means and then, later on, we will try to understand a few of the applications and finally, we will end our discussion with a short real-world implementation of web scraping using R.
Process flow of Web Scraping
Let us now briefly understand how a web scraping program works in real life through the very simple process flow chart below.

The above flowchart describes the process of web scraping in few broad steps.
First the program is written and initiated. After that the URL of the web page from where the information need to be extracted is provided in the program. The program then extracts all the desired information from the web page(s) and finally this information is converted to the proper structural format.
The below picture is also a pictorial representation of the web scraping process.

Usage and Applications of Web Scraping
Let us now focus on some of the usages of Web scraping.
- E-commerce review analysis: As we stated at the very beginning of our discussion here, web scraping technology is widely used to extract customer feedback and reviews from different e-commerce websites. This gives the product and service perception of the seller in one go. This also showcases the overall sentiment and talked about points for the products under the shelf in the e-commerce portal. In summary, getting access to the entire customer feedback and then having those results in the processed and insightful format is nothing short of a gold mine for a business owner and web scraping helps that to a great extent.
- Recommendation engine creation: A lot of times web scraping finds its applications in creating movie recommendation engines as well. The different online movie databases like IMDB are scraped for different genres and ratings and based on that a database of different genres, ratings, forms, language, duration, and sentiment can be created. Based on these processed tables a movie watcher is provided recommendations on OTT streaming platforms.
- Lead generation for marketing: Web scraping technology is also used to extract customer information and contact details from various websites and these contacts details in turn are then used for cold callings, push marketing, and so on
- Application in social media: Web scraping is extensively used in social media data extraction for different text mining and analysis. For example, social media feeds and comments are extracted and analyzed to understand what people are talking about. Political parties do a lot of social media campaigns before the election. The web scraping tools help in understanding what is the overall sentiment going on; how people are discussing and debating various issues on social media. The political campaigns are then tailor-made depending on the social media analytics.
- Training of deep learning process: web scraping is also used to extract text data from different sources like Wikipedia; to train complicated neural network deep learning models on topic modeling, sentiment mining, and so on. Web scraping works as a handy tool for the creation of the training data sets for these sophisticated machine learning models.


 Read Later
Read Later

Application and code development of Web scraping in R
Let us now see how a web scraping tool is developed to access amazon’s customer reviews and how additional text mining packages help in extracting valuable information from the scraped data.
We will use R’s rvest package for the data extraction and transformation. Python also has a wonderful web scraping library called “Beautifulsoup”.
Learn more about web scraping in Python
Step1: load the tidyverse and rvest packages as they would be required to extract and transform the data.
library(tidyverse)library(rvest)
Step 2: In this step, we need to find out the ASIN number. this number is very much amazon specific and it stands for Amazon Standard Identification Number. Essentially this is nothing but a product id. So, for different websites, this number would be different. The AISN is a long string made up of 10 unique characters.
In this step, we will also define a function that will read the reviews from the Amazon web page.
## Define a function that will read the reviews from amazon:scrape_amazon <- function(ASIN, page_num){ url_reviews <- paste0("https://www.amazon.in/product-reviews/",ASIN,"/?pageNumber=",page_num) doc <- read_html(url_reviews) # Assign results to `doc` # Review Title doc %>% html_nodes("[class='a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold']") %>% html_text() -> review_title # Review Text doc %>% html_nodes("[class='a-size-base review-text review-text-content']") %>% html_text() -> review_text # Number of stars in review doc %>% html_nodes("[data-hook='review-star-rating']") %>% html_text() -> review_star # Return a tibble tibble(review_title, review_text, review_star, page = page_num) %>% return()}
The function above defined as scrape_amazon() connects to the provided URL. The read_html() function reads the Html content from the given URL.
After that, once we have read all the Html content, we are segregating the review title, the actual reviews, and the star ratings into three different parts and then form a final structured tiblle that contains all three of them.
Now, this function works only for one page of the website. Imagine we run this function under a loop and then extract all the information one after the other and then keep on adding sequentially. This would result in the extraction of all the reviews and feedback.
Effectively, that is what we are doing in our next step.
Step 3:
This piece of code now runs in loop for every page number in the range and then it extracts the required information from all the pages and adds to a final tibble.
## Read all the reviews for 10 pages:
ASIN <- "B096KPW7ZV" # Specify ASINpage_range <- 1:10 # Let's say we want to scrape pages 1 to 10
# Create a table that scrambles page numbers using `sample()`# For randomising page reads!match_key <- tibble(n = page_range, key = sample(page_range,length(page_range)))
lapply(page_range, function(i){ j <- match_key[match_key$n==i,]$key message("Getting page ",i, " of ",length(page_range), "; Actual: page ",j) # Progress bar } scrape_amazon(ASIN = ASIN, page_num = j) # Scrape}) -> output_list
The final output of this code run looks like below:

Where we have all the information across the 10 different pages stored in 10 different lists. Each list contains information on review title, text, star rating, and so on.
In the next and final step, we are only going to consider the review text part and create a word cloud diagram out of it.
Step 4:
In this step, we will try to visualize the customer reviews. For our example, we have chosen a skin care product from amazon.in called “Wow Skin Science Retinol Cream”.
Let us also see what the product looks like.

More details on the product can be found at the website.
We are now going to create a word cloud to understand what customers are buzzing around about this specific product.
The code for this is as below:
library(tidytext)library(wordcloud)
output_list %>% bind_rows() %>% unnest_tokens(output = "word", input = "review_text", token = "words") %>% count(word) %>% filter(!(word %in% c("book","books"))) %>% anti_join(tidytext::stop_words, by = "word") -> word_tb
wordcloud::wordcloud(words = word_tb$word, freq = word_tb$n)
The word cloud which gets generated as an output of the above code looks is presented below:
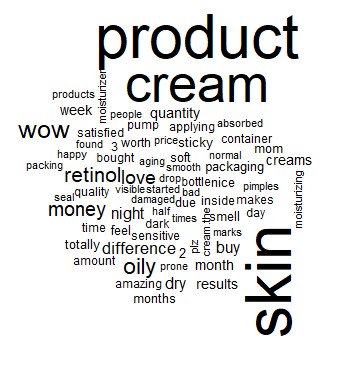
People are talking about the product and the cream. Just looking at a glance we can find words like “totally”, “wow”, “happy”, love”,”satisfied”,”amazing” and so on. This helps us understand that people are overall satisfied with this product.
A detailed analysis using advanced text mining approaches can be further performed to understand the overall sentiment, different topic points of discussion, and so on. However, in our today’s discussion, we will end our technical part here only.
End notes:
In this article, we have tried to understand the background and context of how exactly a web scraping tool can be built in R and also how web scraping works in the real world. We have also seen how unstructured data from different web pages can be finally converted into the structural form using web scraping and then how meaningful visualization can be created for better understanding and business decision-making. Hope this would help give an introduction to web scraping. As most of the data on the web is present in an unstructured format, web scraping is a really handy skill for any data scientist.
Recently completed any professional course/certification from the market? Tell us what liked or disliked in the course for more curated content.
Click here to submit its review with Shiksha Online.
