
Linear Regression in Machine Learning
Linear regression in machine learning helps you find patterns and relationships in data and make an educated decision or prediction. The article discusses using linear regression to model a linear relationship between features in your data. Let's understand this concept in detail!

Linear regression is a type of supervised machine learning algorithm used to predict a continuous numerical value. It is a linear approach to modeling the relationship between a dependent variable (the variable being predicted) and one or more independent variables (the variables used to predict the dependent variable).
In a linear regression model, the predicted value is calculated as a linear combination of the input features, with each feature weight representing the influence of that feature on the target. The goal of the model is to find the optimal values for the feature weights that minimize the prediction error.

We all have noticed that as winter approaches, jacket sales increase. Multiple factors might affect the sales number. A clothing company wants to understand what it should do to increase its sales and thereby improve its profit.

This is a type of scenario where we can use linear regression to predict the sales and profit for a given quarter. In real life 100’s of variables like time of year, daily temperature, number of people visiting an outlet, number of outlet, etc. All of these variables somehow affect the sales. Up-to what extent it effects or how are they going to effect the sales we don’t know for now. This is where Linear Regression comes into picture. For simplicity, in this blog we will use one of the variable to understand how it effects the sales variable.
In this blog we will cover the following sections:
Overview of Linear Regression Algorithm
Linear Regression – Linear refers to line and regression refers to relation in continuous variable. On a very high level, Linear regression tells about the relation between dependent and independent variable with the help of a straight line. This straight line of regression is fitted among the data to predict the new data points based on the existing data.
Using linear regression we answer, “What is the expected or predicted value of dependent variable for a given independent variable”.
For example, sale of jacket increases during the winters.
| S.No | Number of Jackets Sold (Y) | Daily Temperature (X) |
|---|---|---|
| 1 | 1000 | 10 |
| 2 | 2000 | 5 |
| 3 | 2500 | 0 |
| 4 | 2200 | 4 |
| 5 | 100 | 40 |
| 6 | 500 | 30 |
From the given data you need to answer,
“How many jackets were sold when the temperature was 15 degree Celsius”.
Here, the number of jackets sold is dependent on the temperature and weather condition (independent variable). As the temperature decreases sale of jacket increase. This means jacket’s sale has negative relation with the temperature.
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
What is Linear Regression?
Linear regression models a linear relationship with a line of regression or regression line between two or more continuous variables. In simple linear regression, we consider two variables:
- Independent Variable (X): Features or variables which might be affecting the dependent variable (temperature)
- Dependent Variable (y): The variable which we want to predict (sale)
Goal: Find a equation of a straight line which will use the dependent variable to predict the value of independent variable with maximum accuracy or minimum error (difference between actual and predicted value).
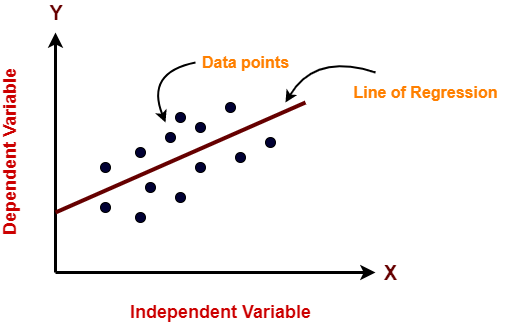
“For a given value of X what will be the predicted value of y?”
I am sure in your elementary Math class, you must have read about straight line equation, calculating distance between two points in cordinate, finding slope and intercept of a line, etc. In simple linear regression we will be using these simple concepts to understand how we find the the equation of a linear regression line for prediction.
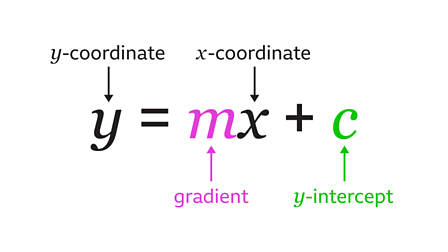
Here,
- y = Dependent variable which we are trying to predict
- x = Independent variable which might be affecting y
- m = slope
- c = y-intercept
These are also called the Regression Coefficients.

Types of Linear Regression
There are several types of linear regression, including:
- Simple linear regression: This involves modeling the relationship between a single input variable (explanatory variable) and a single output variable (response variable). The model is represented by a straight line, and the goal is to find the line that best fits the data.
- Multiple linear regression: This involves modeling the relationship between multiple input variables and a single output variable. The model is represented by a straight line, and the goal is to find the line that best fits the data.
- Polynomial regression: This involves modeling the relationship between an input variable and an output variable using a polynomial function. The model is represented by a curve, and the goal is to find the curve that best fits the data.
- Logistic regression: This is a type of regression used when the output variable is binary (e.g., 0 or 1, Yes or No). The model is used to predict the probability that a given input belongs to one of the two categories.
- Ridge regression: This is a variation of multiple linear regression that adds a penalty term to the objective function to discourage the model from overfitting the data.
- Lasso regression: This is another variation of multiple linear regression that adds a penalty term to the objective function to discourage the model from overfitting the data. Unlike ridge regression, lasso regression can zero out some of the coefficients, effectively removing some of the input variables from the model.
Finding the Best Fit Line
The goal is the to find the best fit line which passes through all the points with minimum difference between the actual value and the predicted value (error). This line will be used to predict the value of the dependent variable y for any new value of X.

In order to find the best fit line you need to get a best equation of line. This best equation of line can be figured through the most optimized value of both slope (m) and intercept (c).
- How to find the value of m and c?
- How to conclude if the model created is of good fit?
- How to optimize the model if the prediction is not so good?
Let’s try to answer these questions one by one:
How to find the value of slope and intercept of the Regression Line?
In linear regression, the slope and intercept are the parameters of the model that define the linear relationship between the dependent variable (the variable being predicted) and the independent variable(s) (the variable(s) used to predict the dependent variable). The goal of linear regression is to find the optimal values for the slope and intercept that minimize the prediction error.
There are several ways to find the optimal values for the slope and intercept in linear regression, including the following:
- Analytical solution: The optimal values for the slope and intercept can be found analytically by minimizing the sum of the squared residuals (the difference between the predicted values and the actual values). This involves solving a system of linear equations and is also known as Least Square Method.
- Gradient descent: Gradient descent is an optimization algorithm that is used to find the optimal values for the parameters of a machine learning model. It works by adjusting the values of the parameters in the direction that minimizes the cost function (in this case, the sum of the squared residuals). Gradient descent is an iterative process, and it requires the calculation of the gradient (the partial derivative of the cost function with respect to each parameter) at each iteration.
- Stochastic gradient descent (SGD): Stochastic gradient descent is a variant of gradient descent that is used to optimize machine learning models. It works by randomly selecting a single data point from the training set at each iteration and adjusting the model parameters based on the error for that data point. SGD is generally faster and more efficient than batch gradient descent (the standard variant of gradient descent), but it can also be less stable and may require more careful hyperparameter tuning.
In the context of linear regression, the least squares method and gradient descent are both used to find the optimal values for the slope and intercept that minimize the prediction error. The least squares method is a closed-form solution that can be solved analytically, while gradient descent is an iterative optimization algorithm. SGD can also be used to optimize linear regression models, although it is more commonly used with more complex models such as neural networks.
In practice, most machine learning libraries, such as scikit-learn in Python, implement linear regression using an analytical solution or the normal equation, so you do not need to worry about implementing these algorithms yourself. Simply fit the model to your training data using the fit() method and the optimal values for the slope and intercept will be found automatically.
Here is an example of fitting a linear regression model in Python using scikit-learn:
from sklearn.linear_model import LinearRegression
# create a linear regression modelmodel = LinearRegression()
# fit the model to the training datamodel.fit(X_train, y_train)
After fitting the model, you can access the optimal values for the slope and intercept using the coef_ and intercept_ attributes, respectively.
# get the optimal values for the slope and interceptslope = model.coef_intercept = model.intercept_
In this blog we will focus on Least Square Method in detail.
Let’s understand this through a little example – You wish to predict the salary a person would draw based on the years of experience they have.
As the years of experience (x) increase, so does the salary (y). We can plot the data for better visual understanding:

Our goal is to find a straight line that best fits our plot.

As a mathematical convention, we’ll rewrite our linear equation as:

Where, β0 and β1 are Model’s Coefficients or Parameters.
To find the best fit line for our data, we need to find the values of parameters β0 and β1 (y-intercept and slope) that minimize the distance between the estimated values (ŷᵢ) of the model and the actual values (yᵢ) in our data.
The distance is actually the error or the residual, and can be visualized as shown:

One way to find the best fit line is to minimize the Mean Squared Error (MSE).
Mean Squared Error
Mean squared error (MSE) is a measure of the average squared difference between the predicted values and the actual values in a dataset. It is commonly used to evaluate the performance of a machine learning model, particularly in regression problems where the goal is to predict a continuous numerical value.
To calculate MSE, you first need to calculate the squared difference between the predicted values and the actual values for each data point in the dataset. Then, you take the average of these squared differences. The result is the MSE.
Here is an example of how to calculate MSE in Python using the numpy library:
import numpy as np
# calculate the squared differencessquared_differences = (y_pred - y_true) ** 2
# calculate the mean squared errormse = np.mean(squared_differences)
MSE is a useful metric because it penalizes large errors more heavily than small errors, which is often desirable in regression problems. However, MSE has the disadvantage of being sensitive to the scale of the data, so it is important to scale the data before evaluating the model using MSE.
A low MSE indicates that the model is making accurate predictions, while a high MSE indicates that the model is not making accurate predictions. In general, you want to minimize the MSE to improve the performance of the model.
R-Squared
In linear regression, the coefficient of determination, also known as R-squared, is a statistical measure that represents the proportion of the variance in the dependent variable that is explained by the independent variables. It ranges from 0 to 1, where a value of 0 means that the model does not explain any of the variance in the dependent variable, and a value of 1 means that the model explains all of the variance.
R-squared is calculated as the ratio of the sum of the squared residuals of the model (the difference between the predicted values and the actual values) to the total sum of squares of the dependent variable (the variance in the dependent variable). A higher R-squared value indicates a better fit of the model to the data.
Here is an example of how to calculate R-squared in Python using the scikit-learn library:
from sklearn.metrics import r2_score
# calculate the R-squared score for the modelr2 = r2_score(y_true, y_pred)
It is important to note that R-squared is only a measure of the strength of the relationship between the dependent and independent variables, and it does not necessarily imply that the model is a good fit for the data. There may be other factors that contribute to the variance in the dependent variable that are not captured by the model. It is always a good idea to evaluate the model using multiple metrics and to examine the residuals to ensure that the model is a good fit for the data.
Building a Simple Linear Regression Model
Step 1 – Load the data and check for null values
Step 2 – Split the dataset for training and testing
Step 3 – Let’s implement linear regression model without using Scikit-learn
Step 4 – Let’s perform prediction on test data using our model
Step 5 – Let’s evaluate our model on test data
Step 6 – Train the model for prediction using Scikit-learn Library
Step 7 – Predict the salary on test data
Step 8 – Evaluate the sklearn linear regression model using R2 score and mean squared error
Now that we know how to find the line of best fit, we can build a linear regression model using the Scikit-learn library in Python. Again, our aim is to calculate the model parameters β0 and β1 that minimize the residuals.
Let’s come back to our example – You have been provided the data on employee salaries. Your task is to predict salary for a given period of experience a person has. You can find the dataset used in this example here.
Step 1 – Load the data and check for null values
#Read the datasetdata=pd.read_csv('Salary_Data.csv') #Display the first five rowsprint(data.head()) #Number of rows and columnsprint(data.shape) #Check for null valuesprint(data.isnull().sum())

As we can see, there are no null values. So, we can move forward with splitting the data into training and testing sets.
Step 2 – Split the dataset for training and testing
from sklearn.model_selection import train_test_split #Divide the dependent and independent features from the dataframeX=data.iloc[:,:-1]y=data.iloc[:,-1] #Divide the datatset into train and test sets keeping 10% for testingX_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.10,random_state = 7) #Check the shapeprint(X_train.shape)print(X_test.shape)
Step 3 – Let’s implement linear regression model without using Scikit-learn
#This function will be used to find the value of y intercept and slopedef coef_estimation(x, y): # number of observations/points n = np.size(x) # Find mean of x and y x_mean = np.mean(x) y_mean = np.mean(y) # Use sum of square to find out the intercept and slope SS_xy = np.sum(y*x) - (n * y_mean * x_mean) SS_xx = np.sum(x*x) - (n * x_mean * x_mean) # calculating regression coefficients slope = SS_xy / SS_xx y_intercept = y_mean - slope*x_mean return(y_intercept, slope) #Changing the shape of the input since our method coef_estimation() expects 1d arrayimport numpy as np X_train1=np.ravel(X_train)print(X_train1.shape)X_test1=np.ravel(X_test)print(X_test1.shape)

Step 4 – Let’s perform prediction on test data using our model
b = coef_estimation(X_train1, y_train) print("Estimated coefficients:\nc = {} \nm = {}".format(b[0], b[1])) y_pred_scratch = b[1]*X_test1 + b[0]

Step 5 – Let’s evaluate our model on test data
from sklearn.metrics import r2_score,mean_squared_errorprint("r2 score of our model is:", r2_score(y_test,y_pred_scratch))print("mean absolute error of our model is:", mean_squared_error(y_test,y_pred_scratch))

Now, let’s check our model against Scikit-learn’s output:
Step 6 – Train the model for prediction using Scikit-learn Library
from sklearn.linear_model import LinearRegressionregr = LinearRegression()regr.fit(X_train,y_train)

Step 7 – Predict the salary on test data
y_pred = regr.predict(X_test)print('Predictions for test data:', y_pred[:5])

Step 8 – Evaluate the sklearn linear regression model using R2 score and mean squared error
from sklearn.metrics import r2_score,mean_squared_errorprint("r2 score of our model is:", r2_score(y_test,y_pred))print("mean absolute error of our model is:", mean_squared_error(y_test,y_pred))

Do you see how similar the R2 Score and MSE from our model and Scikit-learn’s model are? Nice!
Assumptions of Linear Regression Model
It makes several assumptions about the data and the relationship between the variables:
- Linearity: There is a linear relationship between the input variables and the output variable.
- Independence of errors: The errors (residuals) are independent of each other. This means that the value of one error does not depend on the value of any other error.
- Homoscedasticity: The errors have constant variance (homoscedasticity). This means that the variance of the errors is the same across all values of the input variables.
- Normality of errors: The errors are normally distributed. This means that the distribution of the errors follows a normal distribution.
- Independence of variables: The input variables are independent of each other. This means that the value of one input variable does not depend on the value of any other input variable.
It is important to check whether these assumptions are satisfied before fitting a linear regression model, as violating these assumptions can lead to invalid or misleading results.
Building a Multiple Linear Regression Model
Step 1 – Load the data and check for null values
Step 2 – Convert features using LabelEncoder
Step 3 – Split the dataset for training and testing
Step 4 – Train the model for prediction
Step 5 – Predict the profits for test data
Step 6 – Evaluate the model
Let’s take another example – You have been provided the data on a few startups. Your task is to predict the profit of these startups based on the features provided in the dataset. You can find the dataset used in this example here.
Step 1 – Load the data and check for null values
#Read the datasetdf=pd.read_csv(' 50_Startups.csv') #Check for null valuesprint(df.isnull().sum()) #Display the first five rowsprint(df.head()) #Number of rows and columnsprint(df.shape)

As we can see, there are no null values. So, we can move forward for prediction.
As we cannot use string objects for prediction, we convert the categorical features to numerical values using Label Encoder:
Step 2 – Convert features using LabelEncoder
from sklearn.preprocessing import LabelEncoderle=LabelEncoder()df['State']=le.fit_transform(df['State'])df.head()

Notice that the State names are converted into numerical labels.
Step 3 – Split the dataset for training and testing
from sklearn.model_selection import train_test_split #Divide the dependent and independent features from the dataframeX= df.iloc[:,:-1]y= df.iloc[:,-1] #Divide the datatset into train and test sets keeping 20% for testingX_train,X_test,y_train,y_test=train_test_split(X, y,test_size=0.20,random_state = 1) #Check the shapeprint(X_train.shape)print(X_test.shape)print(y_train.shape)print(y_test.shape)

Step 4 – Train the model for prediction
lr = LinearRegression()lr.fit(X_train,y_train)print('The final coefficients after training is:',lr.coef_)print('The final intercept after training is:',lr.intercept_)

Step 5 – Predict the profits for test data
from sklearn.metrics import r2_score,mean_squared_errory_pred = lr.predict(X_test)
Step 6 – Evaluate the model
print("r2 score of our model is:", r2_score(y_test,y_pred))print("mean absolute error of our model is:", mean_squared_error(y_test,y_pred,squared=False))

Endnotes
Linear Regression is a simple yet powerful Supervised Machine Learning Algorithm. It is one of the first models to learn as a Machine Learning enthusiast. Machine Learning is an increasingly growing domain that has been adopted by various sectors in the IT industry and hugely impacts big businesses worldwide.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst
