
Market Basket Analysis in Python
In this article, we will discuss the application of machine learning in retail industry for predicting sales and customer segmentation using Apriori Algorithm.

Introduction
Machine Learning finds various applications in the Retail Industry from predicting product sales to customer segmentation, etc. One of such popular applications is the Market Basket Analysis – an unsupervised learning technique based on the method of Association.
In this article, we will discuss Association Rules and use Apriori Algorithm, commonly used in data mining, to solve the problem of generating frequently bought item sets. We will implement this entire process in Python using the Pandas and Mlxtend libraries on a large-scale dataset.
Best-suited Python courses for you
Learn Python with these high-rated online courses

Table of Content
- What is Market Basket Analysis?
- Association Rule Mining
- Apriori Algorithm
- Performing Market Basket Analysis with Apriori Algorithm
What is Market Basket Analysis?
Do you recall ever noticing the upsell features such as ‘frequently bought together or ‘customers also bought’ on any of the e-commerce websites?
Maybe something like this on Amazon:

This is a classic example of Market Basket Analysis and how it is used to uncover the association between items that are frequently bought together.

As shown in the image above, retailers try to upsell their items by giving a discount when bought as a pack. This baits the customers to buy all three items instead of just one because people sure do love discounts (and cookies)!
The entire process of analyzing the buying trend of customers to identify the relationship between items can be represented by the following equation:
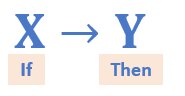
This equation is called the Association Rule. If item X is bought by a customer, there is a likelihood of item Y being bought in the same transaction.
Here, X is the Antecedent and Y is the Consequent.
Must Check: What is Machine Learning?
Must Check: Machine Learning Online Courses & Certifications
Let’s understand this in detail below.

 Read Later
Read Later
Association Rule Mining
Association Rule Mining or Frequent Itemset Mining is the technique used to perform Market Basket Analysis. It helps in discovering associations and correlations between items in huge transactional datasets. Finding such correlational relationships helps businesses in decision-making processes, marketing campaigns, and customer segmentation.
As we discussed in the above section, the association rule states: X -> Y, where
- X and Y are item sets in a given set of items I = {X1, X2, X3, …. , Xn}, where n >= 2.
- An itemset X can represent a set of items in I and is called an n-item setif it contains n items.
- So, if the transaction database consists of n items, then the number of possible large item sets is 2n.
Association Rule Mining identifies the relationship between the items purchased in different transactions with the help of the Apriori algorithm. But before getting into it, let’s discuss the three main association rule parameters –
Support
Support is the fraction of transactions in a database that indicates the frequency of the items in the data.
The support of item X can be given as:
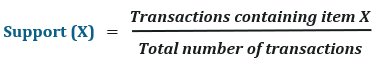
Confidence
Confidence is the likelihood of buying item Y when item X has already been purchased.
The confidence of X -> Y can be given as:
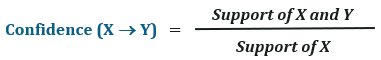
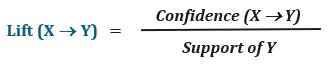
Lift
Lift is the correlation measure that defines the importance of the association rule. It basically compares confidence to expected confidence. The lift can be given as:
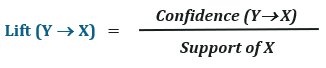
Let’s understand with the help of a simple example.
Consider the following transaction data:
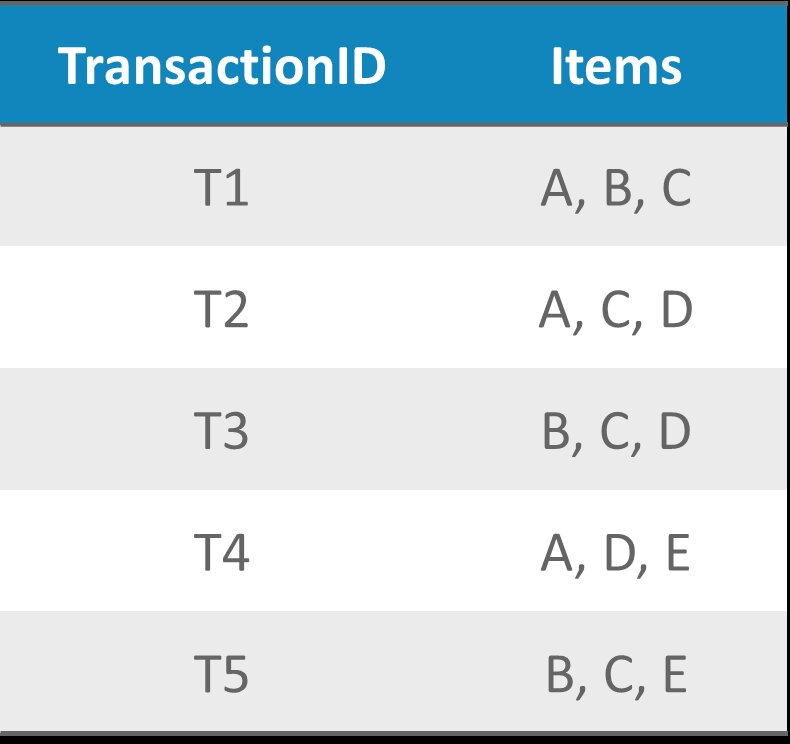

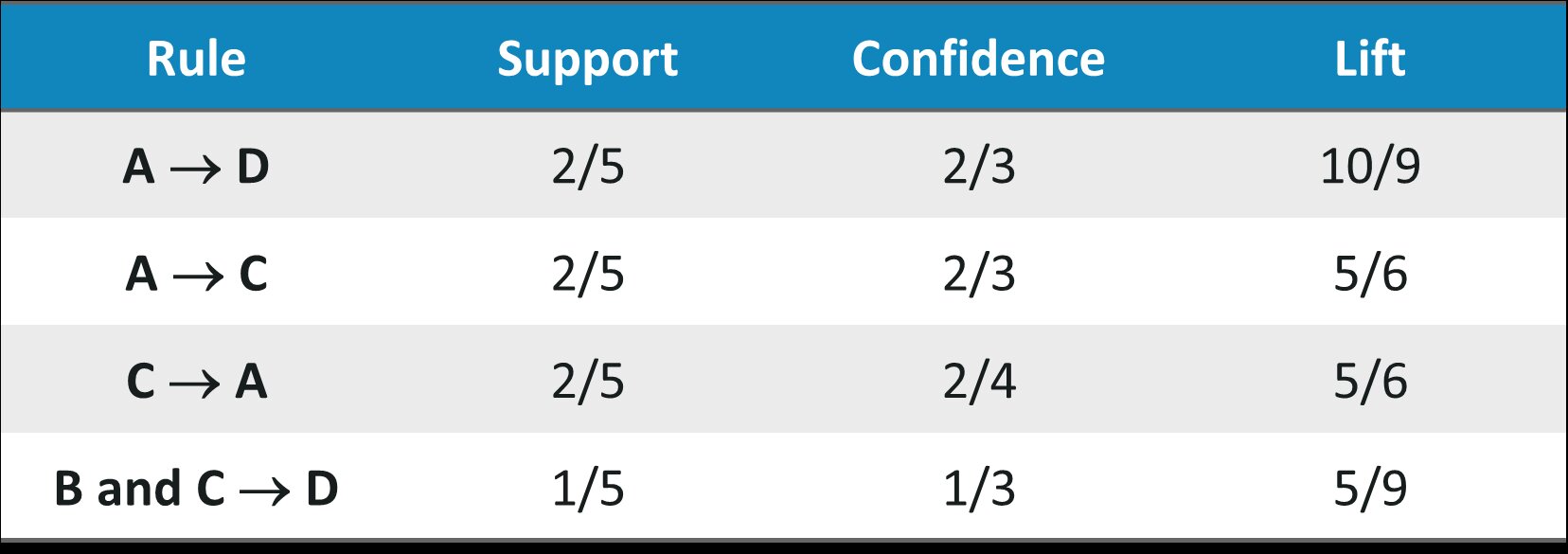
Using the formulas for Support, Confidence, Lift we calculate the values for each of the association rules:
So, in Association Rule Mining we perform the following steps:
- Find all frequent itemsets:
A frequent itemset is one whose support is greater than or equal to the minimum support threshold (minSup).
- Generate Association Rules from the frequent itemsets:
A strong association rule must satisfy both – a minimum support threshold (minSup), and a minimum confidence threshold (minConf).



Apriori Algorithm
Apriori algorithm is the most commonly used algorithm used for Market Basket Analysis.
- It is used for mining frequent itemsets and generating relevant association rules.
- It works better on large databases containing a lot of transactions.
The main idea behind Apriori is that all subsets of a frequent itemset must also be frequent. Similarly, for an infrequent itemset, all its supersets must also be infrequent.
How Apriori Works
- Apriori algorithm scans the transaction database D to count the support of each item i in a set of items I in and determines the set of large 1-itemsets.
- After that, iterations are performed to compute support for the set of 2-itemsets, 3-itemsets, and so on…
The nth iteration consists of two steps:
1. Generate a candidate set Cn from the set of large (k-1)-itemsets, that has a length L (n-1)
2. Scan the database to compute the support of each itemset in Cn
- The number of scans over the transaction database is the same as the length of the possible maximal itemset whose superset is infrequent.
Performing Market Basket Analysis with Apriori Algorithm
Problem Statement:
For demonstration, we are going to perform Market Basket Analysis on retail data using the Apriori Algorithm. The dataset provided needs to be pre-processed beforehand to make it usable.
Let’s get started!
The dataset has 8 features as given below:
- InvoiceNo – Invoice number
- StockCode – Stock code of the item
- Description – Description of item
- Quantity – Quantity of item
- InvoiceDate – Data of invoice generation
- UnitPrice – Price of item per unit
- CustomerID – ID of the customer
- Country – Country of residence
Tasks to be performed:
- Importing required libraries
- Loading the data
- Cleaning the data
- Creating basket
- Encoding
- Generating frequent itemsets
- Generating association rules
- Filtering rules with high Confidence and Lift
Step 1 – Importing required libraries
We will be using the mlxtend Apriori library in Python, as shown below:
#Import required libraries import pandas as pd from mlxtend.frequent_patterns import apriori from mlxtend.frequent_patterns import association_rules
Step 2 – Loading the data
#Load the data data = pd.read_csv('data.csv', encoding= 'unicode_escape')
Step 3 – Cleaning the data
#Remove spaces from the description column data['Description'] = data['Description'].str.strip() #Drop rows without invoice number data.dropna(axis=0, subset=['InvoiceNo'], inplace=True) data['InvoiceNo'] = data['InvoiceNo'].astype('str') #Remove the credit transaction with invoice numbers containing 'C' data = data[~data['InvoiceNo'].str.contains('C')] data.head()
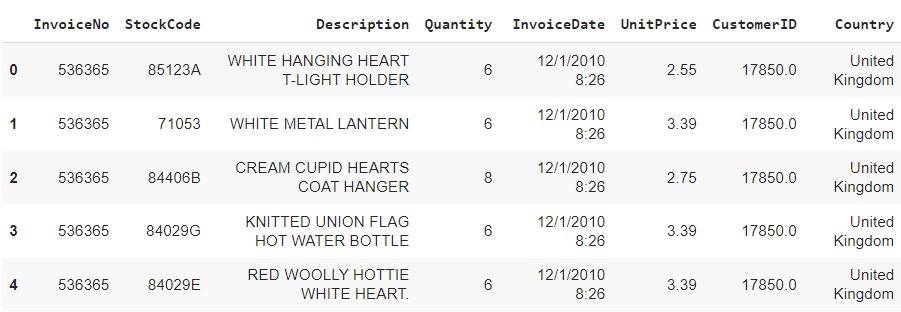
Step 4 – Creating basket
We are going to create a basket matrix by grouping multiple items within the same order and then unstack our DataFrame:
basket = (data[data['Country'] =="France"] .groupby(['InvoiceNo', 'Description'])['Quantity'] .sum() .unstack() .reset_index() .fillna(0) .set_index('InvoiceNo')) basket.head(10)
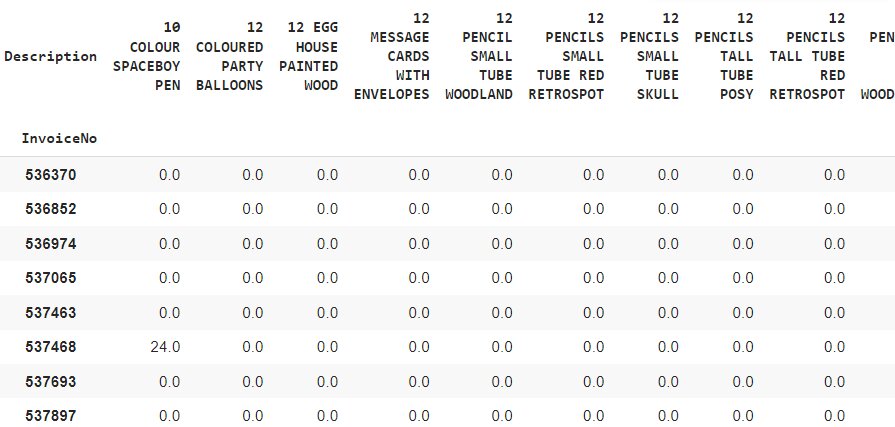
Step 5 – Encoding
We now need to encode the values in our matrix to 1’s and 0’s. We will do this in the following manner:
- Set the value to 0 if it is less than or equal to 0.
- Set the value to 1 if it is greater than or equal to 1.
def encode_units(x): if x <= 0: return 0 if x >= 1: return 1 basket_sets = basket.applymap(encode_units) basket_sets.drop('POSTAGE', inplace=True, axis=1) basket_sets.head()
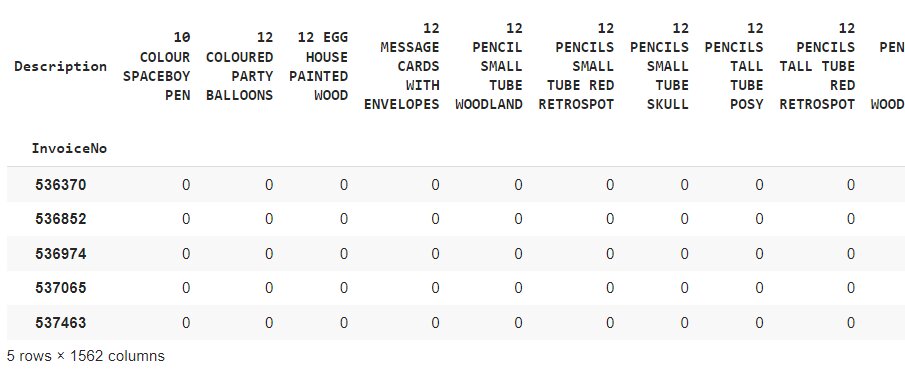
Step 6 – Generating frequent item sets
We will generate frequent item sets that have a support of at least 7%:
#Generate frequent itemsets frequent_itemsets = apriori(basket_sets, min_support=0.07, use_colnames=True)
Step 7 – Generating association rules
We will generate association rules with their corresponding support, confidence, and lift:
#Generating the rules rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1) rules.head()
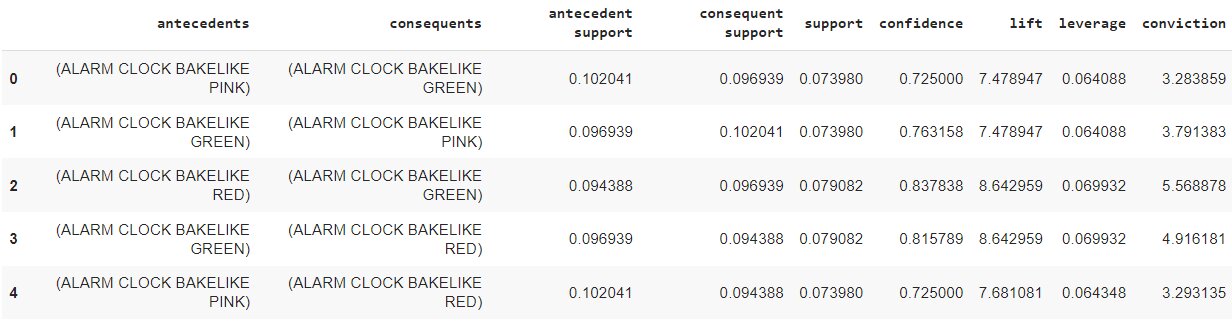
Step 8 – Filtering rules with high Confidence and Lift
As we already know, the greater the lift ratio, the more significant the association between the items. Also, the higher the confidence, the more reliable are the rules.
So, we are looking for rules with high confidence (>=0.8) and high lift (>=6). For this we filter the records as shown:
#Filtering out the values with lift > = 6 and confidence > = 0.8 rules[ (rules['lift'] >= 6) & (rules['confidence'] >= 0.8) ]
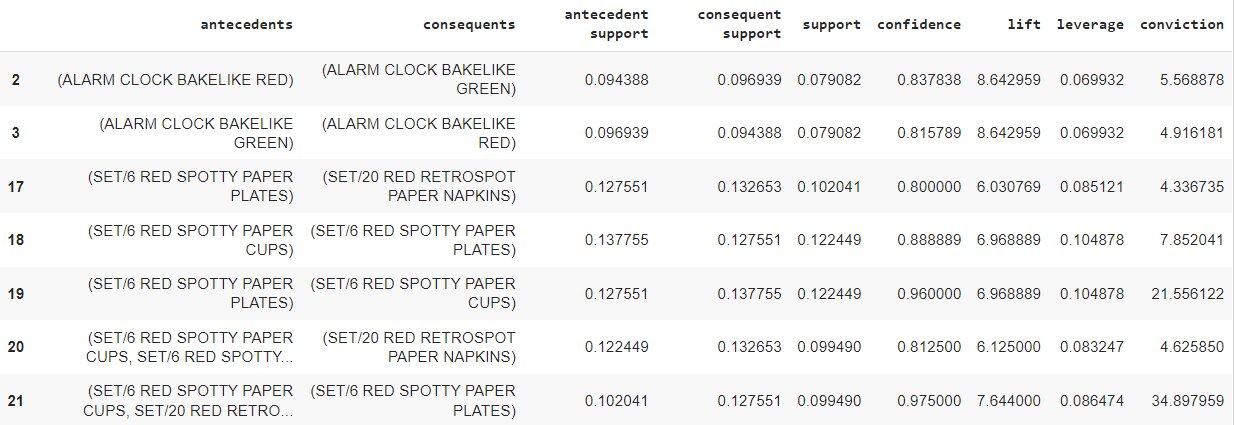
So, we have our antecedents and consequent items along with their parameter values.
The result is giving us a lot of information about item grouping such as customers are 84% likely to buy the green alarm clock if they have already bought the red alarm clock!
Conclusion
Association Rule Mining through the Apriori algorithm is a widely known technique in machine learning to perform Market Basket Analysis. This analyzing process is used to discover the association between products in a manner that will be helpful for retailers or marketers in developing useful marketing strategies and business plans.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst
