
How to Read and Write Files Using Pandas
In this tutorial, we are going to see how to read data and files using Pandas.

Pandas is a very popular Python library that offers a set of functions and data structures that aid in data analysis more efficiently. The Pandas package is mainly used for data pre-processing purposes such as data cleaning, manipulation, and transformation. Hence, it is a very handy tool for data scientists and analysts. Let’s find out how to read and write files using pandas.
We will cover the following sections:
Data Structures in Pandas
There are two main types of Data Structures in Pandas –
- Pandas Series: 1D labeled homogeneous array, size-immutable
- Pandas DataFrame: 2D labeled tabular structure, size-mutable
Mutability refers to the tendency to change. When we say a value is mutable, it means that it can be changed.
DataFrame is a widely used and one of the most important data structures. It stores data as stored in Excel with rows and columns.
Let’s see how we create a DataFrame using Pandas, shall we?
Importing Pandas Library
#Importing Pandas Libraryimport pandas as pd
Creating a Pandas DataFrame
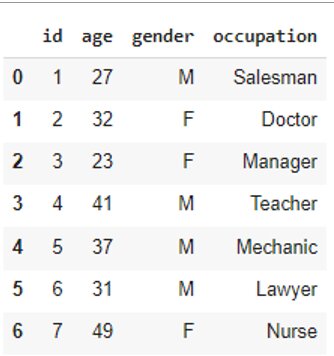
#Creating a Sample DataFramedata = pd.DataFrame({ 'id': [ 1, 2, 3, 4, 5, 6, 7], 'age': [ 27, 32, 23, 41, 37, 31, 49], 'gender': [ 'M', 'F', 'F', 'M', 'M', 'M', 'F'], 'occupation': [ 'Salesman', 'Doctor', 'Manager', 'Teacher', 'Mechanic', 'Lawyer', 'Nurse']}) data
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
Writing a File Using Pandas
Save the DataFrame we created above as a CSV file using pandas .to_csv() function, as shown:

#Writing to CSV filedata.to_csv('data.csv')
We can also save the DataFrame as an Excel file using pandas .to_excel() function, as shown:
#Writing to Excel filedata.to_excel('data2.xlsx')
Save the DataFrame we created above as a Text file using the same function that we use for CSV files:
#Writing to Text filedata.to_csv('data3.txt')
There are various other file formats that you can write your data to. For example:
- .to_json()
- .to_html()
- .to_sql()
Take note that this isn’t an exhaustive list. There are more formats you can write to, but they are out of the scope of this article.
Reading a File Using Pandas
Once your data is saved in a file, you can load it whenever required using pandas .read_csv() function:
#Reading the CSV filedf = pd.read_csv('data.csv')df

You can use this function to load your Text file as well.
But to load your Excel file, you will use the pandas .read_excel() function:
#Reading the Excel filedf2 = pd.read_excel('data2.xlsx')df2

There are various other file formats that you can import your data from. For example:
- .read_json()
- .read_html()
- .read_sql()
Take note that this isn’t an exhaustive list either. There are more formats you can read from, but they are out of the scope of this article.
For now, we are going to focus on the most common data format you are going to work with – the CSV format.
Importing a CSV File into the DataFrame
- File path
- Header
- Column delimiter
- Index column
- Select columns
- Omit rows
- Missing values
- Alter values
- Compress and decompress files
File path
We have seen above how you can read a CSV file into a DataFrame. You can specify the path where your file is stored when you’re using the .read_csv() function:
#Specifying the file pathdf.read_csv('C:/Users/abc/Desktop/file_name.csv')
Header
You can use the header parameter to specify the row that will be used as column names for your DataFrame. By default, header=0 which means that the first row is considered as the header.
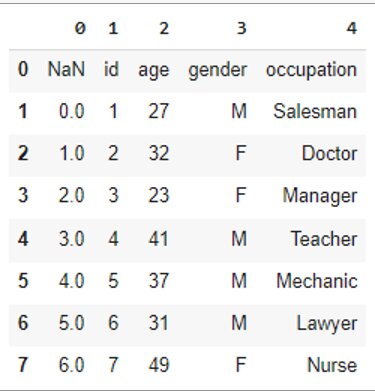
When the header is specified as None, there will be no header:
df = pd.read_csv('data.csv', header=None)df
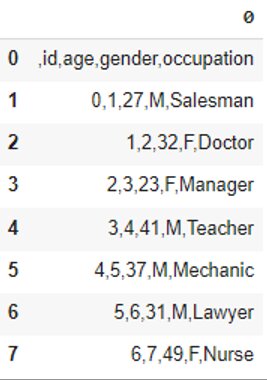
Column delimiter
You can use the sep parameter to specify a custom delimiter for the CSV input. By default, it is a comma.
#Use tab to separate valuesdf = pd.read_csv('data.csv', header=None, sep='\t')df

 Read Later
Read Later
Index column
The index_col parameter allows you to set the columns that can be used as the index of the DataFrame. By default, it is set to None. It can be set as a column name or column index:
df = pd.read_csv('data.csv', index_col='gender')df

Select columns
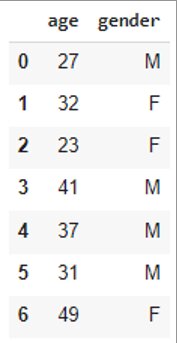
The usecols parameter specifies which columns to import to the DataFrame. It can be set as a list of column names or column indices:
df = pd.read_csv('data.csv', usecols=['age','gender'])df
Omit rows
- The skiprows parameter specifies the number of rows to skip at the start of the file:
df = pd.read_csv('data.csv', skiprows=2)df
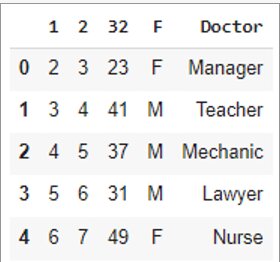
- The skipfooter parameter specifies the number of rows to skip at the end of the file:
df = pd.read_csv('data.csv', skipfooter=2)df
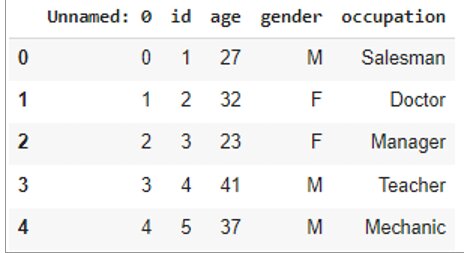
- The nrows parameter specifies the number of rows to read:
df = pd.read_csv('data.csv', nrows=3)df

Missing values
The na_values parameter specifies which values are to be considered as NaN. It can be set as a list of strings:
df = pd.read_csv('data.csv', na_values=['Doctor', 23])df
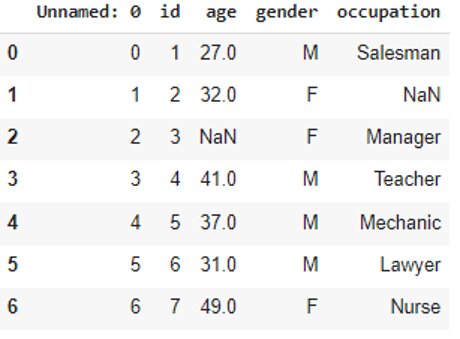
Alter values
The converters parameter converts the column values according to the defined functions:
#A function that reduces each value by 3f = lambda x: int(x) – 3 df = pd.read_csv('data.csv', converters={'age':f})df
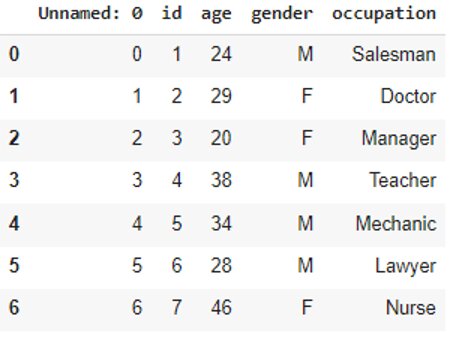
Compress and decompress files
You can compress the DataFrame when writing to a file. The .read_csv() function decompresses the file before reading it into the DataFrame.
The compression parameter decompresses the file and can be set to any of the following methods:
{'infer', 'gzip', 'bz2', 'zip', 'xz', 'zstd', None, dict}
infer is the default value.
#Compress the DataFrame while writing to the CSV filedf.to_csv('data.csv.zip') #Decompress the file while readingdf = pd.read_csv('data.csv.zip', compression='zip')df
Compressing the files particular helps when you’re dealing with big data problems.
Endnotes
Pandas is a very powerful data processing tool for the Python programming language. It provides a rich set of functions to import and process various types of file formats from multiple data sources. The Pandas library is specifically useful for data scientists working with data cleaning and analysis. Hope this article on read and write files using pandas was helpful to you.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst
