
Top Data Science Tools To Make You Job-ready in 2024
The article covers various types of basic yet important tools used in data science every aspiring data scientist should master to succeed in their career in data science.

Data science has emerged as an advantageous career option for those interested in extracting, manipulating, and generating insights from enormous data volumes. There is a massive demand for data scientists across industries, which has pulled many non-IT professionals and non-programmers to this field. If you are interested in becoming a data scientist without being a coding ninja, get your hands on data science tools.
You don’t require any programming or coding skills to work with these tools. These data science tools offer a constructive way to define the entire Data Science workflow and implement it without any coding bugs or errors.
To learn more about data science, read our blog – What is data science?
Before starting with the tools, I hope you have a good concept of basic statistics and mathematics. Otherwise, just the knowledge of tools won’t be enough. You don’t require any programming or coding skills to work with these tools. These data science tools offer a constructive way to define the entire Data Science workflow and implement it without any coding bugs or errors.

This article is divided into two segments –
Segment 1 – Basic Data Science and Machine Learning Tools
Segment 2 – Advanced Data Science and Machine Learning Tools
Segment 1 – Basic Data Science and Machine Learning Tools
Let us look at the various types of basic yet important tools used in data science. We will use the tool ecosystem as described in a report by O’Reilly, which will help us to understand the data science environment better.
Cluster 1 (Microsoft-Excel-SQL)
Corresponding preferred role: Business Intelligence
- Excel – The basic database and data analysis tool that most data scientists started out with. As you move to a higher role in data science, this tool won’t find any significance but it will still remain core to your work profile.
- VBA – It is essential for those who work with Excel most of the time. With VBA, you can move one step into the field of automation. You can create your own complex functions that otherwise cannot be done simply through Excel’s library functions.
- MS SQL Server/SQL – As your data grows, it might be difficult to store in Excel files as it can become slow and difficult to manage. MS SQL Server is an RDBMS (regional database management system) that offers good functionality in storing and retrieving data. SQL is the language that is used to manage data in an RDBMS.
- SAS/SPSS – SAS and SPSS are both analytical software suites with proprietary licenses. SAS has been developed by SAS Institute while SPSS has been developed by IBM. Due to the popularity of R and Python, SAS and SPSS usage have gone down. However, it is still used by many industries as they are easy to learn and implement.
Cluster 1 is popular among those who have just started their career in data science as it gives them a good learning curve. Excel, SAS, SQL, and VBA are all easy to learn and do not require extensive programming skills.
Cluster 2 and Cluster 3 (Hadoop-Python-R)
The corresponding preferred role for:
Cluster 2 – Hadoop and Data Engineering
Cluster 3 – Machine Learning and Data Analytics
- Python/R – Both Python and R have been gaining popularity over the years as the go-to programming language for data scientists. R is hugely popular for its complex problem-solving capabilities. Python, on the other hand, is easier to learn if you have basic knowledge of object-oriented programming languages.
- Hadoop – With the growing importance of big data in analytics, Hadoop is an important tool for process huge datasets.
- Cassandra/MongoDB/NoSQL – RDBMS supports structured and predictable data. This becomes a disadvantage while working with big data. Cassandra, MongoDB, and NoSQL are useful for storing and managing unstructured data.
- NumPy/SciPy – They are libraries for Python which can be used for high-level mathematical, scientific, and technical computing. It is one of the widely-used tools in Python programming.
Cluster 4 (Mac OS-JavaScript-MySQL)
Corresponding preferred role: Data Visualisation
This is a relatively new cluster and is more or less centered on the Mac OS.
- JavaScript – In terms of data science, JavaScript is the least popular programming language but is highly useful for data visualization. It lacks a number of libraries in comparison to R and Python.
- MySQL – It is important for server-side queries and helpful in extracting datasets from a relational database.
- js – If you want to improve your data visualization through JavaScript, you can use the D3.js library. It offers stunning and powerful data visualization in web browsers.
Best-suited Personal Development courses for you
Learn Personal Development with these high-rated online courses

Segment 2 – Advanced Data Science and Machine Learning Tools
RapidMiner
RapidMiner is a data science tool that offers an integrated environment for various technological processes. This includes machine learning, deep learning, data preparation, predictive analytics, and data mining.
It allows you to clean up your data and then run it through a wide range of statistical algorithms. Suppose you want to use machine learning instead of traditional data science. In that case, the Auto Model will choose from several classification algorithms and search through various parameters until it finds the best fit. The goal of the tool is to produce hundreds of models and then identify the best one.
Once the models are created, the tool can implement them while testing their success rate and explaining how it makes its decisions. Sensitivity to different data fields can be tested and adjusted with the visual workflow editor.
Recent enhancements in RapidMiner include better text analytics, a greater variety of charts for building visual dashboards, and sophisticated algorithms to analyze time-series data.
RapidMiner is used widely in banking, manufacturing, oil & gas, automotive, life sciences, telecommunication, retail, and insurance. Some of the most popular RapidMiner products are –
Studio – Comprehensive data science platform with visual workflow design and full automation. Cost – $7,500 – $15,000 per user per year
Server: RapidMiner Server enables computation, deployment, collaboration, thereby enhancing the productivity of analytics teams
Radoop: RapidMiner Radoop eliminates the complexity of data science on Hadoop and Spark
Cloud: It is a cloud-based repository that enables easy sharing of information among different tools
DataRobot
DataRobot caters to data scientists at all levels and serves as a machine learning platform to help them build and deploy accurate predictive models in reduced time. This platform trains and evaluates 1000’s models in R, Python, Spark MLlib, H2O, and other open-source libraries. It uses multiple combinations of algorithms, pre-processing steps, features, transformations, and tuning parameters to deliver the best models for your datasets.
Features
- Accelerates AI use case throughput by increasing the productivity of data scientists and empowering non-data scientists to build, deploy, and maintain AI
- Provides an intuitive AI experience to the user, helping them understand predictions and forecasts
- Can be deployed in a private or hybrid cloud environment using AWS, Microsoft Azure, or Google Cloud Platform
Tableau
Tableau is a top-rated data visualization tool that allows you to break down raw data into a processable and understandable format. It has some brilliant features, including a drag and drop interface. It facilitates tasks like sorting, comparing, and analyzing, efficiently.
Tableau is also compatible with multiple sources, including MS Excel, SQL Server, and cloud-based data repositories, making it a popular data science tool for non-programmers.
Features
- It allows connecting multiple data sources and visualizing massive data sets and find correlations and patterns
- The Tableau Desktop feature allows getting real-time updates
- Tableau’s cross-database join functionality allows to create calculated fields and join tables, and solve complex data-driven problems
- Tableau leverages visual analytics enabling users to interact with data and thereby helping them to get insights in less time and make critical business decisions in real-time.
Minitab
Minitab is a software package used in data analysis. It helps input the statistical data, manipulate that data, identify trends and patterns, and extrapolate answers to the existing problems. It is among the most popular software used by the business of all sizes
Minitab has a wizard to choose the most appropriate statistical tests. It is an intuitive tool.
Features
- Simplifies the data input for statistical analysis
- Manipulates the dataset
- Identifies trends and patterns
- Extrapolates the answers to the existed problem with product/services
Trifacta
Trifacta is regarded as the secret weapon of data scientists. It has an intelligent data preparation platform, powered by machine learning, which accelerates the overall data preparation process by around 90%. Trifacta is a free stand-alone software offering an intuitive GUI for data cleaning and wrangling.
Besides, its visual interface surfaces errors, outliers, or missing data without any additional task.
Trifacta takes data as input and evaluates a summary with multiple statistics by column. For every column, it recommends some transformations automatically.
Features
- Seamless data preparation across any cloud, hybrid, or multi-cloud environment
- Automated visual representations of data in a visual profile
- Intelligently assesses the data to recommend a ranked list of transformations
- Enables to deploy and manage self-service data pipelines in minutes
BigML
BigML eases the process of developing Machine Learning and Data Science models by providing readily available constructs. These constructs help in the classification, regression, and clustering problems. BigML incorporates a wide range of Machine Learning algorithms. It helps build a robust model without much human intervention, which lets you focus on essential tasks such as improving decision-making.
Features
- Offers multiple ways to load raw data, including most Cloud storage systems, public URLs, or your own CSV/ARFF files
- A gallery of well-organized and free datasets and models
- Clustering algorithms and visualization for accurate data analysis
- Anomaly detection
- Flexible pricing
Become Machine Learning Expert Now>>
MLbase
MLbase is an open-source tool used for creating large-scale Machine Learning projects. It addresses the problems faced while hosting complex models that require high-level computations.
MLBase consists of three main components:
ML Optimizer – It automates the Machine Learning pipeline construction
MLI – An experimental API focused on feature extraction and algorithm development for high-level ML programming abstractions
MLlib – ML library of Apache Spark
Features
- A simple GUI for developing Machine Learning models
- Tests the data on different learning algorithms to detect the best accuracy
- Simple and easy to use, for both programmers and non-programmers
- Efficiently scales large, convoluted projects
Google Cloud AutoML
Google Cloud AutoML is a platform to train high-quality custom machine learning models with minimal effort and limited machine learning expertise. It allows for building predictive models that can out-perform all traditional computational models.
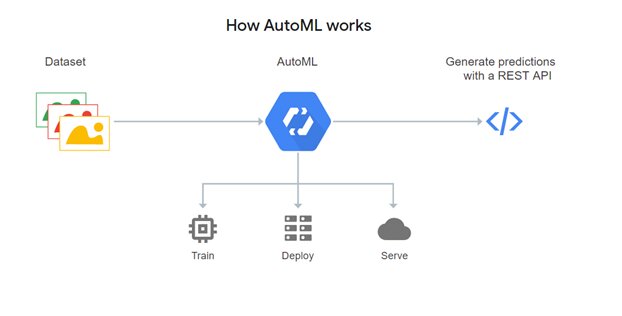
Fig – How Google AutoML works?
Features
- Uses simple GUI to train, evaluate, improve, and deploy models based on the available data
- Generates high-quality training data
- Automatically builds and deploys state-of-the-art machine learning models on structured data
- Dynamically detect and translate between languages
Courses on Data Science Tools
- Mastering Data Science and Machine Learning Fundamentals
- Data Science: Machine Learning
- Programming for Data Science with Python
- Machine Learning
- Machine Learning for Data Science and Analytics
- Google Cloud Platform Big Data and Machine Learning Fundamentals
- Python Basics for Data Science
Data science has emerged as an advantageous career option for those interested in extracting, manipulating, and generating insights from enormous data volumes. There is a massive demand for data scientists across industries, which has pulled many non-IT professionals and non-programmers to this field. These machine learning and data science tools will help non-programmers to manage their unstructured and raw data, and draw correct conclusions. To sharpen your data science skills further, you can take up any relevant data science e-course.
If you have recently completed a professional course/certification, click here to submit a review.
FAQs
What is the eligibility criteria to become a data scientist?
To work as a data scientist, you must have an undergraduate or a postgraduate degree in a relevant discipline, such as Computer science, Business information systems, Economics, Information Management, Mathematics, or Statistics.
Which are the Top Platforms to Learn Data Science and Machine Learning?
Some popular platforms are Coursera, Udemy, edX, Kaggle, DataCamp, Udacity, Edureka, etc.
What are the best resources to learn how to use Python for Machine Learning and Data Science?
You can learn Python through tutorials that cover concepts from beginner to advanced levels. Multiple eLearning portals provide such tutorials. You can learn Python from Books, tutorials, from MOOCs, from Paid classroom courses, from YouTube and also from live Applications. However, you cannot become a good data scientist by just learning Python. You should master Data Science with Python which covers programming with Python, Database Technologies, a good hold on Mathematics and Statistical principles as well as Machine Learning with Python. You should also be good with Information Retrieval
Which are the top industries hiring data scientists?
Some of the most popular recruiters for data scientists are - BFSI, Public Health, Telecommunications; Energy; Automotive; Media & Entertainment; Retail, etc.
Which are the best data science courses available online?
https://learning.naukri.com/executive-data-science-specialization-course-courl402; https://learning.naukri.com/the-data-scientists-toolbox-course-courl468; https://learning.naukri.com/launching-machine-learning-delivering-operational-success-with-gold-standard-ml-leadership-course-courl509; https://learning.naukri.com/simplilearn-data-scientist-masters-program-course-sl02https://learning.naukri.com/data-science-machine-learning-course-edxl236; https://learning.naukri.com/python-for-data-science-and-machine-learning-bootcamp-course-udeml455
Is data science a good career?
Data Science is the fastest-growing job on LinkedIn and is speculated to create 11.5 million jobs by 2026. Employment opportunities are available across different industries and are among the highest paying jobs across the globe, making it a very lucrative career option.
What are the major job responsibilities of a data scientist?
The common job responsibilities of a data scientist are - Enhancing data collection procedures for building analytic systems; Processing, cleaning, and verifying the integrity of data; Creating automated anomaly detection systems and track their performance; Digging data from primary and secondary sources; Performing data analysis and interpret results using standard statistical methodologies; Ensuring clear data visualizations for management; Designing, creating and maintaining relevant and useful databases and data systems; Creating data dashboards, graphs, and visualizations; etc.
How should I pursue a career in Machine Learning?
To pursue a career in machine learning, you need to be equally skilful in any programming language like Python or R, mathematics, data analysis tools, and database management. Usually, it is advisable to start learning the fundamentals of data analysis with a programming language, then gradually move into machine learning.
What technical skills I must have to become a data scientist?
Knowledge of Python Coding, Hadoop, Hive, BigQuery, AWS, Spark, SQL Database/Coding, Apache Spark, among others; Knowledge of Statistical methods and packages; Working experience with Machine Learning, Multivariable Calculus & Linear Algebra; Ability to write codes and manage big data chunks; Hands-on experience with real-time data and cloud computing; Ability to use automated tools and open-source software; Knowledge of Data warehousing and business intelligence platforms
How to become a data scientist?
To become a data scientist, you should - Pursue an internship with any Data Science firm; Take up any online Data Science course, and courses that teach Statistics, Probability, and Linear Algebra; Learn about the basics of Natural Language Processing, Information Extraction, Computer Vision, Bioinformatics, and Speech Processing, etc.; Explore Optimization, Information Theory, and Decision Theory; Obtain any professional certification; Try managing databases, analyzing data, or designing the databases

Rashmi Karan is a writer and editor with more than 15 years of exp., focusing on educational content. Her expertise is IT & Software domain. She also creates articles on trending tech like data science,