
Tree Traversal in Data Structure
Tree traversal is the process of systematically visiting each node in a tree data structure. It involves exploring the nodes in a specific order, such as inorder, preorder, or postorder, to perform operations or retrieve information. Tree traversal is a fundamental concept in data structures and is used to analyze and manipulate tree-based data efficiently.

Before diving deep into Tree Traversals, I would like to briefly describe the “Tree” data structure.”Data structure” is combined of the two words “Data” and “Structure,” i.e., a structure or a container that stores data. Many data structures, like Arrays, Stacks, Queues, Linked Lists, etc., are already present and can store data linearly. This question always comes to our mind if such simplified data structures were already available, then what was the need for “Trees”?There are many situations in our daily life when information/data is arranged/stored non-linearly, so we need to define a structure that can organize data hierarchically.
For example, a family tree, a file directory, or an organizational hierarchy are all stored in a non-linear/hierarchical fashion. One of the disadvantages of linear data structures is the time to search for an item. For example, if the data size is ‘N,’ then the number of comparisons to search for an item will also be some multiple of ‘N,’ which is unacceptable in today’s fast world. This led to a more efficient data structure to store and search data. In this article, we are going to discuss tree traversal.

Table of contents
Best-suited Data Structures and Algorithms courses for you
Learn Data Structures and Algorithms with these high-rated online courses

Introduction to Trees
In computer science, “Tree” is represented the same way as seen in the real world. Each tree will have a root node, and then branches spin out of them, which are called edges, and these edges connect the nodes related to the root node (Note: these edges and nodes should not form a cycle/loop). “Tree is a collection of multiple nodes which are connected by edges. Each node
contains some data and may or may not have child nodes”.
Terminologies used for “Tree” data structure
• Node: Structure containing a value or condition
• Root: Top node of a tree
• Child: Immediate descendant
• Parent: Immediate ancestor
• Leaf: Node with zero child
• Internal node: Node with at least one child
• Edge: Link between one node to another
• Depth: Distance from Root to node
• Siblings: Nodes having the same parent
• Level: Number of edges between node and root+1
• Height: Maximum distance from the node to a descendant leaf


 Read Later
Read Later

Also explore: Understanding Data Structures in C: Types And Operations
Structure of Tree
Here, ‘A’ is the root node, and the branches coming out of the Root are the edges connecting to the child nodes- ‘B’ and ‘C.’
Nodes ‘B’ and ‘C’ & Nodes’ D’ and ‘E’ are called siblings.
Nodes without children are leaf nodes (Here, ‘D,’ ‘E,’ and ‘C’ are child nodes).
Applications of trees
- Tree is used in databases for indexing.
- Used in file directory management
- Tree algorithms are used in machine learning for a decision-based algorithm.
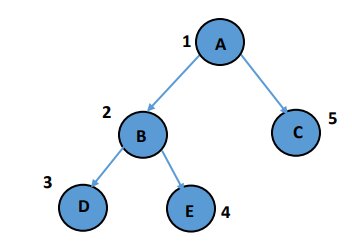
We already know that trees can have any number of child nodes, but our main focus will be on binary trees, i.e., trees having at most two child nodes.
Tree Traversal
‘Traversal’ generally means to pass through or walk through some path or data set. It is one of the most common operations performed on data structures. It is a process in which every element in a data structure is accessed/visited at least once. Similarly, visiting every node in “Tree” is called “Tree Traversal. “In a tree data structure, several options exist to traverse each node as each node is linked to two or more nodes. We have several options starting from the root node: go left via the left or right via the right pointer.
Tree traversal methods are divided broadly into two categories based on the ways of traversal- Depth First Search Traversal & Breadth First Search Traversal.
1. Depth First Search Traversal
It is a traversal algorithm in which, starting from the Root, it explores all nodes along each branch as deeply as possible until we get to a leaf node and then return to the “trunk” of the tree (backtracking).
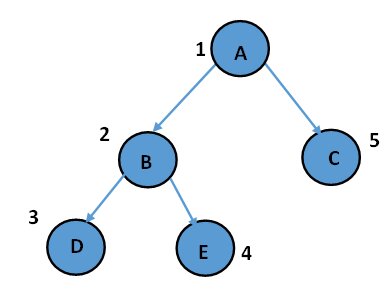
Since the stack follows the “LIFO” (Last In First Out) or “FILO” (First In Last Out) principle, i.e., whatever comes first in the stack, is the last item to be removed from the stack. So, a stack is used to implement depth-first search traversal. Depth First Search Traversal is further categorized into three popular tree traversals- Inorder Traversal, Preorder Traversal, and Postorder Traversal.
1. Inorder Tree Traversal
This tree traversal technique follows the rule- “Left Data Right,” i.e., we will start traversing from the tree’s root node and go deeper and deeper into the left subtree in a recursive manner.
After reaching the left-most node, we will visit the current node and go to the left-most node of its right subtree (if it exists).
• Traverse the left subtree
• Visit node
• Traverse the right subtree
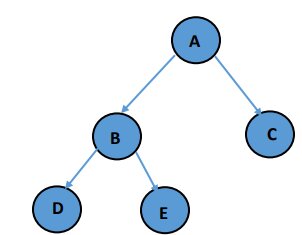
Inorder traversal: D B E A C (Left subtree -> Root -> Right subtree)
Class Node{int val;Node left;Node right;}public void inorder(Node root) {if(root!=null){inorder(root.left); // Recursively traverse left subtree print(root.val); // Print rootinorder(root.right); // Recursively traverse right subtree}}
Applications of Inorder Traversal
Inorder traversal is used for processing binary search trees.
Note: In order traversal of binary search tree generates data in increasing order.
2. Preorder Tree Traversal
Current node first and then go to the left sub-tree, and after covering every node of the left sub-tree, we will move towards the right sub-tree recursively in the same manner.
• Visit node
• Traverse left subtree
Class Node{int val;Node left;Node right;}
public void preorder(Node root){if(root!=null){print(root.val); // Print root preorder(root.left); // Recursively traverse left subtree preorder(root.right); // Recursively traverse right subtree}}
Preorder Traversal: A B D E C (Root -> Left subtree -> Right subtree)
3. Postorder Tree Traversal
This traversal technique follows the rule- “Left Right Data” i.e. we will go to the left sub-tree first and after covering every node of the left sub-tree, we will move towards the right sub-tree and then visit the current node recursively.
- Go to left subtree
- Go to right subtree
- Visit node
Postorder Traversal : D E B C A (Left subtree -> Right subtree -> Root)
Applications of postorder traversal
• To delete the tree
• To get Reverse Polish notation/postfix expression of the tree.
Time complexity Analysis
Total time complexity = Time complexity of traversing left subtree + Time complexity of traversing right subtree + Time complexity of processing root node
T(n) = T(k)+T(n-k+1)+O(1)
Where n is the size of the entire tree, k is the size of the left subtree size of right subtree=n-k+1
Space complexity Analysis
In the case of skewed binary trees, when there is only one node at each level, the height of tree= n
Space complexity= O(n)
2. Breadth First Search Traversal (Level Order Traversal)
It is a traversal algorithm in which, starting from Root, it visits all nodes of the current level from left to right before moving to the next level in the tree. Since the queue follows First-In-First-Out (FIFO) principle, i.e., whatever comes first, is the first item to be removed from the queue.
So, a queue is used to implement Breadth First Search/ Level Order Traversal.
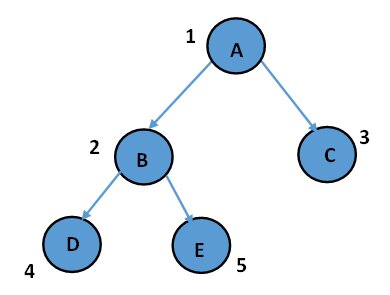
Level order traversal: A B C D E
- Add the root node to the queue.
- Iterate while the queue is not empty and print the value of the first node in the queue.
- Add the left child of a node to the queue (if it exists).
- Add the right child of a node to the queue (if it exists).
public void levelorderTraversal(Node root) { if (root == null) {return;}
Queue<Node> queue = new LinkedList<>();queue.add(root); // Add root to queue
while (!queue.isEmpty()) {Node node = queue.poll();System.out.print(node.data + " "); // Print value of first nodeof queue
if (node.left != null) {queue.add(node.left); // Add left child of node to queue}if (node.right != null) {queue.add(node.right); // Add right child of node to }}}
Application of level order traversal:
Level Order Traversal is used to generate data in same order as is stored in the array representation of tree.
Time Complexity Analysis
Visiting a node (reading its data and enqueuing its children) takes time. Since we are visiting each node once, the time it will take to implement BFS is O(n), where n is the total number of nodes.
Space Complexity Analysis
The space complexity depends on the size of the queue at its worst, i.e. almost equal to the tree’s height (O(n)).
FAQs
What is tree traversal in data structure?
Tree traversal refers to the process of visiting or accessing each node in a tree data structure exactly once in a specific order. It involves systematically exploring the nodes of the tree to perform operations or retrieve information stored in the tree.
What are the common methods of tree traversal?
The three commonly used methods for tree traversal are: Inorder Traversal: Visits the left subtree, then the root node, and finally the right subtree. Preorder Traversal: Visits the root node, then the left subtree, and finally the right subtree. Postorder Traversal: Visits the left subtree, then the right subtree, and finally the root node.
How does inorder traversal work?
In inorder traversal, the left subtree is visited recursively first, then the root node is processed, and finally, the right subtree is visited recursively. This order ensures that nodes are visited in ascending order for binary search trees, making it useful for tasks like retrieving data in sorted order.
How does preorder traversal work?
In preorder traversal, the root node is processed first, followed by a recursive traversal of the left subtree, and then the right subtree. This order is useful for creating a copy of the tree or when the root node needs to be processed before its children.
