
B Tree in Data Structure
A B-tree is a self-balancing data structure commonly used in computer science for efficient storage and retrieval of large amounts of data. Its balanced nature ensures fast search, insert, and delete operations by maintaining a sorted order of elements and minimizing the height of the tree. With its ability to handle large datasets and maintain optimal performance, the B-tree is a fundamental tool in database systems and file systems.

Table of Contents
Best-suited Data Structures and Algorithms courses for you
Learn Data Structures and Algorithms with these high-rated online courses

B-Tree
B-tree is also a self-balancing tree allowing each node multiple keys and offspring. It is the binary search tree in a more generalized version. We must consider the vast amount of data that can’t be accommodated in the main memory to comprehend the utilization of B-Trees. Data is read from the disc in the form of blocks when the no of keys is high. Disc access time is very long compared to the access time to main memory. Reducing the number of disc accesses is the major goal of employing B-Trees. Most tree operations, such as search, delete, insert, min, max, etc., call for O(h) disc accesses, where h is the tree height. B-tree is also known as the fat tree.
By packing as many keys as possible into each B-Tree node, the height is maintained to a minimum. The disc block size is often maintained as the B-Tree node size. Compared to balanced Binary Search Tres like Red-Black Tree, AVL Tree, etc., the B-low tree’s height significantly reduces the overall number of disc access for most operations.

 Read Later
Read Later

Also explore: All You Need to Know About Algorithms and Data Structures.

Features of B-Tree
An M-way tree’s characteristics are present in a B tree of order m. It also has the following characteristics.
- A B-Tree has m or fewer children at each node.
- In a B-Tree, all nodes other than the root and leaf node have at least m/2 children.
- There must be at least two nodes in the root nodes.
- The level of each leaf node must be the same.
- A node’s keys are arranged in ascending order. All the keys in the range between k1- k2 are contained in the child between k1 and k2.
- In contrast to Binary Search Tree, the B-Tree expands and contracts from the root. Binary search trees can both expand and shrink from below.
- The temporal complexity of searching, inserting, and removing is O, similar to other balanced Search Trees (log n).
- Only at the Leaf Node can a Node be inserted into a B-Tree.
Although each node should have m/2 nodes, they are not required to have the same no of children.
The image below depicts a B tree of order 4

Any B Tree property, such as the minimum number of children a node can have, may be violated while performing specific actions on the B Tree. The tree may divide or unite to preserve B Tree’s characteristics.
B-Tree Time Complexity
| S No | Algorithm | Complexity |
|---|---|---|
| 1 | Search | 0 (log n) |
| 2 | Insert | 0 (log n) |
| 3 | Delete | 0 (log n) |
B-Tree Operations
1. Searching
Similar to binary search trees, B trees also allow for searching. A binary tree search is similar to a B-Tree search. The algorithm uses recursion and is comparable. The search is optimized at each level, so it is in a different branch if the key value isn’t in the parent’s range. These numbers are called pull-back or separation values because they restrict the search. It will return NULL if we approach a leaf node but can’t find the key.
For instance, see the below B Tree for item 50. The procedure will go something like this:
- Compare root node 78 with item 50. Go to the sub-tree on its left because 49 78.
- Since 40>50>56, “Match found,” go back.
- 50>45, move towards the right side.
- Now, compare 50
- Return as the match is found.
The height of the B tree affects how you search for that tree. Any item in a B tree can be searched using the O(log n) time search algorithm.
Let us see a B tree example to understand the process of searching in a better manner:

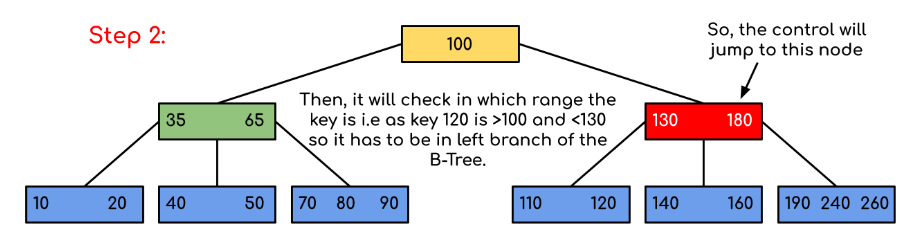
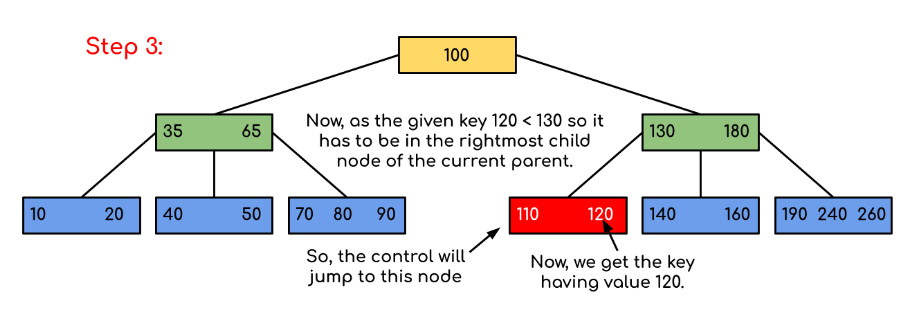
Here, we observe that our search was made more efficient by reducing the likelihood that the key carrying the value may be available. Similar to the previous example, if we had to search for 180, the control would have stopped at step 2 since the program would have discovered that the key 180 was already located in the current node. Additionally, if it needs to find 90, it will immediately move towards the left subtree since 90 100, and the command will proceed as before.
2. Insertion
At the level of the leaf node, insertions are made. The following algorithm must be used to add a new item to the B Tree.
- Find the proper leaf node where the node could be placed by traversing the B Tree.
- Insert the item in increasing order, whereas if the leaf node contains fewer keys than m-1.
- Otherwise, take the following action if such a leaf node has m-1 keys.
- Add the new element to the elements’ increasing order.
- At the median, divide the node into two further nodes.
- The median element should be raised to its parent node.
- If the parent node receives additional m-1 keys, split it using the same procedures.
3. Deletion
The leaf nodes also engage in deletion. An internal node or a leaf node can be the node that needs to be eliminated. The following algorithm must be used to remove a branch from a B tree.
- Track down the leaf node.
- Remove the desired key from the leaf node if there are more than m/2 keys.
- The item from 8 or the left sibling can be used to finish the keys if a leaf node lacks m/2 keys.
- If the left sibling has more than m/2 items, the largest element should be pushed up to the parent node, and the middle element should be moved to the node where the key is erased.
- Push the right sibling’s smallest value towards the parent and shift the preceding element downwards to the branch, where the key is erased if the right sibling has more items than m/2.
- Create a fresh leaf node by combining two leaf nodes and the parent node’s intervening element if neither of the siblings has more than m/2 elements.
- Apply the technique mentioned above to the parent if fewer than m/2 nodes are left on the parent.
If the node being removed is an internal node, its successor or predecessor should be used in its place, according to the precedence sequence. The procedure will be identified as the node is removed from the leaf node since the descendant or antecedent will remain on the leaf node.
Let us see an example below to understand the process of deletion in a B tree in a better manner:


In the B-Tree having order five illustrated in the following image, remove node 53.
The right sibling of item 49 contains 53. Please remove it.
Now that there is just one element left in node 57, a B-tree of order five will require a minimum of 2 items to be present. It should be merged with the parent’s left sibling and adjacent item, which is 49, because it is less than that, and the items in its left and right sub-tree are similarly insufficient.
The final B tree is:

B-Tree Applications
- Since accessing values held in a vast database saved on a disc takes a long time, B trees index all data and allow quick access to the information stored on the discs.
- Large databases employ it to access information stored on discs.
- Using the B-Tree, data in a dataset could be found in less time.
- Multilevel indexing is possible with the indexing feature.
- The majority of servers also use the B-tree method.
Let us now see a C program below and understand the working of a B tree using code:
#include <stdio.h>#include <stdlib.h>#define MAX 4#define MIN 3
struct BTree { int value[MAX + 1], count; struct BTree *link[MAX + 1];};
struct BTree *root;
struct BTree *createNode(int value, struct BTree *child) { struct BTree *newNode; newNode = (struct BTree *)malloc(sizeof(struct BTree)); newNode->value[1] = value; newNode->count = 1; newNode->link[0] = root; newNode->link[1] = child; return newNode;}
void insertNode(int value, int pos, struct BTree *node, struct BTree *child) { int j = node->count; while (j > pos) { node->value[j + 1] = node->value[j]; node->link[j + 1] = node->link[j]; j--; } node->value[j + 1] = value; node->link[j + 1] = child; node->count++;}
void splitNode(int value, int *pvalue, int pos, struct BTree *node, struct BTree *child, struct BTree **newNode) { int median, j;
if (pos > MIN) median = MIN + 1; else median = MIN;
*newNode = (struct BTree *)malloc(sizeof(struct BTree)); j = median + 1; while (j <= MAX) { (*newNode)->value[j - median] = node->value[j]; (*newNode)->link[j - median] = node->link[j]; j++; } node->count = median; (*newNode)->count = MAX - median;
if (pos <= MIN) { insertNode(value, pos, node, child); } else { insertNode(value, pos - median, *newNode, child); } *pvalue = node->value[node->count]; (*newNode)->link[0] = node->link[node->count]; node->count--;}
int setValue(int value, int *pvalue, struct BTree *node, struct BTree **child) { int pos; if (!node) { *pvalue = value; *child = NULL; return 1; }
if (value < node->value[1]) { pos = 0; } else { for (pos = node->count; (value < node->value[pos] && pos > 1); pos--) ; if (value == node->value[pos]) { printf("The duplicates are not allowed"); return 0; } } if (setValue(value, pvalue, node->link[pos], child)) { if (node->count < MAX) { insertNode(*pvalue, pos, node, *child); } else { splitNode(*pvalue, pvalue, pos, node, *child, child); return 1; } } return 0;}
void insert(int value) { int flag, i; struct BTree *child;
flag = setValue(value, &i, root, &child); if (flag) root = createNode(i, child);}
void search(int value, int *pos, struct BTree *myNode) { if (!myNode) { return; }
if (value < myNode->value[1]) { *pos = 0; } else { for (*pos = myNode->count; (value < myNode->value[*pos] && *pos > 1); (*pos)--) ; if (value == myNode->value[*pos]) { printf("%d is found", value); return; } } search(value, pos, myNode->link[*pos]);
return;}
void traversal(struct BTree *myNode) { int i; if (myNode) { for (i = 0; i < myNode->count; i++) { traversal(myNode->link[i]); printf("%d ", myNode->value[i + 1]); } traversal(myNode->link[i]); }}
int main() { int value, ch;
insert(10); insert(20); insert(30); insert(40); insert(50); insert(60); insert(70); insert(80); insert(90); insert(100);
traversal(root);
printf(""); search(100, &ch, root);}The output of this C code will be: 10 20 30 40 50 60 70 80 90 100 100 is found
In the above program, we are creating a node for the B tree using struct BTree*createNode(int value, struct BTree *child) {. The insertion will process using the void insertNode() method, and for splitting the node for searching, we will use the void spitNode() method. We will then set the value of each node of the tree using the setNode() method and then insert the values. The tree will then search for the input value given by the user using the void Search() method. Hence, if the item is found, the return output will be – The element is found; otherwise not found.
Conclusion
In the above article, we have discussed B Tree in detail. B-tree is also a self-balancing tree allowing each node multiple keys and offspring. It is the binary search tree in a more generalized version. We have also talked about the properties and applications of the B tree along with various operations on the B tree, such as searching, traversal, insertion, deletion, etc.
Contributed by-Megha Chadha
FAQs
What is a B tree in Data Structure?
A B-tree is a self-balancing search tree data structure that maintains sorted data and allows for efficient insertion, deletion, and retrieval operations. It is commonly used in databases and file systems due to its ability to handle large amounts of data and maintain balanced performance.
What are the advantages of using B-trees?
B-trees offer several advantages. They provide efficient search, insertion, and deletion operations in logarithmic time complexity. B-trees are also self-balancing, ensuring that the tree remains balanced regardless of the order of the input data. Moreover, B-trees are suitable for disk-based storage systems, as they minimize the number of disk accesses required to perform operations.
How does a B-tree differ from a binary search tree?
Unlike a binary search tree that allows only two children per node, a B-tree can have multiple children per node. B-trees are also self-balancing, while binary search trees are not. The balancing property of B-trees helps maintain optimal performance by ensuring that the height of the tree remains balanced even with frequent insertions and deletions.
What is the degree of a B-tree?
The degree of a B-tree refers to the maximum number of children each node can have. For example, a B-tree of degree 3 (also known as a 2-3 tree) can have at most 3 children per node. The degree determines the number of keys a node can hold, which affects the height and overall structure of the tree.
How is data stored in a B-tree?
In a B-tree, data is stored in the leaves of the tree. Each leaf node contains data elements along with their associated keys. The internal nodes of the B-tree act as indexes or guides to navigate through the tree and locate the desired data in the leaf nodes efficiently.
