
Data Mining in E-commerce: Frequent Itemset Mining, Association Rules, and Apriori Algorithm Explained
The rapid upsurge in the e-commerce domain has led to vastly increased data accumulation. Businesses have been using frequent itemset mining, a popular data mining technique to find problems, patterns, correlations, and trends from such data to predict user behaviour and thereby make relevant business decisions. The article explores the concepts of frequent itemset mining, association rules, and apriori algorithms in data mining to help you understand how data mining in e-commerce works.

Read more about data mining.
Frequent Item Set Mining
Frequent item set mining is a market basket analysis methodology that helps to find patterns in the shopping behaviours of users across different shopping platforms. These relationships are represented in the form of association rules. Frequent element set or pattern mining is widely used due to its wide applications in pattern mining, correlations, and constraints that are based on frequent patterns, sequential patterns, and many other data mining tasks. Specifically, this technique is used to find sets of products that are frequently bought together.
Best-suited Data Mining courses for you
Learn Data Mining with these high-rated online courses

Association Rules
Association Rules search for frequent patterns, associations, correlations, or causal structures between sets of items or objects in transaction databases, relational databases, and other available information repositories.

Applications
- Analysis of banking data
- Cross-marketing (e.g. put chocolates next to the strawberries)
- Catalog design
Association rules help to predict the occurrence of one item based on the occurrences of other items in a set of transactions.
Examples
- People who buy bread will also buy milk
- People who buy milk will also buy eggs
- People who bought soda will also buy potato chips
- People who buy bread will also buy jam

 Read Later
Read Later
Let’s understand this better with a very popular case study –
Some time back, Wal-Mart decided to combine data from customers' loyalty cards with their point-of-sale system. This data offered them demographic data about customers and information about where, when, and what the customers bought. Once combined, the data were extensively mined, and many relationships appeared. Some of these were obvious, such as – people who buy gin might also buy tonic, or they buy lemons too often.
However, an extremely unexpected relationship appeared; this is interesting – On Friday afternoons, the young Americans who buy diapers also have a predisposition to buy beer. No one ever predicted such an outcome, as this is a very irrelevant combination. They dug the data deeper and concluded that modern-day parenting is stressful and consumption of light alcohol like beer proved to be a stress reliever. Wal-Mart implemented this combination, and it brought some great revenues for the store.
This is the perfect example showing how association rules in data mining contribute towards better business decision-making.
Let’s move on to the Apriori algorithm now and understand how it’s helpful in mining frequent item sets and relevant association rules.


Apriori Algorithm
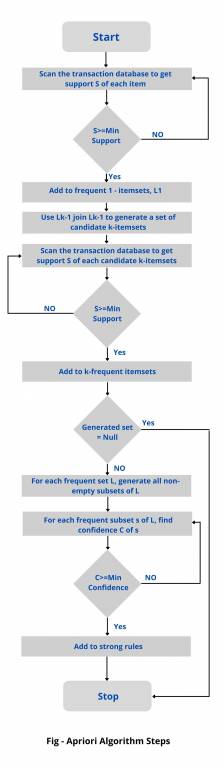
The Apriori algorithm was the first algorithm that was proposed for frequent mining of item sets. It was later improved by R Agarwal and R Srikant and was named Apriori. This algorithm uses two steps, ‘join’ and ‘prune’ to reduce search space. It is an iterative approach to discovering the most frequent itemsets.
The Core of the Apriori Algorithm
- Uses frequent sets (k-1) to generate candidates for frequent k-items
- Uses database scanning and pattern-matching
- Counts for candidate item sets
Apriori algorithm is a sequence of steps, including –
Join step – This step generates a (K + 1) set of elements from K sets of elements by joining each element to itself.
Pruning step – This step analyzes the count of each item in the database. If the candidate item does not meet the minimum support, it is considered rare and therefore removed. Pruning is done to reduce the size of the candidate itemsets.

Apriori step – The Apriori Algorithm is a sequence of steps to follow to find the most frequent set of elements in the given database. This data mining technique follows the joining and pruning steps iteratively until the most frequent set of items is achieved. In the problem, the user gives or assumes a minimum support threshold.
Possible Methods to Improve the Efficiency of Apriori Algorithms –
Item count based on hash tables – A k-itemset whose account in its bucket is below a threshold cannot be frequent and thus should be removed
Transaction reduction – A transaction that does not contain any frequent k-itemset is useless in subsequent crawls and hence must be removed
Partitioning – Any item set that is potentially frequent in a database should be prevalent in at least one partition of the database data to improve Apriori efficiency
Sampling – Mining a subset of the data, a smaller support threshold, and a method to determine completeness
Dynamic itemset count – Add new candidate item set only when all its subsets are frequent estimates
Conclusion
Frequent itemset mining, association rules, and the Apriori algorithm are fundamental concepts in data mining that play a crucial role in uncovering valuable insights from large datasets. Frequent itemset mining allows us to identify patterns of frequently occurring items, while association rules help us understand the relationships and dependencies between these items. The Apriori algorithm has become a cornerstone with its efficient approach to finding frequent item sets and generating meaningful rules.
Hope this article gives you an idea of how data mining and its components, like frequent itemset mining, association rules, and Apriori Algorithm in data mining, can help to make business decisions ideal for both businesses and consumers.

Rashmi Karan is a writer and editor with more than 15 years of exp., focusing on educational content. Her expertise is IT & Software domain. She also creates articles on trending tech like data science,