
Data Preprocessing in Data Mining – The Basics
If you are someone working with big data or huge volumes of raw data, you know the importance of data preprocessing in improving data quality since the obtained raw data is usually inconsistent, incomplete, and noisy. Before training an algorithm with our training data, we must make sure that it is in the proper form. Data preprocessing in data mining is the key step to identifying the missing key values, inconsistencies, and noise, containing errors and outliers.

Without data preprocessing in data science, these data errors would survive and lower the quality of data mining. Data pre-processing comprises multiple processes, including data integration, data conversion, and other series of processing processes after the data cleaning is complete. Data pre-processing is the preliminary step to clean the data, improve the data quality, and also adapt better data mining techniques and tools.
To learn more about data mining, read – What is Data Mining
Data pre-processing mainly involves the below steps –
- Data Quality Assessment
- Data Cleaning
- Addressing Data Duplication
- Data Integration
- Data Transformation
Also Read – Data Mining Functionalities – An Overview
Data Pre-Processing Methodology:
Below are the data preprocessing methods often used by data engineers and data scientists –

Data Quality Assessment
Measuring the data quality is the primary step to see if it meets the desired and defined standards. Data quality is rated as per the defined metrics of data quality dimensions, which are –
- Completeness of data
- Validity of data
- Timeliness of data
- Consistency of data
You May Like – Key Data Mining Applications, Concepts, and Components
Data Cleaning
Data cleaning tools allow us to fix specific errors that occur in the data set we are dealing with and that negatively affect machine learning. The most common defects that are usually treated with these tools are:
Absence of values – The absence of values is one of the most common errors while dealing with huge data sets. This can happen for a number of reasons, such as errors while copying or moving data, no actual measurement of data values, errors while pasting the data, etc. such errors can prevent the algorithms to train accurately. To solve this problem there are several approaches that can be used depending on the data we are treating:
Linear Interpolation – If you are dealing with temporary data, you can estimate the missing value. You can take into account the linearly spaced values between the two nearest defined data points.
Fill with a fixed value – You can fill in a constant, a mean, the mode, or even 0.
You May Like – Data Transformation in Data Mining – The Basics
Fill using regression – Missing outcomes can be handled either by including the data vector or modeling the input variables.
Consider void as a category – If the variable where data is missing is categorical, we can add an extra category that brings together all those whose field is empty.
Delete the complete record – In the event that none of the previous techniques is adequate to fill in the empty values, sometimes it is decided to discard that record and work exclusively with those that are complete.
Moreover, to handle missing data, it becomes imperative to identify the causes of missing data to prevent those avoidable data problems. To handle missing data, you can either fill in the missing values manually or automatically fill in the word “unknown” or “NA”.
Must Read – Data Cleaning In Data Mining – Stages, Usage, and Importance
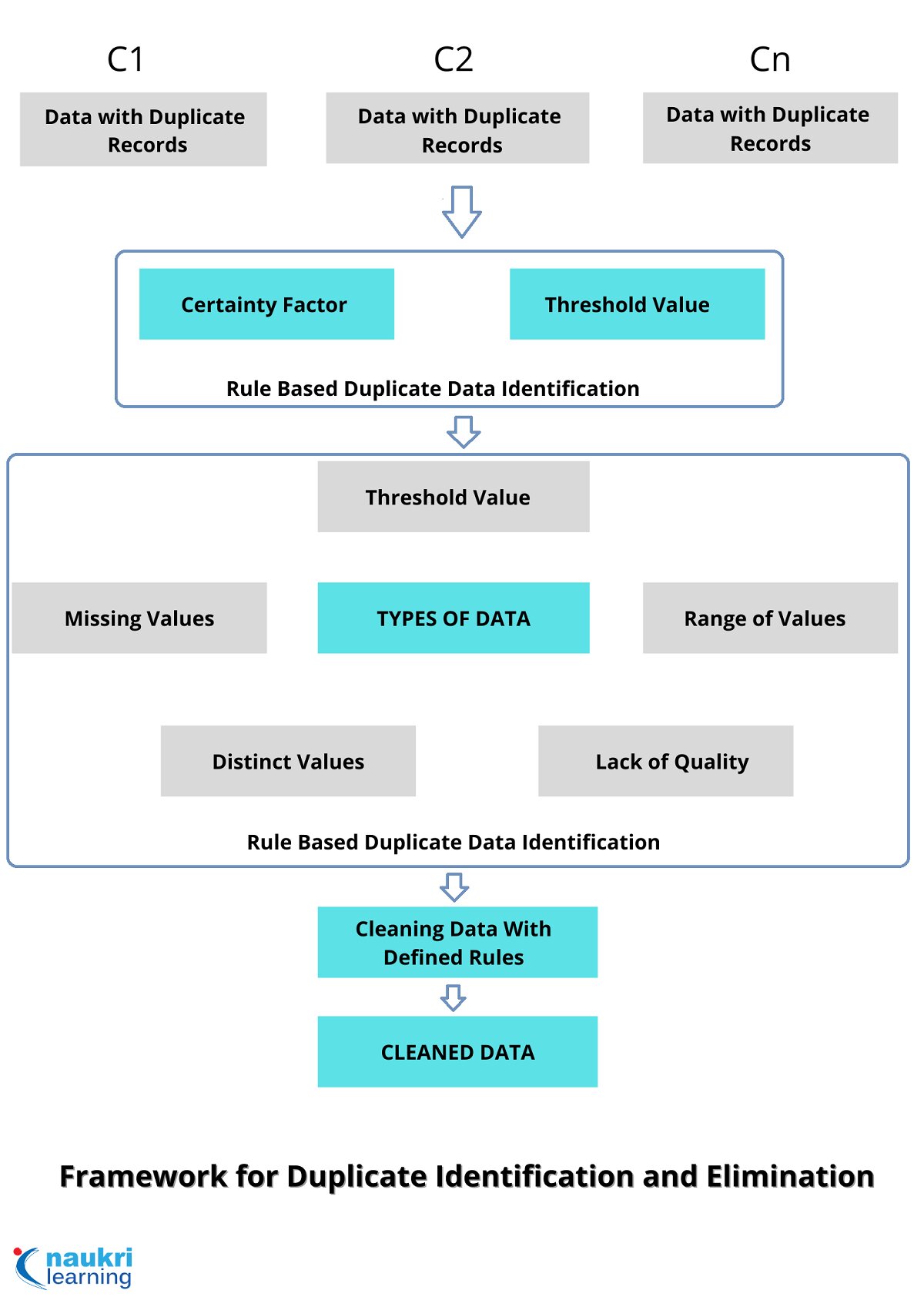
Addressing Data Duplication
Data duplication is a problem, at both individual and business levels as it may lead to time waste and even lost business opportunities. Data duplication is often difficult to deal with and takes a lot of time to correct.
A common example of a typical data duplication problem includes multiple sales calls to the same contact. Possible solutions involve software updates or changing the way your business handles customer relationship management. Without a specific plan and the right software, it is difficult to eliminate data duplication.
Top Data Mining Algorithms You Should Learn
Another common source of data duplication is when a company has an excessive number of databases. As a part of your data pre-processing, you should periodically review opportunities to remove some of those databases. If not done, data duplication is likely to be a recurring problem that you are going to have to deal with repeatedly.
Must Explore – Data Mining Courses
Data duplication can be classified depending on the nature of the data in –
Deduplication – Data from the same database.
Record linking – Data from different databases, each of which does not have duplicate records of its own.
Entity resolution – Data from different sources and, in addition, there are duplicates within each of them.
Read More – Statistical Methods Every Data Scientist Should Know
Data Integration
By combining data from multiple data sources and storing it uniformly, the process of building a data warehouse is actually data integration. The data required for data mining is often spread across different data sources. Data integration is the process of merging and storing data sources in a consistent data store.
In data integration, the ways of representing entities from multiple data sources in the visualization world are different and there may be mismatches. The problem of entity recognition and attribute redundancy must be considered to transform and refine the source data at the lowest level.
Must Read – Powerful Data Mining Tools for Your Data Mining Projects
Data Transformation
The process of data transformation involves smoothing, aggregation, normalization, minimum and maximum normalization, and so on.
Data transformation stages –
Smoothing – Involves removal of removed noise in data through processes like binning, regression, and grouping
Feature construction – Feature construction involves building intermediate features from the original descriptors in a dataset
Aggregation – This process includes summarizing or aggregating the data. It is a very popular technique used in sales.
Normalization – Normalization helps in scaling data attributes in proportion
Discretization – Refers to converting huge data sets into smaller ones and converting data attribute values into finite sets of intervals and associating every interval with specific values
Data Reduction
The data reduction process helps to reduce data volume to reduce storage space. Data reduction process includes –
Dimensionality reduction – Dimensionality reduction contributes towards reducing the number of random variables in a data set using a set of principal variables without losing its original characteristics. If the data is highly dimensional, there arises the issue of “Curse of Dimensionality”.
Numerosity reduction – Numerosity reduction helps to reduce the data size by reducing the data volume without losing any data.
Data compression – The compressed form of data is called data compression and it is divided into lossless and lossy. In the case of lossless compression, there is no loss of data, while in lossy compression, the unnecessary information is removed.
Best-suited Data Mining courses for you
Learn Data Mining with these high-rated online courses

Conclusion
The high-quality data input ensures the best quality outcomes and this is why Data Preprocessing in Data Mining is a crucial step towards an accurate data analysis process. It is a tedious task and often consumes over 60% of the total time taken in a data mining project. You can do this process manually and even take the help of data processing tools like Hadoop, HPCC, Storm, Cassandra, Statwing, CouchDB, Pentaho, etc. to improve the efficiency of the process and reduce time. The choice is yours.
If you have recently completed a professional course/certification, click here to submit a review.

Rashmi Karan is a writer and editor with more than 15 years of exp., focusing on educational content. Her expertise is IT & Software domain. She also creates articles on trending tech like data science,