
Decision Trees in Data Mining
A Decision Tree is a widely applied data mining method for classification and prediction. It functions as a flowchart in which data is divided into branches based on conditions, resulting in varying outcomes. Every decision point, or node, is a question, and every branch is an answer. The process is repeated until the final decision (or prediction) is made at the leaf node. Learn more about decision trees in data mining, their types, components, functions, and the advantages of using decision trees in data mining.

Courses ALERT: Explore FREE Online Courses by top online course providers like Coursera, edX, Udemy, NPTEL, etc., across various domains, like Technology, Data Science, Management, Finance, etc., and improve your hiring chances.
What is a Decision Tree in Data Mining?
A decision tree is a type of algorithm that classifies information so that a tree-shaped model is generated. It is a schematic model of the information representing the different alternatives and the possible results for each chosen alternative. Decision trees are a widely used model because they greatly facilitate understanding of the different options.
To learn more about data mining, read – What is Data Mining
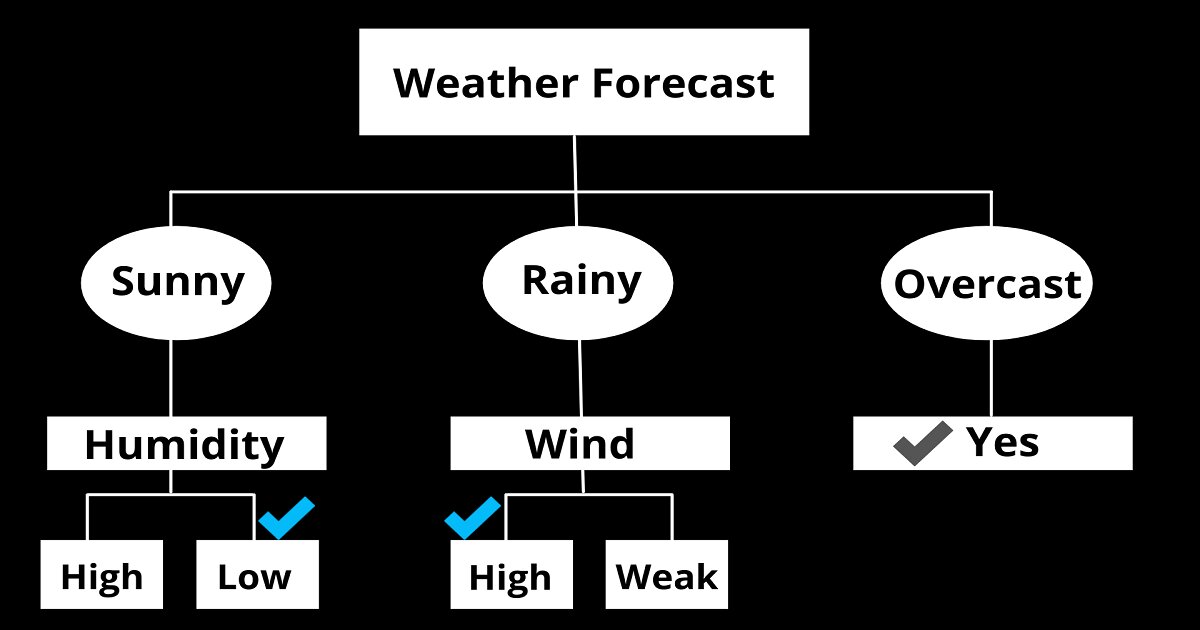
The above example of a decision tree helps to determine if one should play cricket or not. If the weather forecast suggests that it is overcast then you should definitely play cricket. If it is rainy, you should play only if the wind is weak and if it is sunny then you should play if the humidity is normal or low.

 Read Later
Read LaterBest-suited Data Mining courses for you
Learn Data Mining with these high-rated online courses

Decision Tree Components
The decision tree is made up of nodes and branches,, which assist in segmenting complicated issues into manageable, organized pieces. Every element serves a particular purpose in directing decisions and predictions.
1. Nodes – The Decision Points
Nodes are locations within the tree where a decision is made. There are various forms of nodes, each with a different function:
- Decision Nodes: Symbolize a decision to be made. These are typically represented as squares. Example: "Should we grant a loan?"
- Probability Nodes: Symbolize uncertain results, typically represented as circles. These indicate various possible outcomes based on chance. Example: "Will the stock price rise or fall?"
- Terminal Nodes (Leaf Nodes): Indicate the ultimate result or choice. These are typically represented as triangles or rectangles. Example: "Loan approved" or "Loan rejected."
2. Branches – The Connecting Paths
Branches are the lines that link nodes and indicate the direction of decisions. There are two types of branches:
- Alternative Branches: All the branches describe an alternative choice depending on a decision. One may be "Expand to City A" in a company expansion scenario, for instance, and another one will be "Expand to City B."
- Rejected Branches: Such branches describe all those paths not chosen. These display outcomes which were thought but finally rejected.


Types of Decision Trees in Data Mining
Decision tree in data mining is mainly divided into two types –
1. Categorical Variable Decision Tree
A categorical variable decision tree comprises categorical target variables, which are further bifurcated categories, such as Yes or No. Categories specify that the stages of a decision process are categorically divided.
2. Continuous Variable Decision Tree
A continuous variable decision tree has a continuous target variable. One example to understand this could be – the unknown salary of an employee can be predicted bases on the available profile information, such as his/her job role, age, experience, and other continuous variables.
Must Explore – Data Mining Courses
Functions of Decision Tree in Data Mining
For greater precision, multiple decision trees are combined with e 4 assembly methods.
- Bagging or Assembly – This method creates several decision trees as a resampling of the source data, and then the tree that denotes that the best results should be used.
- Random Jungle Sorter – Multiple decision trees are generated to increase the sort rate and efficiently separate data.
- Expanded Trees – Multiple trees are created to correct the errors of the last one with respect to the first.
- Random Forest or Rotation Forest – Decision trees created in this scenario are analyzed based on a series of main variables.
Decision Tree Algorithms
Although there are various algorithms used to create decision trees in data mining, the most relevant are the following:
- ID3: decision trees with this algorithm are oriented towards finding hypotheses or rules in relation to the analyzed data.
- C4.5: decision trees that use this algorithm focus on classifying data, in this way; they are associated with statistical classification.
- ACR: the decision trees of this algorithm are focused on avoiding future problems, as they are used to detect the causes that generate the defects.

Advantages of Using Decision Trees in Data Mining
Decision trees in data mining provide various advantages for analyzing and classifying the data in your information base. However, experts highlight the following –
Ease of Understanding
Because data mining tools can visually capture this model very practically, people can understand how it works after a short explanation. Having extensive knowledge of data mining or web programming languages is unnecessary.
Does Not Require Data Normalization
Most data mining techniques require data preparation for processing, that is, analysing and discarding data in poor condition. This is not the case for decision trees in data mining, as they can start working directly.
Handling of Numbers and Categorized Data
One of the main differences between neural networks and decision trees is that the latter analyze many variables.
While neural networks focus on numerical variables, decision trees encompass numerical and nominal variables. Therefore, they will help you to analyze a large amount of information together.
“White Box” Model
In web programming and data mining, the white box model brings together a type of software test in which the variables are evaluated to determine the possible scenarios or execution paths based on a decision.
Uses of Statistics
Decision trees and statistics work hand in hand to provide greater reliability to the model that is being developed. Since various statistical tests support each result, the probability of any of the options analyzed can be known exactly.
Handles Big Data
Do you have large amounts of information to analyze? With decision trees, you can process them seamlessly. This model works perfectly with big data, using computer and web programming resources to manipulate each point of information.

Conclusion
You must add value to your data to improve your processes and be more efficient in the industry. With the help of a decision tree in data mining, you can carry out an adequate analysis and classification to transform your information into new processes and strategies.

Comments
(1)
Rashmi Karan is a writer and editor with more than 15 years of exp., focusing on educational content. Her expertise is IT & Software domain. She also creates articles on trending tech like data science,