
How to improve machine learning model
After building machine learning the work is not over!! The next task is to improve machine learning model. But this is a challenging task. Some of you must have faced this challenge also. But this blog will help you in creating a robust machine learning model if you will follow these below techniques.

Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
Table of contents
- Adding more clean and relevant data
- Handling missing data and outliers
- Trying multiple algorithms
- Cross-validation
- Hyperparameter tuning
- Dimensionality Reduction
- Applying Ensemble Technique

1. Adding more clean and relevant data
Let’s suppose if you are preparing a student to perform well in the exams. In that case, you have to provide him with sufficient study material so that he can learn better and correspondingly perform well in the exams. In the same way when a machine learning model(student) is provided with more data(study material) then the model(student) will perform better when test data(exam) is given. The more data provided to the model, the more accurate will be the model.
Sample size should be increased by locating data sources (open source). If possible try to match your data with new entries. The below diagram shows that if the model is trained on less data then the model won’t be able to distinguish between dog and muffin.
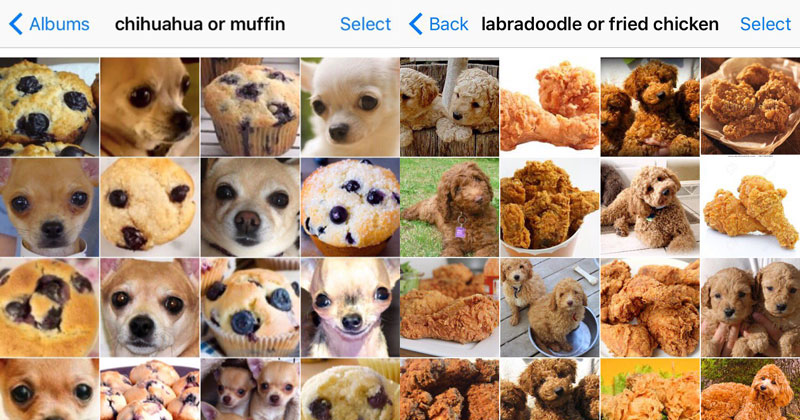
Else web scraping can also be tried. Now, what is web scraping? Web scraping means retrieving data from internet sources like websites. Artificial intelligence automation methods are used to get thousands or even millions of data sets in a smaller amount of time and are then restructured.

 Read Later
Read Later
Also read: How to choose the Value of k in K-fold Cross-Validation
2. Handling missing data and outliers
When we collect data from different sources, sometimes the data is not clean means it has missing values and has outliers. This will ultimately lead to low accuracy or sometimes we get biased accuracy. So, it is important to treat missing and outlier values well. The below diagram shows some missing values.
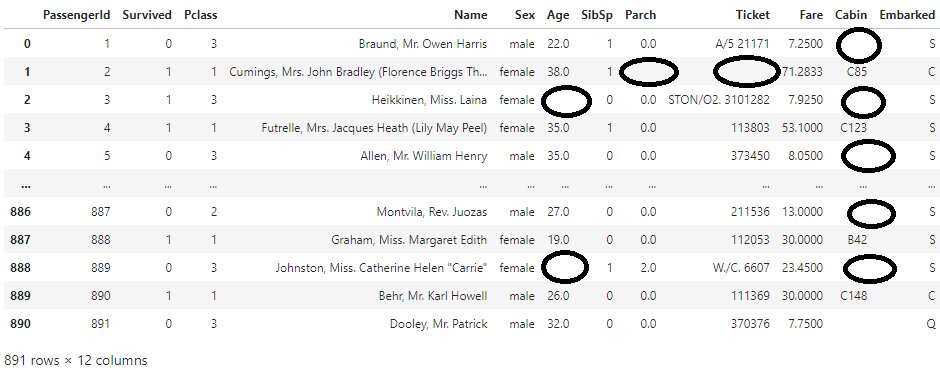
How to handle missing values:
1. Removing the column having missing value:
If any particular column is having many missing values then deletion is one option. But that may not be the most effective option. For eg. , if too much information is discarded, it may not be possible to complete a reliable analysis.
2. Mean/Median/Mode Imputation
In this method, any missing values in a given column are replaced with the mean (or median, or mode) of that column.
3. Regression Imputation:
This approach replaces missing values with a predicted value based on a regression line.
Outliers:
An outlier is a value that deviated significantly from the rest of the values. These values appear as a result of measurement or execution errors. So it is ‘noise’ data that needs to be removed.
3. Trying multiple algorithms
The ideal approach to achieve good accuracy is by selecting the right machine learning algorithm. But doing it is not an easy thing. This comes with experience.
The suitable model selection is based on the dataset chosen. Algorithm A1 works best with dataset d1 but does not give good accuracy when applied to dataset d2. Hence, we should try applying all relevant models and check the performance accordingly. It depends on the data, For e.g.-your data is linear then linear regression may work well.
If tuning of parameters is more important then you can go for Algorithms like SVM, which involves tuning of parameters, Neural networks with high convergence time, and random forests, which need a lot of time to train the data.

Source: Scikit learn algorithm cheat sheet
4. Cross-validation
Cross-validation is a model evaluation and training technique that splits the data into several partitions and the algorithms are trained on these partitions. The main purpose of cross-validation is to assess how the model will perform on unknown data. The idea is to change the test and training data on every iteration. Ultimately is it used to improve machine learning model.
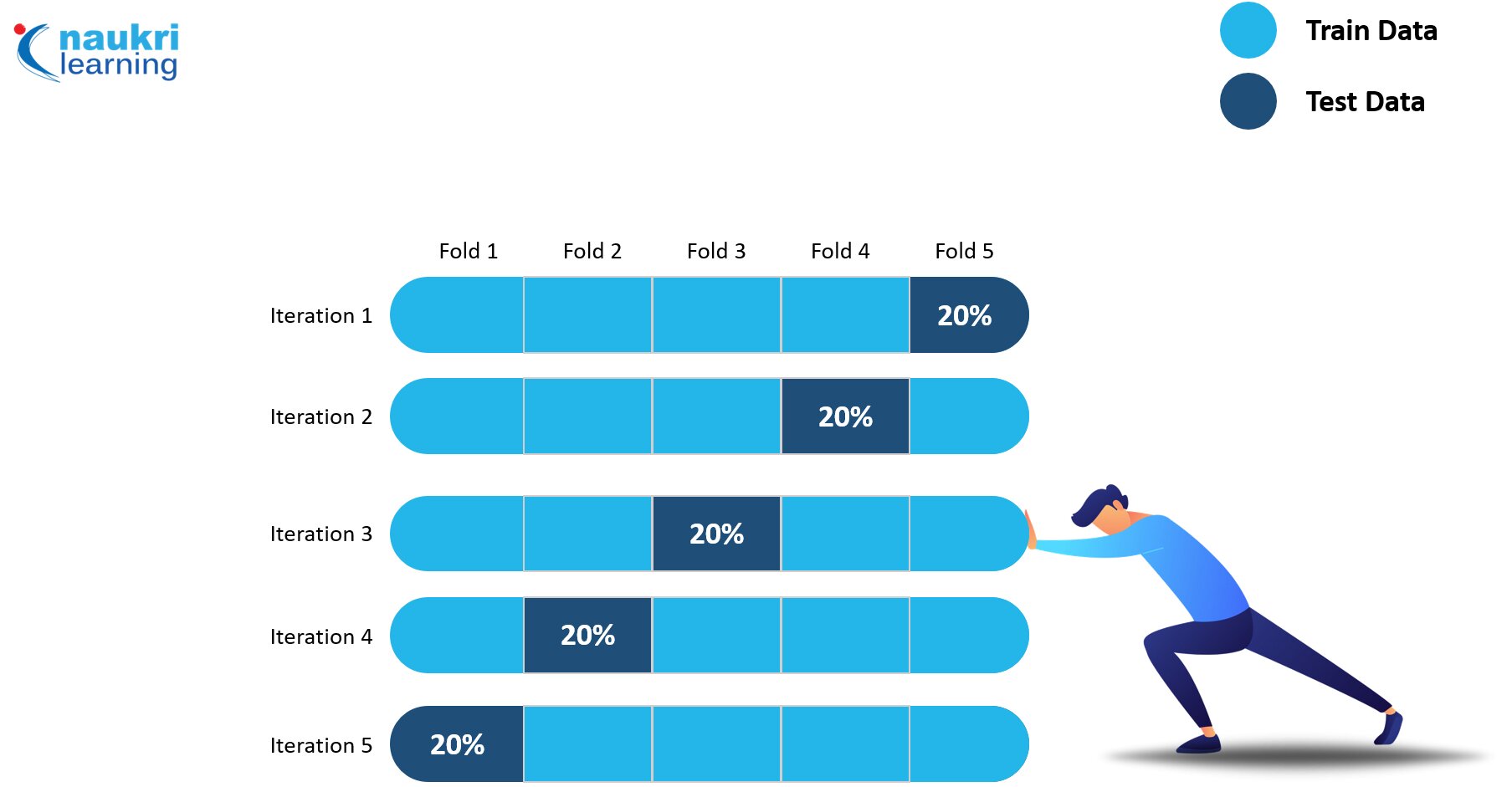
Note: It can be an effective tool for training models with a smaller dataset.
Different cross-validation techniques:
- Leave one out cross-validation (LOOCV)
- k-fold cross validation
- Stratified k-fold cross validation
- Leave p- out cross-validation
- Hold out method
5. Hyperparameter tuning
In machine learning performance of an algorithm is driven by parameters. We can change the values of parameters according to the need.
In order to improve machine learning model, parameter tuning (to find the optimum value for each parameter) is used.
Tuning here means a change in the parameter value.
A good understanding of the parameters and their individual impact on the model is required for tuning these parameters. You can repeat this process with a number of well-performing models.
For example: In a Decision tree, we have various parameters like min_sample_split min_sample_leaf Max leaf nodes max_depth of a tree, and others. Intuitive optimization of these parameter values will result in better and more accurate models.
Note: We can use different automated libraries for doing automated hyperparameter tuning like Optuna, HyperOpt, SmartML, SigOpt, etc.
6. Dimensionality Reduction
Firstly let’s understand what is a dimension?
Dimension(called features) here means input features, columns, or variables, present in a given dataset. Some datasets contain a large number of many parameters which leads to complex predictive modeling tasks. So doing visualization or making predictions becomes a difficult task if features are in large numbers. So we need to reduce the number of features.
The process of reducing high dimensional space(or high dimensional data) to low dimensional space is called dimensionality reduction(DR).In simple words, many features are reduced to a less number of features but without losing information.
The dimensionality reduction technique solves the classification and regression problems.
- Signal processing
- Speech recognition
- Bioinformatics, etc.
Other applications are in data visualization, cluster analysis, etc.
Curse of dimensionality:
Generally, it is considered that more dimensions(features) mean better training of the model but in reality, it is true to some extent. Increasing features after a certain limit starts showing errors due to the higher possibility of noise and redundancy in the real-world data.
Curse of dimensionality scenario:
Let’s suppose you lost your phone on a line, then it will be easy to find it. But if you lost it in a plot of 200 yards(2-D). Then the complexity of finding it will increase. And suppose you lost it in 3D space then it will be more complex to find it. In simple words, the complexity increase as the dimensions increase.
The methods to reduce the dimensions (features) of training data are:
- Low variance
- Factor analysis
- Removing high correlated features
- Backward/ forward feature selection and others.
This is one of the very important topics in machine learning.
Let’s assume one scenario that you want to invest in a company ABC. Will you depend on one person’s advice or you will seek advice from different experts in the industry. If you want more accurate results you will consult different people and considering their advice you will take the final decision. In the same way, when you want accurate results in machine learning, you can implement different models(called weak learners) and then average their accuracies and get the final result as shown in fig below. Using different algorithms actually helps to improve machine learning model.
7. Applying Ensemble Technique
So this technique of combining the result of multiple weak machine models is called an ensemble Learning
This can be achieved through many ways: Bagging and Boosting
Ensemble learning:
It is a general meta approach to machine learning that seeks better predictive performance by combining the predictions from multiple models

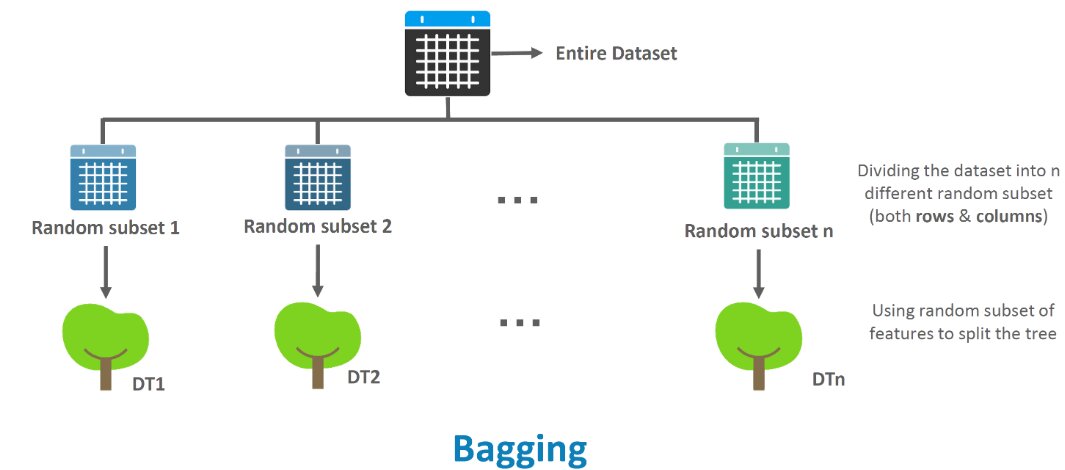
Bagging (Bootstrap Aggregating):
- We will be giving different subsets of datasets to different models and the data in different subsets could be repeated also.
- All subsets are used to train a different model. The outputs of all the models are combined by averaging (in the case of regression problem) or voting (in the case of classification problem) in a single output.
When to use bagging:
Bagging is only effective in case of unstable (i.e. a small change in the training set can cause a significant change in the model) non-linear models.
Boosting:
Boosting is an iterative technique in which the weight of observation is adjusted based on the last classification. Assigning of weights depends on the ‘correct classification’.In case of incorrect classification and vice versa.

Then a succession of models is built iteratively, each one is trained on that particular dataset in which points were misclassified by the previous model and are given more weight before passing on the next succession model as shown in fig below.
Endnotes
In this blog you learned about different techniques to improve machine learning model.
If you liked this blog then hit the stars below.
