
Cross-validation techniques

What is Cross-validation?
Cross-validation is a resampling method used for estimating the skill of machine learning models. Cross-validation is largely when it is necessary to estimate the accuracy of the performance of a predictive model.
After training the model it cant be assumed that the model is going to perform well on unseen data. We need to validate our model. This process of verification is called cross-validation.
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
Table of content
1. Understanding Cross-validation
2. Train/test split vs Cross-validation
3. Cross-validation techniques:
Understanding Cross-validation
Let’s first understand
Machine Learning Model training and testing steps:
- Train the model using a labeled data set.
- Your model will return the results back.
- Measure the accuracy of a model by testing the model on some data.
Now, these training/testing steps can be performed as:
Scenario1: Training and testing data are the same
Suppose you are preparing a student for a maths exam. You prepared him for 100 questions and the exam will come from those 100 questions only and then you try to measure his mathematical skills. What if he gets 100/100. So this is not the right criteria to check his skills.

In the same way when you use the same data for training and testing your model then you will get biased results. You may achieve very good accuracy but does this mean that your model is well trained, and it is the best model?
The answer is No. Training of your model is done on the given data(which was known to the model already). But if you expose the model to completely new data, it might not able to predict with unbiased accuracy. This problem is called over-fitting.
Scenario 2: Splitting training and testing dataset
So then the second option is to split the samples into training and test data sets so for example out of 100 samples, 80 will be used for training and 20 samples for testing.

Now fit this in the same example we were discussing.
That student is prepared on 70 questions and has not seen these 30 questions which are good that way you can measure the skills. In machine learning, we train the model on the data and use the same data for testing. A model would have a perfect score but would fail to predict anything useful on yet-unseen data.
One way to overcome this problem is to separate some data as testing data. When training is done, the test data(unseen data) is used to test the performance of the learned model.
Also explore: How to evaluate the machine learning model.
Also explore: How to improve the machine learning model
Train/test split vs Cross-validation
Train/test split:
Suppose we want to classify the network traffic we will:
- Use different machine learning algorithms
- Evaluate the performance of each of them.
For example, we implemented the following algorithm
- Logistic regression: Suppose it gives me an accuracy score of 91%.
- SVM: It gives an accuracy of 56%.
- Random Forest: It gives an accuracy of 97%.
As the distribution of samples in X_train and X test is not uniform. So whenever we’ll execute these algorithms the score will get changed. Now, why did the score get changed? The reason is, on re-execution, the samples in X_train, X_test,y_train,y_test got changed. Now, what’s the solution? What accuracy we should show our stakeholders? Performing cross-validation will help in this case.
If you want to know more about train test split explore train test split
Must explore:Difference between Accuracy and Precision
Also explore:How to Improve the Accuracy of Regression Model?
Cross-Validation:
This problem of train/test split is overcome by cross-validation :
- Splitting the dataset into groups of train/test splits.
- Running different iterations with different training and test data in each iteration.
- Calculating accuracy score in each iteration.
- Averaging the result.
Let’s try python code:
Importing libraries and loading dataset.
import pandas as pd import numpy as np df= pd.read_csv('cancer_dataset.csv') df
### Independent And dependent features X=df.iloc[:,2:] y=df.iloc[:,1] X=X.dropna(axis=1) X
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=4)
Cross-validation techniques:
1. Leave one out cross-validation(LOOCV)
When P = 1
The function approximator is trained on the whole data except for one point and a prediction is made for that point. That means if we have N data points the function approximator is trained on all the data except for one point(N-1) and a prediction is made for that point. Accuracy is computed for each iteration. The average accuracy is computed and used to evaluate the model.

Advantage of Leave one out cross-validation:
- All data points are taken as test data once hence it has a low bias(this means it will work well for training data but not for test data)
Disadvantage of Leave one out cross-validation:
- High variation in the testing model as we are testing against one data point.
- High execution time and computation cost as the number of iterations is equal to the number of data points.
2. Leave-p-out cross-validation
This approach separates ‘P’ data points out of training data, i.e.

Where
N-P= training data samples
P=testing samples
N=Data samples
2. k-Fold Cross-validation:
In k- fold Cross-validation the dataset is shuffled in every iteration. So that inputs are completely random and are not biased.
Scenario Example:
Let’s take the previous example to suppose out 100 questions 70 maths questions that you gave this student they were all algebra and now the remaining 30 questions are from calculus so now those questions he has not seen before or he doesn’t have knowledge on that topic then he might not perform well. Now, what to do?
Solution:
Use k-fold cross-validation. By using this technique, now the student will be trained on questions from algebra and calculus and will be tested accordingly.
k–Fold Example:
Take 100 samples as a dataset.
Divide samples into folds so let’s take five folds which means K=5.

So Samples in each fold=Total samples/k =100/5=20
Each sample contains 20 samples and then you run multiple iterations.
Here, we have 5 iterations because k=5, and the testing sample can be anyone of these. Then you find the accuracy score for each iteration. Once you have all the scores, just average them out.
Now, this technique is very good because you are giving a variety of samples to your models. And each data point gets a chance to be in the training and test set exactly once.
Note: Choose the value of ‘k’ such that the model doesn’t suffer from high variance and high bias.
Remark: The choice of k is usually 5 or 10, but there is no formal rule. However, the value of k relies upon the size of the dataset. The runtime of the cross-validation algorithm and the computational cost with large values of k.
Also read: How to choose the Value of k in K-fold Cross-Validation
Advantages of k-fold CV:
It solves the problem of random accuracy means we can achieve a stable accuracy. The model is trained on a dataset that is split into multiple folds. This prevents overfitting the training dataset.
Note-If the dataset is large the cross-validation may not require as the chances of overfitting are less.
Every data sample is a part of the training sample as well as part of the testing sample.
Disadvantages of k-fold CV:
- In case data is an imbalance(in case we have class ‘A’ and class ‘B’then class ‘A’ is there in the training set and class ‘B’ is there in the testing set)it does not work well.
- Training time has increased as now the model is being trained on multiple training sets.
Python Code:
from sklearn.model_selection import KFold from sklearn.linear_model import LogisticRegression model_1=LogisticRegression() kfold_validation=KFold(10)
After importing KFold we have implemented the Logistic Regression algorithm. In this, we have written KFold(10). This means we have divided our dataset into 10 folds.
import numpy as np from sklearn.model_selection import cross_val_score results=cross_val_score(model_1,X,y,cv=kfold_validation) print(results) print(np.mean(results))

We imported cross_val_score to find 10 different accuracy values. But at the last, we need the mean of all the accuracies so we wrote mean(results).
Points to be taken into consideration while using k-fold:
By doing this we can make sure your model’s performance is stable in all folds. If there are spikes of very low or very high scores, then this could be a symptom of other problems like insufficient data distribution in the folds.
In that case, we can use Stratified k-fold cross-validation.
3. Stratified k-fold cross-validation
Stratified k-fold cross-validation is a variation of k-fold cross-validation with an equal proportion of data in all folds. It solves the problem of k fold cross-validation by returning stratified folds: each set contains approximately the same percentage of samples of each target class.
Now if we train our model on the training set and test our model on the test set, we will get a biased accuracy score because an equal proportion of data is not given to the training and testing set.
How stratified cross-validation solves this problem? It distributes the data samples of all classes in an equal proportion as they appear in the population.
Let’s understand with an example of the positive and negative class.
- Suppose we have a dataset of 100 samples.
- split it into training set=80 and test set=20.
- There are two classes positive(0) and negative(1). There are chances that all positives class in the training set and all negatives in the test set. So now we will take 80% of 80 samples and 80% of 20 samples.
Training set: So now we will take 80% of 80 samples and 80% of 20 samples. This will result in 64 negative class(1) and 16 positive class (0) => 64+16=80 samples.

Testing set: So now we will take 20% of 80 samples and 20% of 20 samples. This will result in 16 negative class (1) and 4 positive class(0) i.e. 16+4=20 samples.

Now the samples in the training set and test set, are in equal proportion. Rest it works the same as k-fold cross-validation. This type of train-test-split results in unbiased accuracy.
Python Code:
from sklearn.model_selection import StratifiedKFold skfold=StratifiedKFold(n_splits=5) model=LogisticRegression() scores=cross_val_score(model,X,y,cv=skfold) print(np.mean(scores))
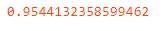
In this, StatifiedKFold is implemented. We did 5 splits of the dataset and then calculated the average mean score.
Endnotes
We saw that cross-validation solves the drawback of train_test_split. We learned different techniques of cross-validation (scenario-based example) with their advantages and disadvantages.
If you liked the blog please hit the stars below.
