
One hot encoding for multi categorical variables

Machine learning models cannot process categorical variables so they need to be converted to numerical variables such that the model is able to understand and extract valuable information. So for implementing any model we first have to preprocess the data. In preprocessing we can perform One hot encoding. That means making the data ready by doing cleaning and conversion properly. We have different types of categorical data. For eg.
- Ordinal categorical data
- categorical data with less number of categories.
- categorical data with a large number of categories.
In the previous blog, we handled categorical data with fewer categories by using One hot encoding and label encoding. In this blog, we will learn how to handle Ordinal categorical data and categorical data with a large number of categories.
Table of contents
Best-suited Tableau courses for you
Learn Tableau with these high-rated online courses

What is encoding?
Encoding is a pre-processing step conversion technique that transforms categorical data into numeric data. The two most popular techniques are Ordinal Encoding and One-Hot Encoding. It is a pre-processing step for making the data ready for other steps like training model, hyperparameter tuning, cross-validation, evaluating the model, etc.

Ordinal Encoding
In this encoding technique order of categorical variables matters.
In this, the integer values have a natural ordered relationship with each other.
By default, integer values are assigned to labels in the order that is observed in the data. But if we want to assign the values in some specific order, it can be specified via Ordinal encoding. Ideally, this should be checked and handled properly when preparing the data. But if no relationship exists between the variables we can go for another encoding technique like one-hot encoding or label encoding.
Let’s understand with an example.
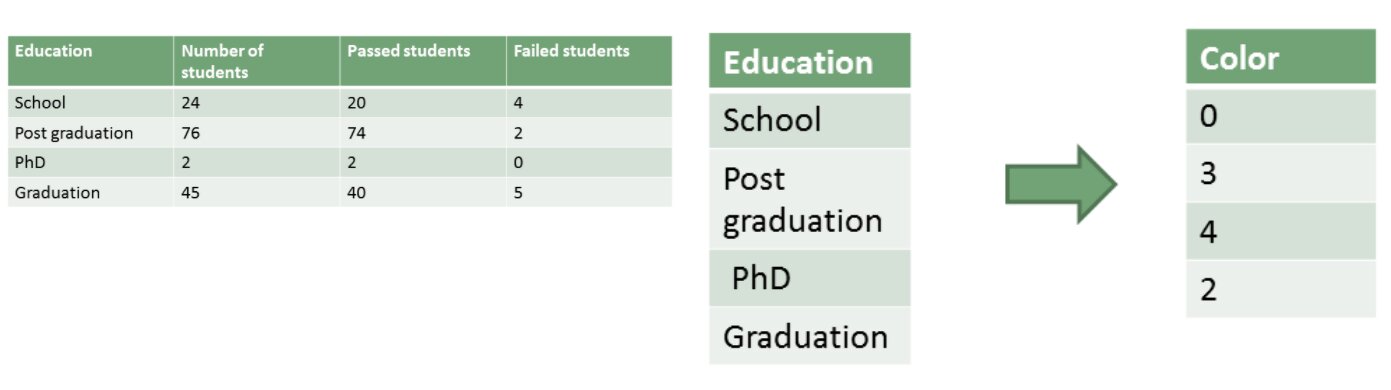
In this, the feature Education has different categories like school, graduation,post-graduation, Ph.D. Suppose different students having different educational backgrounds gave a test Like in the above example the highest degree a person possesses, gives vital information about his qualification. So Ph.D. is the highest qualification among all the educations so it is assigned value 4 and post-graduation have lesser value than Ph.D. so it is given value 3 and so on.
While label encoding is used when no notion of order is present, we just have to consider the presence or the absence of a feature.
One hot encoding
In this encoding technique order of categorical variables does not matters.
Categorical data is converted into numeric data by splitting the column into multiple columns. The numbers are replaced by 1s and 0s, depending on which column has what value. For a detailed explanation, you can click here.
Handling multiple categories
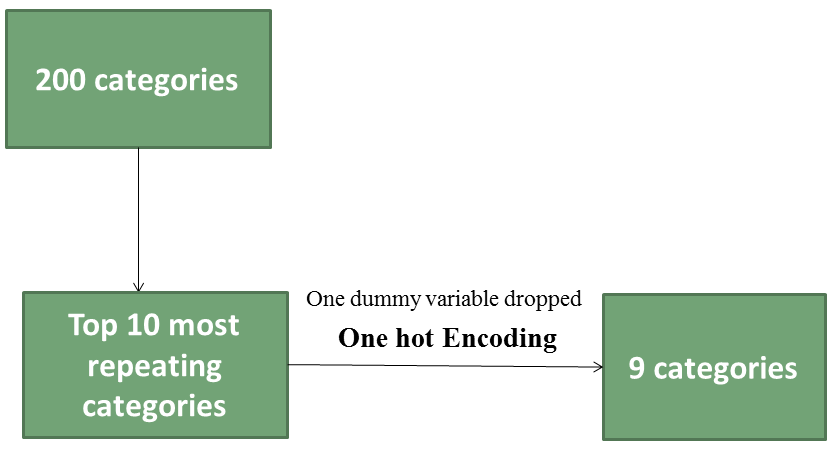
One-hot encoding can be used to handle a large number of categories also. How does it do this? Suppose 200 categories are present in a feature then only those 10 categories which are the top 10 repeating categories will be chosen and one-hot encoding is applied to only those categories. And then one dummy variable can be dropped as explained in the previous blog.

 Read Later
Read Later
One hot encoding(multiclass variables): Python code
Implemented this code using a dataset named mercedesbenz.csv from Kaggle. This dataset contains an anonymized set of variables, each representing a custom feature in a Mercedes car.
1. Importing the Libraries
import pandas as pd import numpy as np
2. Reading the file
df = pd.read_csv('mercedesbenz.csv', usecols=['X1', 'X2']) df.head()
3. Number of different labels
counts = df['X1'].value_counts().sum() counts Output: 4209
Checking the number of different labels in column X1.
4. Checking the top 10 repeating columns
top_10_labels = [y for y in df.X1.value_counts().sort_values(ascending=False).head(10).index] Top_10_labels Output: ['aa', 's', 'b', 'l', 'v', 'r', 'i', 'a', 'c', 'o']
5. Top 10 columns in ascending order
df.X1.value_counts().sort_values(ascending=False).head(10) Output: aa 833 s 598 b 592 l 590 v 408 r 251 i 203 a 143 c 121 o 82 Name: X1, dtype: int64
When you see in this output image you will notice that the aa label is repeating 833 times in the X1 column and going down this number is decreasing.
So we took the top 10 results from the top and we will convert these top 10 results into one-hot encoding and the labels not occurring in this top ten label list will turn into zero.
6. Applying One hot encoding
df=pd.get_dummies(df['X1']).sample(10) df

Now, here we apply the one-hot encoding to all multi categorical variables. You can see how the top 10 labels are now converted into binary format.
Assignment
It’s my suggestion that a simple reading code won’t help you. I suggest you download the mercedesbenz.csv file from Kaggle(freely available). This dataset has many categories. That is why we implemented this dataset. Try to convert other categorical features X2 into numerical features(I have converted only one feature)by using one-hot encoding. Try implementing an algorithm of your choice and find the prediction accuracy.
Endnotes
Congrats on making it to the end!! You should have an idea of how to handle multiclass categories using one-hot encoding and how to use it. We have to first handle categorical variables before moving to other steps like training model, hyperparameter tuning, cross-validation, evaluating the model, etc.
If you liked my blog consider hitting the stars. You can explore my other data science blogs on this page.
