
100+ SQL Interview Questions and Answers for 2023
Here’s the list of top SQL interview questions. Apart from guiding you in your interviews, the detailed answers provided in this article will give you a basic understanding of different concepts related to SQL and MySQL.

You have an interview lined up for an SQL-related job. Great! But are you well prepared to crack it? Do you know enough SQL to clear the interview? Are you wondering what SQL interview questions you will be asked? If you are preparing for an SQL interview, this article will provide you with 100+ most commonly asked SQL and MySQL interview questions. This blog covers both basic and advanced SQL interview questions for freshers and experienced candidates that an interviewer might ask during an interview.
Explore popular Databases Courses
BASIC QUESTIONS TO REVISE CONCEPTS
1. How to CREATE a table in SQL?
To create a table in SQL, you all need is table’s name, the column’s name, the data type of the column, and the size of the table.
Here is the syntax you must follow to create a table in SQL.

Syntax
CREATE TABLE table_name( column_name_1 datatype(size) column_constraints, column_name_2 datatype(size) column_constraints, ….. …..);
Let’s take an example to get a better understanding of creating a table in SQL.
Problem Statement: Create an Employee Table, having column names EmployeeID, Name, Gender, Department, Salary,
CREATE TABLE Employee( EmployeeID int PRIMARY KEY, Name VARCHAR(100) NOT NULL, Gender text NOT NULL, Department VARCHAR(30), Salary VARCHAR (20));
Here is the output.
Output
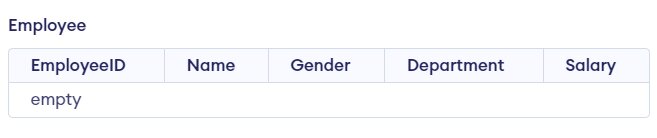
Must Read: How to CREATE a table in SQL?
Now, let’s see how to insert the data into table.
2. How do INSERT data into the table in SQL?
To INSERT the data into the created table, we have to use INSERT INTO clause.
Syntax
INSERT INTO table_name (column_name1, column_name2, …..) VALUES (value1, value2, ……)
Now, let’s insert the data in the above Employee table.
INSERT INTO Employee (EmployeeID, Name, Gender, Department, Salary) VALUES(1001, 'Ajay', 'M', 'Engineering', 45000),(1002, 'Babloo', 'M', 'Engineering', 25000),(1003, 'Chhavi', 'F', 'HR', 35800),(1004, 'dheeraj', 'M', 'HR', 52000),(1005, 'Evina', 'F', 'Marketing', 35800);
Output
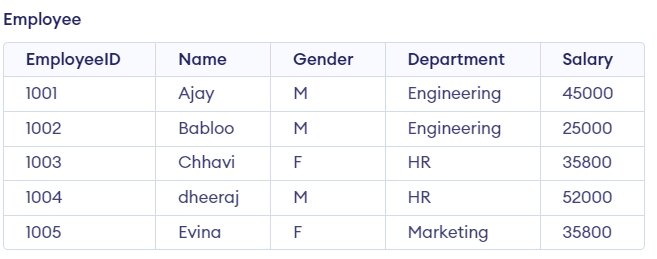
Must Read: How to use INSERT clause in SQL?
3. How to SELECT the record from the table in SQL?
To select the record from the table, we have to use SELECT statement in SQL.
Syntax
SELECT column_nameFROM table_name
Example-1: Print all the record from the Employee Table.
SELECT *FROM Employee;

Example-2: Print the Name and Salary of the employees from the Employee Table.
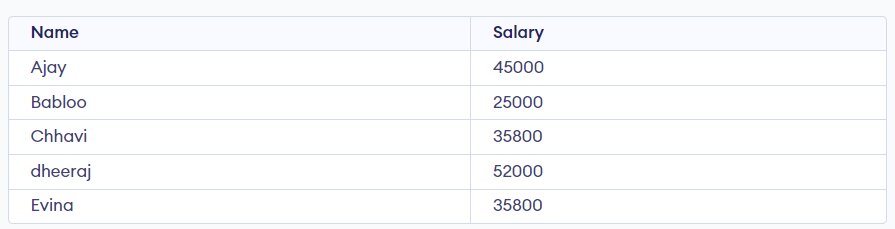
Must Read: How to use SELECT statement in SQL?
4. How to filter rows in a table using the WHERE clause in SQL?
WHERE clause in SQL is used to filter out the records or to specify a condition while extracting the records from a single table or joining multiple tables.
WHERE clause follows the SELECT and FROM clause.
Syntax
SELECT column_nameFROM table_nameWHERE conditions;
Example: Find the complete detail of the EmployeeID is 1003.
SELECT *FROM EmployeeWHERE EmployeeID = 1003;
Output

Must Read: How to use WHERE clause in SQL?
5. How to group filter data based on the specific condition using GROUP BY?
GROUP BY clause in SQL is used to group all the rows that have the same value by one or more columns. It follows the WHERE clause in the SELECT statement and precedes the ORDER BY clause.
Note: It is used in conjunction with the aggregate function.
Syntax
SELECT column_namesFROM table_nameWHERE conditionsGROUP BY column_namesORDER BY column_names;
Example: Use the GROUP BY clause to count the number of employees in each department.mployee table.
SELECT Department, COUNT(EmployeeID) AS 'Number of Employee'FROM EmployeeGROUP BY Department
Output

Must Read: How to use GROUP BY clause in SQL?
6. How to filter groups in a table using the HAVING clause in SQL?
The HAVING clause in SQL is quite similar to the WHERE clause. Similar to the WHERE clause, it filters the data but in a different way.
- It filters the result obtained after the GROUP BY clause.
- It can include one or more conditions.
- ORDER of Execution: After the HAVING clause and before the ORDER BY clause.
Syntax
SELECT column_namesFROM table_nameWHERE conditionsGROUP BY column_nameHAVING conditionsORDER BY column_name;
Example: Using HAVING clause determine the department having number of employees greater than 1.
SELECT Department, Salary, COUNT(EmployeeID) AS 'Number of Employee'FROM EmployeeGROUP BY DepartmentHAVING COUNT(EmployeeID) > 1;
Output

Must Read: How to use HAVING clause in SQL?
7. How to Sort the data using the ORDER BY clause in SQL?
SQL ORDER BY clause is used to arrange the output either in the Ascending or Descending Order.
Syntax
SELECT column_listFROM table_nameWHERE conditionsORDER BY column_names [ASC | DESC];
Note:
- ASC: Ascending Order (By Default)
- DESC: Descending Order
Example: List the record of all the employees in decreasing value of their salary.
SELECT *FROM EmployeeORDER BY Salary DESC;
Output
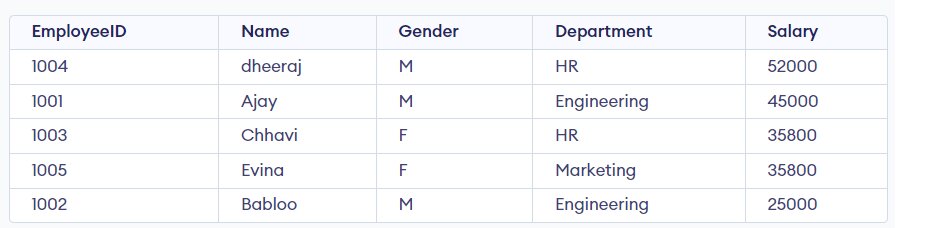
Must Read: How to use ORDER BY clause in SQL?
How to restrict the records using the LIMIT clause in SQL?
The LIMIT clause in SQL is used to set an upper limit on the number of tuples returned for any given query.
It is an efficient way to avoid long-running queries as it stops processing and returns the result as soon as the requirement is fulfilled. This reduces the processing time.
Example: Find the record of top 3 employees who are getting highest salary
SELECT *FROM EmployeeORDER BY Salary DESCLIMIT 3;
Output

Must Read: How to use LIMIT clause in SQL?
Till now, you get enough understanding of how to create a table, how to insert the data into the table, how to filter the records using WHERE and HAVING clause, and you also know how to sort the data.
Now, we will learn how to remove the records from the table.
So, let’s start with removing duplicates from the table.
How to remove the duplicate entries using the DISTINCT clause in SQL?
Now, let’s consider you have 1000 of records and you have to find distinct department in the company using the Employee table. Then, here DISTINCT commands come into action.
To remove the duplicate values from the dataset, we use the DISTINCT clause in SQL. The DISTINCT clause returns only unique values (rows).
Note:
- It can be used with aggregate functions like COUNT, AVG, MAX, MIN, etc.
- It can only be operated on a single column.
- Includes NULL value as a distinct value.
- If the SQL query consists of an ORDER BY clause or any aggregate function, then the limit clause is the last to be evaluated.
Example: Find all the departments from the Employee table that are distinct.
SELECT DISTINCT DepartmentFROM Employee

Best-suited Database and SQL courses for you
Learn Database and SQL with these high-rated online courses

Leet Code SQL Practice Problem
Easy
Question-1: Write a solution to find the
customer_number
| Column Name | Type |
| order_name | int |
| customer_name | int |
- order_number is the primary key (column with unique values) for this table.
- This table contains information about the order ID and the customer ID.
The test cases are generated so that exactly one customer will have placed more orders than any other customer.
The result format is in the following example.
Example:
Input:
Orders Table:
+--------------+-----------------+ | order_number | customer_number | +--------------+-----------------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | | 4 | 3 | +--------------+-----------------+ Output: +-----------------+ | customer_number | +-----------------+ | 3 | +-----------------+
Explanation to the test case:
The customer with number 3 has two orders, which is greater than either customer 1 or 2 because each of them only has one order.
So the result is customer_number 3.
Solution
select customer_number from Orders group by customer_number order by count(customer_number) desc limit 1;
Explanation to the solution
Since we have to find the customer_number for the customer who has placed the largest number of orders.
So, let’s start with:
- SELECT column customer_number FROM tables Orders.
- GROUP BY column customer_number
- COUNT the number of occurrences of values in the column customer_number
- ORDER BY the COUNT in DESC (descending) order
- and since we have to find the customer number who has placed the maximum order, so LIMIT the result by 1.
Question-2: Report for every three-line segments whether they can form a triangle. Return the result table in any order.
Table:
Trian
<strong>gle</strong>
+-------------+------+ | Column Name | Type | +-------------+------+ | x | int | | y | int | | z | int | +-------------+------+
- In SQL, (x, y, z) is the primary key column for this table.
Each row of this table contains the lengths of three-line segments.
The result format is in the following example.
Example:
Input: Triangle table: +----+----+----+ | x | y | z | +----+----+----+ | 13 | 15 | 30 | | 10 | 20 | 15 | +----+----+----+ Output: +----+----+----+----------+ | x | y | z | triangle | +----+----+----+----------+ | 13 | 15 | 30 | No | | 10 | 20 | 15 | Yes | +----+----+----+----------+
Solution
select x,y,z,case when (x+y) > z and (x+z) > y and (y+z) > x then 'Yes' else 'No' end as trianglefrom Triangle
Explanation to Solution
Here, we are given three sides of the triangle and using those sides, we have to check whether they can form a triangle or not. And for that, we will use an important property of a triangle:
- Sum of two sides of a triangle is always greater than the third side.
Now, let’s check the input set in the given example.
- in the first set, the combination 13+15 < 30, i.e., it fails to be a triangle.
- in the second set, all the combination 10+20 > 15, 20+15 > 10, 10+15 > 20 satisfies the above given condition.
Now, to find the solution of the above problem we will use CASE, WHEN, THEN clause.
Question-3: Write a solution to find the names of all the salespersons who did not have any orders related to the company with the name “RED”. Return the result table in any order.
Table:
SalesPerson
+-----------------+---------+ | Column Name | Type | +-----------------+---------+ | sales_id | int | | name | varchar | | salary | int | | commission_rate | int | | hire_date | date | +-----------------+---------+
- sales_id is this table’s primary key (column with unique values).
Each row of this table indicates a salesperson’s name and ID alongside their salary, commission rate, and hire date.
Table:
Company
+-------------+---------+ | Column Name | Type | +-------------+---------+ | com_id | int | | name | varchar | | city | varchar | +-------------+---------+
com_id is this table’s primary key (column with unique values).
Each row of this table indicates a company’s name and ID and the city in which the company is located.
Table:
Orders
+-------------+------+ | Column Name | Type | +-------------+------+ | order_id | int | | order_date | date | | com_id | int | | sales_id | int | | amount | int | +-------------+------+
- order_id is this table’s primary key (column with unique values).
- com_id is a foreign key (reference column) to com_id from the Company table.
- sales_id is a foreign key (reference column) to sales_id from the SalesPerson table.
Each row of this table contains information about one order. This includes the company’s ID, the salesperson’s ID, the order’s date, and the amount paid.
The result format is in the following example.
Example:
Input: SalesPerson table: +----------+------+--------+-----------------+------------+ | sales_id | name | salary | commission_rate | hire_date | +----------+------+--------+-----------------+------------+ | 1 | John | 100000 | 6 | 4/1/2006 | | 2 | Amy | 12000 | 5 | 5/1/2010 | | 3 | Mark | 65000 | 12 | 12/25/2008 | | 4 | Pam | 25000 | 25 | 1/1/2005 | | 5 | Alex | 5000 | 10 | 2/3/2007 | +----------+------+--------+-----------------+------------+ Company table: +--------+--------+----------+ | com_id | name | city | +--------+--------+----------+ | 1 | RED | Boston | | 2 | ORANGE | New York | | 3 | YELLOW | Boston | | 4 | GREEN | Austin | +--------+--------+----------+ Orders table: +----------+------------+--------+----------+--------+ | order_id | order_date | com_id | sales_id | amount | +----------+------------+--------+----------+--------+ | 1 | 1/1/2014 | 3 | 4 | 10000 | | 2 | 2/1/2014 | 4 | 5 | 5000 | | 3 | 3/1/2014 | 1 | 1 | 50000 | | 4 | 4/1/2014 | 1 | 4 | 25000 | +----------+------------+--------+----------+--------+ Output: +------+ | name | +------+ | Amy | | Mark | | Alex | +------+
Explanation to Example
According to orders 3 and 4 in the Orders table, it is easy to tell that only salesperson John and Pam have sales to company RED, so we report all the other names in the table salesperson.
Solution
Here, we will not use the concept of JOINS rather than Subquery.
select salesperson.namefrom orders o join company c on (o.com_id = c.com_id and c.name = 'RED')right join salesperson on salesperson.sales_id = o.sales_idwhere o.sales_id is null
Question-4: Actors and Directors Who Cooperated At Least Three Times
Write a solution to find all the pairs (actor_id, director_id) where the actor has cooperated with the director at least three times. Return the result table in any order.
Table:
ActorDirector
+-------------+---------+ | Column Name | Type | +-------------+---------+ | actor_id | int | | director_id | int | | timestamp | int | +-------------+---------+
- timestamp is this table’s primary key (column with unique values).
The result format is in the following example.
Example:
Input: ActorDirector table: +-------------+-------------+-------------+ | actor_id | director_id | timestamp | +-------------+-------------+-------------+ | 1 | 1 | 0 | | 1 | 1 | 1 | | 1 | 1 | 2 | | 1 | 2 | 3 | | 1 | 2 | 4 | | 2 | 1 | 5 | | 2 | 1 | 6 | +-------------+-------------+-------------+ Output: +-------------+-------------+ | actor_id | director_id | +-------------+-------------+ | 1 | 1 | +-------------+-------------+
Explanation
The only pair is (1, 1) where they cooperated exactly 3 times.
Solution
select actor_id, director_id from(select actor_id,director_id, count(timestamp) as cooperated from ActorDirector group by actor_id,director_id) table1where cooperated>=3;
You can use HAVING clause, rather than WHERE clause. It makes you write the simple and readable code.
select actor_id,director_idfrom ActorDirector group by actor_id,director_idHaving count(timestamp)>=3;
Question-5: Product Sales Analysis
Write a solution to report the product_name, year, and price for each sale_id in the Sales table. Return the resulting table in any order.
Table:
Sales
+-------------+-------+ | Column Name | Type | +-------------+-------+ | sale_id | int | | product_id | int | | year | int | | quantity | int | | price | int | +-------------+-------+
- (sale_id, year) is the primary key (combination of columns with unique values) of this table.
- product_id is a foreign key (reference column) to Product table.
- Each row of this table shows a sale on the product product_id in a certain year. Note that the price is per unit.
Table:
Product
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | +--------------+---------+
- product_id is the primary key (column with unique values) of this table. Each row of this table indicates the product name of each product.
The result format is in the following example.
Example 1:
Input: Sales table: +---------+------------+------+----------+-------+ | sale_id | product_id | year | quantity | price | +---------+------------+------+----------+-------+ | 1 | 100 | 2008 | 10 | 5000 | | 2 | 100 | 2009 | 12 | 5000 | | 7 | 200 | 2011 | 15 | 9000 | +---------+------------+------+----------+-------+ Product table: +------------+--------------+ | product_id | product_name | +------------+--------------+ | 100 | Nokia | | 200 | Apple | | 300 | Samsung | +------------+--------------+ Output: +--------------+-------+-------+ | product_name | year | price | +--------------+-------+-------+ | Nokia | 2008 | 5000 | | Nokia | 2009 | 5000 | | Apple | 2011 | 9000 | +--------------+-------+-------+
Explanation of Example:
- From sale_id = 1, we can conclude that Nokia was sold for 5000 in the year 2008.
- From sale_id = 2, we can conclude that Nokia was sold for 5000 in the year 2009.
- From sale_id = 7, we can conclude that Apple was sold for 9000 in the year 2011.
Solution
SELECT P.product_name ,S.year ,S.price FROM Sales SLEFT JOIN Product PON S.product_id =P.product_id
Question-6: Project Employees
Write an SQL query that reports the average experience years of all the employees for each project, rounded to 2 digits. Return the result table in any order.
Table:
Project
+-------------+---------+ | Column Name | Type | +-------------+---------+ | project_id | int | | employee_id | int | +-------------+---------+
- (project_id, employee_id) is the primary key of this table.
- employee_id is a foreign key to Employee table.
Each row of this table indicates that the employee with employee_id is working on the project with project_id.
Table:
Employee
+------------------+---------+ | Column Name | Type | +------------------+---------+ | employee_id | int | | name | varchar | | experience_years | int | +------------------+---------+
- employee_id is the primary key of this table. It’s guaranteed that experience_years is not NULL.
Each row of this table contains information about one employee.
The query result format is in the following example.
Example:
Input: Project table: +-------------+-------------+ | project_id | employee_id | +-------------+-------------+ | 1 | 1 | | 1 | 2 | | 1 | 3 | | 2 | 1 | | 2 | 4 | +-------------+-------------+ Employee table: +-------------+--------+------------------+ | employee_id | name | experience_years | +-------------+--------+------------------+ | 1 | Khaled | 3 | | 2 | Ali | 2 | | 3 | John | 1 | | 4 | Doe | 2 | +-------------+--------+------------------+ Output: +-------------+---------------+ | project_id | average_years | +-------------+---------------+ | 1 | 2.00 | | 2 | 2.50 | +-------------+---------------+
Explanation of Example:
The average experience years for the first project is (3 + 2 + 1) / 3 = 2.00 and for the second project is (3 + 2) / 2 = 2.50
Solution
select project_id,round(sum(e.experience_years) / count(e.experience_years),2) as average_yearsfrom Project pjoin Employee e on p.employee_id = e.employee_idgroup by project_id
Note: You can also use AVG function rather than defining the average function as we have done.
Question-7: Game Play Analysis
Write a solution to find the first login date for each player. Return the result table in any order.
Table:
Activity
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+
- (player_id, event_date) is the primary key (combination of columns with unique values) of this table.
- This table shows the activity of players in some games.
Each row records a player who logged in and played many games (possibly 0) before logging out on some using some device.
The result format is in the following example.
Example:
Input: Activity table: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-05-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ Output: +-----------+-------------+ | player_id | first_login | +-----------+-------------+ | 1 | 2016-03-01 | | 2 | 2017-06-25 | | 3 | 2016-03-02 | +-----------+-------------+
Solution
select player_id, min(event_date) as first_loginfrom activity group by player_id
Ques-8: User Activity Past 30 Days
Write a solution to find the daily active user count for a period of 30 days ending 2019-07-27 inclusively. A user was active on someday if they made at least one activity on that day. Return the result table in any order.
Table:
Activity
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | session_id | int | | activity_date | date | | activity_type | enum | +---------------+---------+
- This table may have duplicate rows.
- The activity_type column is an ENUM (category) of type (‘open_session’, ‘end_session’, ‘scroll_down’, ‘send_message’).
- The table shows the user activities for a social media website.
- Note that each session belongs to exactly one user.
The result format is in the following example.
Example:
Input: Activity table: +---------+------------+---------------+---------------+ | user_id | session_id | activity_date | activity_type | +---------+------------+---------------+---------------+ | 1 | 1 | 2019-07-20 | open_session | | 1 | 1 | 2019-07-20 | scroll_down | | 1 | 1 | 2019-07-20 | end_session | | 2 | 4 | 2019-07-20 | open_session | | 2 | 4 | 2019-07-21 | send_message | | 2 | 4 | 2019-07-21 | end_session | | 3 | 2 | 2019-07-21 | open_session | | 3 | 2 | 2019-07-21 | send_message | | 3 | 2 | 2019-07-21 | end_session | | 4 | 3 | 2019-06-25 | open_session | | 4 | 3 | 2019-06-25 | end_session | +---------+------------+---------------+---------------+ Output: +------------+--------------+ | day | active_users | +------------+--------------+ | 2019-07-20 | 2 | | 2019-07-21 | 2 | +------------+--------------+
Solution
SELECT activity_date AS day, COUNT(DISTINCT user_id) AS active_usersFROM ActivityWHERE (activity_date > "2019-06-27" AND activity_date <= "2019-07-27")GROUP BY activity_date;
Explanation of the code
To solve the given problem, we must remember to count users distinctly, as they can log in multiple times during the day. One more thing, we have to count the users datewise and in between a specific period of date. So, start with
- Select the column to display, i.e., activity_day
- Define the condition of the dates using the WHERE clause
- Group the result by date, i.e., activity_date.
Question-9: Article View
Write a solution to find all the authors who viewed at least one of their own articles. Return the result table sorted by id in ascending order.
Table:
Views
+---------------+---------+ | Column Name | Type | +---------------+---------+ | article_id | int | | author_id | int | | viewer_id | int | | view_date | date | +---------------+---------+
- This table has no primary key (column with unique values); the table may have duplicate rows.
- Each row of this table indicates that some viewers viewed an article (written by some author) on some date.
- Note that equal author_id and viewer_id indicate the same person.
The result format is in the following example.
Example:
Input: Views table: +------------+-----------+-----------+------------+ | article_id | author_id | viewer_id | view_date | +------------+-----------+-----------+------------+ | 1 | 3 | 5 | 2019-08-01 | | 1 | 3 | 6 | 2019-08-02 | | 2 | 7 | 7 | 2019-08-01 | | 2 | 7 | 6 | 2019-08-02 | | 4 | 7 | 1 | 2019-07-22 | | 3 | 4 | 4 | 2019-07-21 | | 3 | 4 | 4 | 2019-07-21 | +------------+-----------+-----------+------------+ Output: +------+ | id | +------+ | 4 | | 7 | +------+
Solution
select distinct author_id as id from Viewswhere author_id = viewer_id order by id;
Question-10: Average Selling Price
Write an SQL query to find the average selling price for each product. average_price should be rounded to 2 decimal places. Return the result table in any order.
Table:
Prices
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | start_date | date | | end_date | date | | price | int | +---------------+---------+
- (product_id, start_date, end_date) is the primary key for this table.
- Each row of this table indicates the price of the product_id in the period from start_date to end_date.
- For each product_id, there will be no two overlapping periods. That means there will be no two intersecting periods for the same product_id.
Table:
UnitsSold
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | purchase_date | date | | units | int | +---------------+---------+
- There is no primary key for this table; it may contain duplicates.
- Each row of this table indicates each product sold’s date, units, and product_id.
The query result format is in the following example.
Example:
Input: Prices table: +------------+------------+------------+--------+ | product_id | start_date | end_date | price | +------------+------------+------------+--------+ | 1 | 2019-02-17 | 2019-02-28 | 5 | | 1 | 2019-03-01 | 2019-03-22 | 20 | | 2 | 2019-02-01 | 2019-02-20 | 15 | | 2 | 2019-02-21 | 2019-03-31 | 30 | +------------+------------+------------+--------+ UnitsSold table: +------------+---------------+-------+ | product_id | purchase_date | units | +------------+---------------+-------+ | 1 | 2019-02-25 | 100 | | 1 | 2019-03-01 | 15 | | 2 | 2019-02-10 | 200 | | 2 | 2019-03-22 | 30 | +------------+---------------+-------+ Output: +------------+---------------+ | product_id | average_price | +------------+---------------+ | 1 | 6.96 | | 2 | 16.96 | +------------+---------------+
Explanation of the Example
- Average selling price = Total Price of Product / Number of products sold.
- Average selling price for product 1 = ((100 * 5) + (15 * 20)) / 115 = 6.96
- Average selling price for product 2 = ((200 * 15) + (30 * 30)) / 230 = 16.96
Solution
SELECT u.product_id, ROUND(SUM(p.price * u.units) / SUM(u.units), 2) AS average_price FROM unitssold u JOIN prices p ON 1=1 AND p.product_id = u.product_id AND u.purchase_date BETWEEN p.start_date AND p.end_date GROUP BY u.product_id
Question-11: Students and Examination
Write a solution to find the number of times each student attended each exam. Return the result table ordered by student_id and subject_name.
Table:
Students
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+
- student_id is the primary key (column with unique values) for this table.
- Each row of this table contains the ID and the name of one student in the school.
Table:
Subjects
+--------------+---------+ | Column Name | Type | +--------------+---------+ | subject_name | varchar | +--------------+---------+
- subject_name is the primary key (column with unique values) for this table.
- Each row of this table contains the name of one subject in the school.
Table:
Examinations
+--------------+---------+ | Column Name | Type | +--------------+---------+ | student_id | int | | subject_name | varchar | +--------------+---------+
- This table has no primary key (column with unique values). It may contain duplicates.
- Each student from the Students table takes every course from the Subjects table.
- Each row of this table indicates that a student with ID student_id attended the exam of subject_name.
The result format is in the following example.
Example:
Input: Students table: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 1 | Alice | | 2 | Bob | | 13 | John | | 6 | Alex | +------------+--------------+ Subjects table: +--------------+ | subject_name | +--------------+ | Math | | Physics | | Programming | +--------------+ Examinations table: +------------+--------------+ | student_id | subject_name | +------------+--------------+ | 1 | Math | | 1 | Physics | | 1 | Programming | | 2 | Programming | | 1 | Physics | | 1 | Math | | 13 | Math | | 13 | Programming | | 13 | Physics | | 2 | Math | | 1 | Math | +------------+--------------+ Output: +------------+--------------+--------------+----------------+ | student_id | student_name | subject_name | attended_exams | +------------+--------------+--------------+----------------+ | 1 | Alice | Math | 3 | | 1 | Alice | Physics | 2 | | 1 | Alice | Programming | 1 | | 2 | Bob | Math | 1 | | 2 | Bob | Physics | 0 | | 2 | Bob | Programming | 1 | | 6 | Alex | Math | 0 | | 6 | Alex | Physics | 0 | | 6 | Alex | Programming | 0 | | 13 | John | Math | 1 | | 13 | John | Physics | 1 | | 13 | John | Programming | 1 | +------------+--------------+--------------+----------------+
Explanation of Example
- The result table should contain all students and all subjects.
- Alice attended the Math exam 3 times, the Physics exam 2 times, and the Programming exam 1 time.
- Bob attended the Math exam 1 time, the Programming exam 1 time, and did not attend the Physics exam.
- Alex did not attend any exams.
- John attended the Math exam 1 time, the Physics exam 1 time, and the Programming exam 1 time.
Solution
SELECT s.student_id, s.student_name, sub.subject_name, COALESCE(e.attended_exams, 0) AS attended_examsFROM Students sCROSS JOIN Subjects subLEFT JOIN ( SELECT student_id, subject_name, COUNT(*) AS attended_exams FROM Examinations GROUP BY student_id, subject_name) e USING (student_id, subject_name)ORDER BY s.student_id, sub.subject_name;
Question-12: Replace Employee ID With The Unique Identifier
Write a solution to show the unique ID of each user, If a user does not have a unique ID replace just show null. Return the result table in any order.
Table:
Employees
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | +---------------+---------+
- id is the primary key (column with unique values) for this table.
- Each row of this table contains the id and the name of an employee in a company.
Table:
EmployeeUNI
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | unique_id | int | +---------------+---------+
- (id, unique_id) is the primary key (combination of columns with unique values) for this table.
- Each row of this table contains the id and the corresponding unique id of an employee in the company.
The result format is in the following example.
Example:
Input: Employees table: +----+----------+ | id | name | +----+----------+ | 1 | Alice | | 7 | Bob | | 11 | Meir | | 90 | Winston | | 3 | Jonathan | +----+----------+ EmployeeUNI table: +----+-----------+ | id | unique_id | +----+-----------+ | 3 | 1 | | 11 | 2 | | 90 | 3 | +----+-----------+ Output: +-----------+----------+ | unique_id | name | +-----------+----------+ | null | Alice | | null | Bob | | 2 | Meir | | 3 | Winston | | 1 | Jonathan | +-----------+----------+
Explanation of Example:
- Alice and Bob do not have a unique ID, We will show null instead.
- The unique ID of Meir is 2.
- The unique ID of Winston is 3.
- The unique ID of Jonathan is 1.
Solution
select eu.unique_id as unique_id, e.name as namefrom Employees e left join EmployeeUNI eu on e.id = eu.id
Question-13: Top Travellers
Write a solution to report the distance traveled by each user. Return the result table ordered by travelled_distance in descending order, if two or more users traveled the same distance, order them by their name in ascending order.
Table:
Users
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | +---------------+---------+
- id is the column with unique values for this table.
- name is the name of the user.
Table:
Rides
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | user_id | int | | distance | int | +---------------+---------+
- id is the column with unique values for this table.
- user_id is the id of the user who travelled the distance “distance”.
The result format is in the following example.
Example:
Input: Users table: +------+-----------+ | id | name | +------+-----------+ | 1 | Alice | | 2 | Bob | | 3 | Alex | | 4 | Donald | | 7 | Lee | | 13 | Jonathan | | 19 | Elvis | +------+-----------+ Rides table: +------+----------+----------+ | id | user_id | distance | +------+----------+----------+ | 1 | 1 | 120 | | 2 | 2 | 317 | | 3 | 3 | 222 | | 4 | 7 | 100 | | 5 | 13 | 312 | | 6 | 19 | 50 | | 7 | 7 | 120 | | 8 | 19 | 400 | | 9 | 7 | 230 | +------+----------+----------+ Output: +----------+--------------------+ | name | travelled_distance | +----------+--------------------+ | Elvis | 450 | | Lee | 450 | | Bob | 317 | | Jonathan | 312 | | Alex | 222 | | Alice | 120 | | Donald | 0 | +----------+--------------------+
Explanation to Example:
- Elvis and Lee travelled 450 miles; Elvis is the top traveller as his name is alphabetically smaller than Lee’s.
- Bob, Jonathan, Alex, and Alice have only one ride, and we just order them by the total distance of the ride.
- Donald did not have any rides; the distance travelled by him is 0.
Solution
SELECT DISTINCT u.name, IFNULL(SUM(distance) OVER (PARTITION BY user_id), 0) as travelled_distance FROM Rides r RIGHT JOIN Users u ON r.user_id = u.id ORDER BY travelled_distance DESC, name
Question-14: Group Sold Product By Date
Write a solution to find for each date the number of different products sold and their names. The sold product names for each date should be sorted lexicographically. Return the result table ordered by sell_date.
Table
Activities
+-------------+---------+ | Column Name | Type | +-------------+---------+ | sell_date | date | | product | varchar | +-------------+---------+
- This table has no primary key (column with unique values). It may contain duplicates.
- Each row of this table contains the product name and the date it was sold in a market.
The result format is in the following example.
Example:
Input: Activities table: +------------+------------+ | sell_date | product | +------------+------------+ | 2020-05-30 | Headphone | | 2020-06-01 | Pencil | | 2020-06-02 | Mask | | 2020-05-30 | Basketball | | 2020-06-01 | Bible | | 2020-06-02 | Mask | | 2020-05-30 | T-Shirt | +------------+------------+ Output: +------------+----------+------------------------------+ | sell_date | num_sold | products | +------------+----------+------------------------------+ | 2020-05-30 | 3 | Basketball,Headphone,T-shirt | | 2020-06-01 | 2 | Bible,Pencil | | 2020-06-02 | 1 | Mask | +------------+----------+------------------------------+
Explanation to Example:
- For 2020-05-30, Sold items were (headphones, Basketballs, and T-shirts); we sorted them lexicographically and separated them by a comma.
- For 2020-06-01, the Sold items were (Pencil, Bible); we sorted them lexicographically and separated them by a comma.
- For 2020-06-02, the Sold item is (Mask), we just return it.
Solution
SELECT sell_date, COUNT(DISTINCT(product)) AS num_sold, GROUP_CONCAT(DISTINCT product ORDER BY product ASC SEPARATOR ',') AS productsFROM ActivitiesGROUP BY sell_dateORDER BY sell_date ASC
Explanation
Here, in the above problem, the only thing was, how to aggregate the product name in one cell. In MySQL, this can be done by GROUP_CONCAT clause, in which you can also specify the sorting mechanism for group concatenation.
Question-15: Find users with valid E-mail
Write a solution to find the users who have valid emails.
A valid e-mail has a prefix name and a domain where:
- The prefix name is a string that may contain letters (upper or lower case), digits, underscore ‘_’, period ‘.’, and/or dash ‘-‘. The prefix name must start with a letter.
- The domain is ‘@leetcode.com’.
Return the result table in any order.
Table:
Users
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | name | varchar | | mail | varchar | +---------------+---------+
- user_id is the primary key (column with unique values) for this table.
- This table contains information of the users signed up in a website. Some e-mails are invalid.
The result format is in the following example.
Example:
Input: Users table: +---------+-----------+-------------------------+ | user_id | name | mail | +---------+-----------+-------------------------+ | 1 | Winston | winston@leetcode.com | | 2 | Jonathan | jonathanisgreat | | 3 | Annabelle | bella-@leetcode.com | | 4 | Sally | sally.come@leetcode.com | | 5 | Marwan | quarz#2020@leetcode.com | | 6 | David | david69@gmail.com | | 7 | Shapiro | .shapo@leetcode.com | +---------+-----------+-------------------------+ Output: +---------+-----------+-------------------------+ | user_id | name | mail | +---------+-----------+-------------------------+ | 1 | Winston | winston@leetcode.com | | 3 | Annabelle | bella-@leetcode.com | | 4 | Sally | sally.come@leetcode.com | +---------+-----------+-------------------------+
Explanation to Example:
- The mail of user 2 does not have a domain.
- The mail of user 5 has the # sign, which is not allowed.
- The mail of user 6 does not have the leetcode domain.
- The mail of user 7 starts with a period.
Solution
SELECT *FROM UsersWHERE mail REGEXP '^[a-zA-Z][a-zA-Z0-9_.-]*@leetcode[.]com$';
Explanation
The regular expression may be broken down into chunks and explained as follows (refer to the documentation immediately below if needed):
- ^[a-zA-Z]: The email must start with an alphanumeric letter (i.e., not digit).
- [a-zA-Z0-9_.-]*:
- The next zero or more characters must be either alphanumeric (letters a-z, A-Z, or digits 0-9)
- or a _ or .
- or a –
@leetcode[.]com$: + @leetcode: The next sequence of characters must exactly match @leetcode + [.]: The . character within a [] pair does not have special meaning so it must be matched exactly after @leetcode. + com$: The string must end with com.
Medium
Question-1: Manager with at least 5 Direct Reports
Write a solution to find managers with at least five direct reports. Return the result table in any order.
Table:
Employee
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | | department | varchar | | managerId | int | +-------------+---------+
- id is the primary key (column with unique values) for this table.
- Each row of this table indicates the name of an employee, their department, and the id of their manager.
- If managerId is null, then the employee does not have a manager.
- No employee will be the manager of themself.
The result format is in the following example.
Example:
Input: Employee table: +-----+-------+------------+-----------+ | id | name | department | managerId | +-----+-------+------------+-----------+ | 101 | John | A | None | | 102 | Dan | A | 101 | | 103 | James | A | 101 | | 104 | Amy | A | 101 | | 105 | Anne | A | 101 | | 106 | Ron | B | 101 | +-----+-------+------------+-----------+ Output: +------+ | name | +------+ | John | +------+
Solution
Select m.namefrom employee as einner join employee as mon e.managerId=m.idgroup by e.managerId having count(e.id)>=5
Question-2: Tree Node
Each node in the tree can be one of three types:
- “Leaf”: if the node is a leaf node.
- “Root”: if the node is the root of the tree.
- “Inner”: If the node is neither a leaf node nor a root node.
Write a solution to report the type of each node in the tree.
Table:
Tree
+-------------+------+ | Column Name | Type | +-------------+------+ | id | int | | p_id | int | +-------------+------+
- id is the column with unique values for this table.
- Each row of this table contains information about a node’s id and its parent node’s id in a tree.
- The given structure is always a valid tree.
The result format is in the following example.
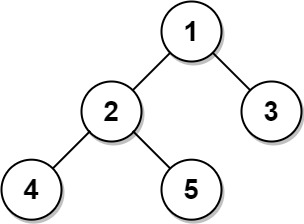
Input: Tree table: +----+------+ | id | p_id | +----+------+ | 1 | null | | 2 | 1 | | 3 | 1 | | 4 | 2 | | 5 | 2 | +----+------+ Output: +----+-------+ | id | type | +----+-------+ | 1 | Root | | 2 | Inner | | 3 | Leaf | | 4 | Leaf | | 5 | Leaf | +----+-------+
Explanation to Example:
- Node 1 is the root node because its parent node is null, and it has child nodes 2 and 3.
- Node 2 is an inner node because it has parent node 1 and child nodes 4 and 5.
- Nodes 3, 4, and 5 are leaf nodes because they have parent nodes, and they do not have child nodes.
Solution
SELECT DISTINCT t1.id, ( CASE WHEN t1.p_id IS NULL THEN 'Root' WHEN t1.p_id IS NOT NULL AND t2.id IS NOT NULL THEN 'Inner' WHEN t1.p_id IS NOT NULL AND t2.id IS NULL THEN 'Leaf' END) AS Type FROM tree t1LEFT JOIN tree t2ON t1.id = t2.p_id
Question-3: Customer Who Bought All Product
Write a solution to report the customer ids from the Customer table that bought all the products in the Product table. Return the result table in any order.
Table:
Customer
+-------------+---------+ | Column Name | Type | +-------------+---------+ | customer_id | int | | product_key | int | +-------------+---------+
- This table may contain duplicates rows.
- customer_id is not NULL.
- product_key is a foreign key (reference column) to Product table.
Table:
Product
+-------------+---------+ | Column Name | Type | +-------------+---------+ | product_key | int | +-------------+---------+
- product_key is the primary key (column with unique values) for this table.
The result format is in the following example.
Example:
Input: Customer table: +-------------+-------------+ | customer_id | product_key | +-------------+-------------+ | 1 | 5 | | 2 | 6 | | 3 | 5 | | 3 | 6 | | 1 | 6 | +-------------+-------------+ Product table: +-------------+ | product_key | +-------------+ | 5 | | 6 | +-------------+ Output: +-------------+ | customer_id | +-------------+ | 1 | | 3 | +-------------+
The customers who bought all the products (5 and 6) are customers with IDs 1 and 3.
Solution
select customer_idfrom customer cgroup by customer_idhaving count(distinct product_key)=(select count(distinct product_key) from product)
Question-4: Game Play Analysis
Write a solution to report the fraction of players that logged in again on the day after the day they first logged in, rounded to 2 decimal places. In other words, you need to count the number of players that logged in for at least two consecutive days starting from their first login date, then divide that number by the total number of players.
Table:
Activity
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+
- (player_id, event_date) is the primary key (combination of columns with unique values) of this table.
- This table shows the activity of players of some games.
- Each row is a record of a player who logged in and played a number of games (possibly 0) before logging out on someday using some device.
The result format is in the following example.
Example:
Input: Activity table: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-03-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ Output: +-----------+ | fraction | +-----------+ | 0.33 | +-----------+
Explanation to Example
Only the player with id 1 logged back in after the first day he had logged in so the answer is 1/3 = 0.33
Solution
SELECT ROUND(COUNT(DISTINCT player_id) / (SELECT COUNT(DISTINCT player_id) FROM Activity), 2) AS fractionFROM ActivityWHERE (player_id, DATE_SUB(event_date, INTERVAL 1 DAY)) IN ( SELECT player_id, MIN(event_date) AS first_login FROM Activity GROUP BY player_id )
Explanation of SQL query for Game Play Analysis
Here, we have to report the fraction of players that logged in again on the day after the day they first logged in (rounding to two decimal places).
So, we have to calculate:
- The number of players who logged in on consecutive days
- To calculate this, we need to find the first login date for each player and check if there is a login on the day after their first login.
- Write a sub-query to calculate the total number of distinct players using the activity table (this will give you the denominator for the fraction)
- In the main query, we use the WHERE clause to filter the rows where the player’s ID and the date of the event match the player’s first login date. (This will give you the players who logged in on consecutive days.)
- Count the distinct player ID in the filtered row (this will give you the numerator for calculating the fraction).
- Calculate the value of the fraction (numerator/denominator) and use the ROUND function to round the result to 2 decimal places.
- To calculate this, we need to find the first login date for each player and check if there is a login on the day after their first login.
Question-5: Product Price At a Given Date
Write an SQL query to find the prices of all products on 2019-08-16. Assume the price of all products before any change is 10. Return the result table in any order
Table:
Products
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | new_price | int | | change_date | date | +---------------+---------+
- (product_id, change_date) is the primary key of this table.
- Each row of this table indicates that the price of some product was changed to a new price at some date.
The query result format is in the following example.
Example:
Input: Products table: +------------+-----------+-------------+ | product_id | new_price | change_date | +------------+-----------+-------------+ | 1 | 20 | 2019-08-14 | | 2 | 50 | 2019-08-14 | | 1 | 30 | 2019-08-15 | | 1 | 35 | 2019-08-16 | | 2 | 65 | 2019-08-17 | | 3 | 20 | 2019-08-18 | +------------+-----------+-------------+ Output: +------------+-------+ | product_id | price | +------------+-------+ | 2 | 50 | | 1 | 35 | | 3 | 10 | +------------+-------+
Solution
select distinct product_id, 10 as pricefrom Productsgroup by product_idhaving (min(change_date) > "2019-08-16")
union
select p2.product_id, new_pricefrom Products p2where (p2.product_id, p2.change_date) in (select product_id, max(change_date) as recent_datefrom Productswhere change_date <= "2019-08-16"group by product_id)
Note: Inspite of using UNION clause you can also use LEFT JOIN with a subquery to get the same above result.
SELECT T1.product_id, IFNULL(T2.new_price,10) AS priceFROM (SELECT DISTINCT product_id FROM Products) AS T1 LEFT JOIN (SELECT product_id, new_priceFROM ProductsWHERE (product_id, change_date) IN (SELECT product_id, MAX(change_date) AS last_dateFROM ProductsWHERE change_date <= '2019-08-16'GROUP BY product_id)) AS T2ON T1.product_id = T2.product_id;
Question-6: Monthly Transaction
Write an SQL query to find for each month and country, the number of transactions and their total amount, the number of approved transactions and their total amount. Return the result table in any order.
The query result format is in the following example.
Example:
Input: Transactions table: +------+---------+----------+--------+------------+ | id | country | state | amount | trans_date | +------+---------+----------+--------+------------+ | 121 | US | approved | 1000 | 2018-12-18 | | 122 | US | declined | 2000 | 2018-12-19 | | 123 | US | approved | 2000 | 2019-01-01 | | 124 | DE | approved | 2000 | 2019-01-07 | +------+---------+----------+--------+------------+ Output: +----------+---------+-------------+----------------+--------------------+-----------------------+ | month | country | trans_count | approved_count | trans_total_amount | approved_total_amount | +----------+---------+-------------+----------------+--------------------+-----------------------+ | 2018-12 | US | 2 | 1 | 3000 | 1000 | | 2019-01 | US | 1 | 1 | 2000 | 2000 | | 2019-01 | DE | 1 | 1 | 2000 | 2000 | +----------+---------+-------------+----------------+--------------------+-----------------------+
Solution
SELECT DATE_FORMAT(trans_date, '%Y-%m') AS month, country, COUNT(*) AS trans_count, SUM(IF(state = 'approved', 1, 0)) AS approved_count, SUM(amount) AS trans_total_amount, SUM(IF(state = 'approved', amount, 0)) AS approved_total_amountFROM TransactionsGROUP BY DATE_FORMAT(trans_date, '%Y-%m'), country;
Expalnation
Here, we have to calculate the number of transactions and their total amount, the number of approved transactions, and their total amount for each month and country.
To do that we have used aggregate functions like COUNT and SUM and at the end, we have grouped the transactions by month and country to get the desired result.
Here we have used the DATE_FORMAT function of SQL to extract the month from the trans_date column and assign it an alias Month.
Question-7: Last Person to fit in Bus
There is a queue of people waiting to board a bus. However, the bus has a weight limit of
1000
Write a solution to find the person_name of the last person that can fit on the bus without exceeding the weight limit. The test cases are generated such that the first person does not exceed the weight limit.
Table:
Queue
+-------------+---------+ | Column Name | Type | +-------------+---------+ | person_id | int | | person_name | varchar | | weight | int | | turn | int | +-------------+---------+
- person_id column contains unique values.
- This table has information about all people waiting for a bus.
- The person_id and turn columns will contain all numbers from 1 to n, where n is the number of rows in the table.
- turn determines the order of which the people will board the bus, where turn=1 denotes the first person to board and turn=n denotes the last person to board.
- weight is the weight of the person in kilograms.
The result format is in the following example.
Example:
Input: Queue table: +-----------+-------------+--------+------+ | person_id | person_name | weight | turn | +-----------+-------------+--------+------+ | 5 | Alice | 250 | 1 | | 4 | Bob | 175 | 5 | | 3 | Alex | 350 | 2 | | 6 | John Cena | 400 | 3 | | 1 | Winston | 500 | 6 | | 2 | Marie | 200 | 4 | +-----------+-------------+--------+------+ Output: +-------------+ | person_name | +-------------+ | John Cena | +-------------+
Explanation to Example
The following table is ordered by the turn for simplicity. +------+----+-----------+--------+--------------+ | Turn | ID | Name | Weight | Total Weight | +------+----+-----------+--------+--------------+ | 1 | 5 | Alice | 250 | 250 | | 2 | 3 | Alex | 350 | 600 | | 3 | 6 | John Cena | 400 | 1000 | (last person to board) | 4 | 2 | Marie | 200 | 1200 | (cannot board) | 5 | 4 | Bob | 175 | ___ | | 6 | 1 | Winston | 500 | ___ | +------+----+-----------+--------+--------------+
Solution
select person_name from(select person_name, weight, turn, sum(weight) over(order by turn) as cum_sumfrom queue) xwhere cum_sum <= 1000order by turn desc limit 1;
Question-8: Restaurant Growth
You are the restaurant owner and want to analyze a possible expansion (there will be at least one customer daily). Compute the moving average of how much the customer paid in a seven-day window (i.e., current day + 6 days before). average_amount should be rounded to two decimal places.
Return the result table ordered by visited_on in ascending order.
Table:
Customer
+---------------+---------+ | Column Name | Type | +---------------+---------+ | customer_id | int | | name | varchar | | visited_on | date | | amount | int | +---------------+---------+
- In SQL,(customer_id, visited_on) is the primary key for this table.
- This table contains data about customer transactions in a restaurant.
- visited_on is when the customer with ID (customer_id) has visited the restaurant.
- amount is the total paid by a customer
The result format is in the following example.
Example:
Input: Customer table: +-------------+--------------+--------------+-------------+ | customer_id | name | visited_on | amount | +-------------+--------------+--------------+-------------+ | 1 | Jhon | 2019-01-01 | 100 | | 2 | Daniel | 2019-01-02 | 110 | | 3 | Jade | 2019-01-03 | 120 | | 4 | Khaled | 2019-01-04 | 130 | | 5 | Winston | 2019-01-05 | 110 | | 6 | Elvis | 2019-01-06 | 140 | | 7 | Anna | 2019-01-07 | 150 | | 8 | Maria | 2019-01-08 | 80 | | 9 | Jaze | 2019-01-09 | 110 | | 1 | Jhon | 2019-01-10 | 130 | | 3 | Jade | 2019-01-10 | 150 | +-------------+--------------+--------------+-------------+ Output: +--------------+--------------+----------------+ | visited_on | amount | average_amount | +--------------+--------------+----------------+ | 2019-01-07 | 860 | 122.86 | | 2019-01-08 | 840 | 120 | | 2019-01-09 | 840 | 120 | | 2019-01-10 | 1000 | 142.86 | +--------------+--------------+----------------+
Explanation to Example
- 1st moving average from 2019-01-01 to 2019-01-07 has an average_amount of (100 + 110 + 120 + 130 + 110 + 140 + 150)/7 = 122.86
- 2nd moving average from 2019-01-02 to 2019-01-08 has an average_amount of (110 + 120 + 130 + 110 + 140 + 150 + 80)/7 = 120
- 3rd moving average from 2019-01-03 to 2019-01-09 has an average_amount of (120 + 130 + 110 + 140 + 150 + 80 + 110)/7 = 120
- 4th moving average from 2019-01-04 to 2019-01-10 has an average_amount of (130 + 110 + 140 + 150 + 80 + 110 + 130 + 150)/7 = 142.86
Solution
# Write your MySQL query statement belowSELECT visited_on, ( SELECT SUM(amount) FROM customer WHERE visited_on BETWEEN DATE_SUB(c.visited_on, INTERVAL 6 DAY) AND c.visited_on ) AS amount, ROUND( ( SELECT SUM(amount) / 7 FROM customer WHERE visited_on BETWEEN DATE_SUB(c.visited_on, INTERVAL 6 DAY) AND c.visited_on ), 2 ) AS average_amountFROM customer cWHERE visited_on >= ( SELECT DATE_ADD(MIN(visited_on), INTERVAL 6 DAY) FROM customer )GROUP BY visited_on;
Explanation to Solution
Here, we have to calculate the amount and average amount of how much the customer paid in a seven-day window.
To do that, select the visited date from the customer table.
- Create a subquery that sums the amount for each visited_on date by considering the previous 7 days.
- Use the WHERE clause on visited_on to filter the customer BETWEEN the given date.
- Similarly, write another subquery to calculate the average amount.
- To find the average of 7 days, divide the sum(amount)/7.
- Use the WHERE clause to filter the record where there will be at least one customer.
- Finally, group the result by the column visited_on.
Question-9: Movie Rating
Write a solution to:
- Find the user’s name who has rated the greatest number of movies. In case of a tie, return the lexicographically smaller user name.
- Find the movie name with the highest average rating in February 2020. In case of a tie, return the lexicographically smaller movie name.
Table:
Movies
+---------------+---------+ | Column Name | Type | +---------------+---------+ | movie_id | int | | title | varchar | +---------------+---------+
- movie_id is the primary key (column with unique values) for this table.
- title is the name of the movie.
Table:
Users
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | name | varchar | +---------------+---------+
- user_id is the primary key (column with unique values) for this table
Table:
MovieRating
+---------------+---------+ | Column Name | Type | +---------------+---------+ | movie_id | int | | user_id | int | | rating | int | | created_at | date | +---------------+---------+
- (movie_id, user_id) is the primary key (column with unique values) for this table.
- This table contains the rating of a movie by a user in their review.
- created_at is the user’s review date.
The result format is in the following example.
Example:
Input: Movies table: +-------------+--------------+ | movie_id | title | +-------------+--------------+ | 1 | Avengers | | 2 | Frozen 2 | | 3 | Joker | +-------------+--------------+ Users table: +-------------+--------------+ | user_id | name | +-------------+--------------+ | 1 | Daniel | | 2 | Monica | | 3 | Maria | | 4 | James | +-------------+--------------+ MovieRating table: +-------------+--------------+--------------+-------------+ | movie_id | user_id | rating | created_at | +-------------+--------------+--------------+-------------+ | 1 | 1 | 3 | 2020-01-12 | | 1 | 2 | 4 | 2020-02-11 | | 1 | 3 | 2 | 2020-02-12 | | 1 | 4 | 1 | 2020-01-01 | | 2 | 1 | 5 | 2020-02-17 | | 2 | 2 | 2 | 2020-02-01 | | 2 | 3 | 2 | 2020-03-01 | | 3 | 1 | 3 | 2020-02-22 | | 3 | 2 | 4 | 2020-02-25 | +-------------+--------------+--------------+-------------+ Output: +--------------+ | results | +--------------+ | Daniel | | Frozen 2 | +--------------+
Explanation to Example
- Daniel and Monica have rated 3 movies (“Avengers”, “Frozen 2” and “Joker”) but Daniel is smaller lexicographically.
- Frozen 2 and Joker have a rating average of 3.5 in February but Frozen 2 is smaller lexicographically.
Solution
select name as results from ( select user_id, name, count(rating) rating_num from Movie_Rating left join Users using(user_id) group by user_id, name order by rating_num desc, name asc limit 1) a unionselect title as results from ( select movie_id, title, avg(rating) avg_rating from Movie_Rating left join Movies using(movie_id) where created_at like '2020-02-%' group by movie_id, title order by avg_rating desc, title asc limit 1) b
Question-10: Capital Gain/Loss
Write a solution to report the Capital gain/loss for each stock. The Capital gain/loss of a stock is the total gain or loss after buying and selling the stock one or many times.
Return the result table in any order.
able:
Stocks
+---------------+---------+ | Column Name | Type | +---------------+---------+ | stock_name | varchar | | operation | enum | | operation_day | int | | price | int | +---------------+---------+
- (stock_name, operation_day) is the primary key (combination of columns with unique values) for this table.
- The operation column is an ENUM (category) of type (‘Sell’, ‘Buy’)
- Each row of this table indicates that the stock with stock_name had an operation on the day operation_day with the price.
- Each ‘Sell’ operation for a stock is guaranteed to have a corresponding ‘Buy’ operation in the previous day, and ‘Buy’ operation for a stock is guaranteed to have a corresponding ‘Sell’ operation on an upcoming day.
The result format is in the following example.
Example:
Input: Stocks table: +---------------+-----------+---------------+--------+ | stock_name | operation | operation_day | price | +---------------+-----------+---------------+--------+ | Leetcode | Buy | 1 | 1000 | | Corona Masks | Buy | 2 | 10 | | Leetcode | Sell | 5 | 9000 | | Handbags | Buy | 17 | 30000 | | Corona Masks | Sell | 3 | 1010 | | Corona Masks | Buy | 4 | 1000 | | Corona Masks | Sell | 5 | 500 | | Corona Masks | Buy | 6 | 1000 | | Handbags | Sell | 29 | 7000 | | Corona Masks | Sell | 10 | 10000 | +---------------+-----------+---------------+--------+ Output: +---------------+-------------------+ | stock_name | capital_gain_loss | +---------------+-------------------+ | Corona Masks | 9500 | | Leetcode | 8000 | | Handbags | -23000 | +---------------+-------------------+
Solution
SELECT stock_name, SUM( CASE WHEN operation = 'Buy' THEN -price ELSE price END) AS capital_gain_lossFROM StocksGROUP BY stock_name
FAANG QUESTION FOR PRACTICE
EASY
1. Facebook – Pages with No Likes
Assume you’re given two tables containing data about Facebook Pages and their respective likes (as in “Like a Facebook Page”). Write a query to return the IDs of the Facebook pages with zero likes. The output should be sorted in ascending order based on the page IDs.

Solution
SELECT p1.page_idFROM pages p1LEFT JOIN page_likes p2ON p1.page_id = p2.page_idWHERE p2.page_id IS NULLORDER BY p2.page_id
Hint
- Use LEFT JOIN between pages and page_likes tables.
- Check the NULL values.
2. Twitter – Histogram of Tweets
Assume you’re given a table of Twitter tweet data and write a query to obtain a histogram of tweets posted per user in 2022. Output the tweet counts per user as the bucket and the number of Twitter users who fall into that bucket. In other words, group the users by the number of tweets they posted in 2022 and count the number of users in each group.
Solution
SELECT tweet_bucket, count(tweet_bucket) AS users_num FROM( SELECT COUNT(user_id) AS tweet_bucket FROM tweets WHERE DATE_PART('year', tweet_date)=2022 GROUP BY user_id) as twtGROUP BY tweet_bucket
3. Facebook – App Click-through Rate (CTR)
Assume you have an events table on Facebook app analytics. Write a query to calculate the click-through rate (CTR) for the app in 2022 and round the results to 2 decimal places.
Definition and note:
- Percentage of click-through rate (CTR) = 100.0 * Number of clicks / Number of impressions
- To avoid integer division, multiply the CTR by 100.0, not 100.

Solution
SELECT app_id, ROUND(100.0 * sum(case WHEN event_type = 'click' then 1 ELSE 0 END) / sum(case WHEN event_type = 'impression' then 1 ELSE 0 END),2) as ctrFROM eventsWHERE timestamp BETWEEN '2022-01-01' AND '2022-12-31'GROUP BY app_id;;
Hint
Use CASE, WHEN, and THEN to calculate the impression count and click count. You can use:
- sum(case WHEN event_type = ‘impression’ then 1 ELSE 0 END) as impression_count,
- sum(case WHEN event_type = ‘click’ then 1 ELSE 0 END) as click_count,
4. New York Times – Laptop vs Mobile Viewership
Assume you’re given the table on user viewership categorized by device type, where the three types are laptop, tablet, and phone. Write a query that calculates the total viewership for laptops and mobile devices, where mobile is defined as the sum of tablet and phone viewership. Output the total viewership for laptops as laptop_reviews and the total viewership for mobile devices as mobile_views.
Solution
SELECT SUM(CASE WHEN device_type='laptop' THEN 1 ELSE 0 END) AS laptop_reviews,SUM(CASE WHEN device_type IN ('phone','tablet') THEN 1 ELSE 0 END) AS mobile_reviewsFROM viewership
Hint
Use CASE, WHEN, and THEN as done in the previous question.
5. Microsoft – Teams Power Users
Write a query to identify the top 2 Power Users who sent the most messages on Microsoft Teams in August 2022. Display these 2 users’ IDs and the total number of messages they sent. Output the results in descending order based on the count of the messages.
Assumption: No two users have sent the same number of messages in August 2022.

Solution
SELECT sender_id, count(message_id) AS message_countFROM messageswhere sent_date >= '08/01/2022' and sent_date < '09/01/2022'group by sender_idorder by message_count DESCLIMIT 2;
6. Linkedin – Duplicate Job Listings
Assume you’re given a table containing job postings from various companies on the LinkedIn platform. Write a query to retrieve the count of companies that have posted duplicate job listings.
Definition: Duplicate job listings are defined as two job listings within the same company that share identical titles and descriptions.

Solution
SELECT COUNT(DISTINCT company_id) AS duplicate_companiesFROM (SELECT company_id, COUNT(job_id) AS job_countFROM job_listingsGROUP BY company_id, title, description) AS duplicate_countWHERE job_count > 1
7. Amazon – Average Review Rating
Given the reviews table, write a query to retrieve the average star rating for each product, grouped by month. The output should display the month as a numerical value, product ID, and average star rating rounded to two decimals. Sort the output first by month and then by product ID.
Solution
SELECT EXTRACT(MONTH FROM submit_date) AS month, product_id AS product, ROUND(AVG(stars), 2) AS avg_valueFROM reviewsGROUP BY EXTRACT(MONTH FROM submit_date), product_idORDER BY month, product;
8. JPMorgan – Cards Issued Difference
Your team at JPMorgan Chase is preparing to launch a new credit card, and to gain some insights, you’re analyzing how many credit cards were issued each month.
Write a query that outputs the name of each credit card and the difference in the number of issued cards between the month with the highest and lowest issuance cards. Arrange the results based on the largest disparity.

9. Cities With Completed Trades
Assume you’re given the tables containing completed trade orders and user details in a Robinhood trading system.
Write a query to retrieve the top three cities that have the highest number of completed trade orders listed in descending order. Output the city name and the corresponding number of completed trade orders.
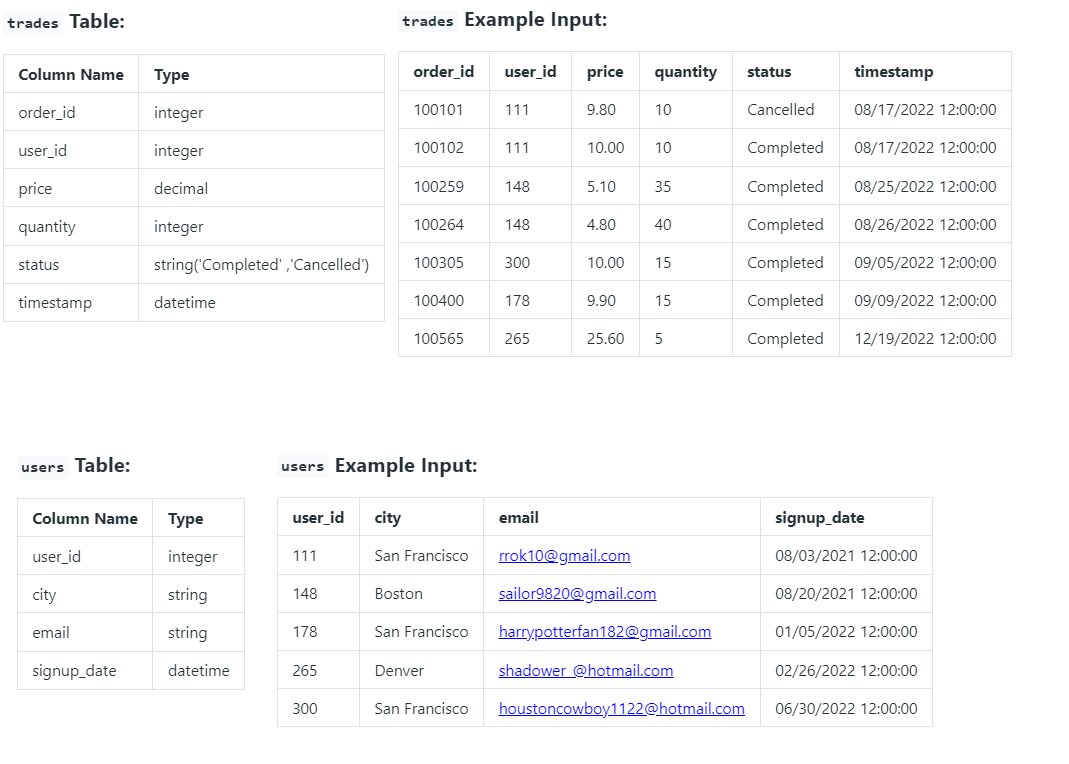
Solution
SELECT u.city, COUNT(t.order_id) as total_orders FROM trades t LEFT JOIN users u on t.user_id = u.user_id WHERE t.status = 'Completed'GROUP BY cityORDER BY total_orders DESCLIMIT 3
10. Alibaba – Compressed Mean
You’re trying to find the mean number of items per order on Alibaba, rounded to 1 decimal place using tables which includes information on the count of items in each order (
item_count
order_occurrences
There are a total of 500 orders with one item per order, 1000 orders with two items per order, and 800 orders with three items per order.

Solution
SELECT ROUND(1.0*SUM(ITEM_COUNT*ORDER_OCCURENCES)/SUM(ORDER_OCCURENCES),1) AS MEANFROM ITEMS_PER_ORDER;
Explanation
Here, we multiplied 1.0 by the sum to convert the integer to decimal format.
Basic Level SQL Interview Questions
Below is the list of the most important basic MySQL and SQL interview questions.
Q1. What is DBMS?
Ans. A Database Management System (DBMS) is system software for creating and managing databases. It serves as an interface between databases and end-users or application programs so that data is consistently organized and remains easily accessible. It allows end-users to create, read, update, and delete data in a database. There are two types of DBMS:
- Relational Database Management System (RDBMS): In RDBMS, the data is stored in relations (tables). Example – MySQL.
- Non-Relational Database Management System (often called NoSQL databases): It stores data in a non-tabular form. Example – MongoDB
Explore courses related to SQL:
| Popular Technology Courses | Popular Database Administration Courses |
| Popular Programming Courses | Popular Data Visualization Courses |
Q2. What is SQL?
Ans. SQL (structured querying language) is a computer language used to create, update, and modify a database. It is the standard language for Relational Database System. All the RDMS like MySQL, MS Access, Oracle, and SQL Server use SQL as their standard database language.
Q3. What is MySQL?
And. MySQL is an open-source relational database management system (RDBMS) that is developed and distributed by Oracle Corporation. Supported by various operating systems, such as Windows, Unix, Linux, etc., MySQL can be used to develop different types of applications. Known for its speed, reliability, and flexibility, MySQL is mainly used for developing web applications.
Q4. What are the subsets of SQL? Explain them.
Ans. The following are the three subsets of SQL:
- Data Definition Language (DDL) – It allows end-users to CREATE, ALTER, and DELETE database objects.
- Data Manipulation Language (DML) – With this, you can access and manipulate data. It allows you to Insert, Update, Delete, and Retrieve data from the database.
- Data Control Language (DCL) – This lets you control access to the database. It includes the Grant and Revoke permissions to manipulate or modify the database.
Q5. What is the primary key?
Ans. A primary key constraint uniquely identifies each row/record in a database table. Primary keys must contain unique values. Null value and duplicate values are not allowed to be entered in the primary key column. A table can have only one primary key. It can consist of single or multiple fields.
Q6. What is a foreign key?
Ans. A foreign key (often called the referencing key) is used to link two tables together. It is a column or a combination of columns whose values match a Primary Key in a different table. It acts as a cross-reference between tables because it references the primary key of another table and established a link between them.
Learn – what is Database Administration?
Q7. What is RDBMS?
Ans. Relational Database Management System or RDBMS is based on the relational database model and is among the most popular database management systems.
Also Read: What is the Difference Between DBMS and RDBMS?
Q8. What are the features of MySQL?
Ans. Here are some of the important features of MySQL:
- It is reliable and easy to use
- It supports standard SQL (Structured Query Language)
- MySQL is secure as it consists of a data security layer that protects sensitive data from unauthorized users
- MySQL has a flexible structure and supports a large number of embedded applications
- It is one of the very fast database languages
- It is a suitable database software for both large and small applications
- MySQL offers very high-performance results compared to other databases
- It is supported by many well-known programming languages, such as PHP, Java, and C++
- It is free to download and use
Also Read>> PHP Interview Questions and Answers
Q9. What are the disadvantages of MySQL?
Ans. The disadvantages of MySQL are:
- It is hard to make MySQL scalable
- It does not support a very large database size as efficiently
- MySQL does not support SQL check constraint
- It is prone to data corruption
Check out the best Database Administration Courses
Q10. What are the differences between MySQL vs SQL?
Ans. This is one of the frequently asked SQL interview questions.
The differences between MySQL and SQL are:
| MySQL | SQL |
| 1. It is a relational database that uses SQL to query a database | 1. It is a query language |
| 2. MySQL supports multiple storage engines and plug-in storage engines | 2. SQL supports a single storage engine |
| 3. It is a database that stores the existing data in a database in an organized manner. | 3. SQL is used to access, update, and manipulate the data stored in a database |
| 4. Supports many platforms | 4. Supports only Linux and Windows |
| 5. It has a complex syntax | 5. It has a simpler syntax |
Q11. What is a unique key?
Ans. A unique key is a set of one or more than one field/column of a table that uniquely identifies a record in a database table. A primary key is a special kind of unique key.
Q12. Explain the different types of indexes in SQL.
Ans. There are three types of indexes in SQL:
- Unique Index – It does not allow a field to have duplicate values if the column is unique indexed.
- Clustered Index – This index defines the order in which data is physically stored in a table. It reorders the physical order of the table and searches based on key values. There can be only one clustered index per table.
- Non-Clustered Index – It does not sort the physical order of the table and maintains a logical order of the data. Each table can have more than one non-clustered index.
Q13. What is the difference between TRUNCATE and DELETE?
Ans. This is one of the most commonly asked SQL interview questions. The difference between TRUNCATE and DELETE are:
| DELETE | TRUNCATE |
| Delete command is used to delete a specified row in a table. | Truncate is used to delete all the rows from a table. |
| You can roll back data after using the delete statement. | You cannot roll back data. |
| It is a DML command. | It is a DDL command. |
| It is slower than a truncate statement. | It is faster. |
Q14. What is the difference between:
SELECT * FROM MyTable WHERE MyColumn <> NULL
SELECT * FROM MyTable WHERE MyColumn IS NULL
Ans. The first syntax will not work because NULL means ‘no value’, and you cannot use scalar value operators. This is why there is a separate IS – a NULL predicate in SQL.
Also explore:
- Paid and free online courses by Coursera
- Popular online Udemy courses
- Top online edX courses
Q15. What is the difference between CHAR and VARCHAR?
Ans. CHAR is a fixed-length character data type, while VARCHAR is a variable-length character data type.
Q16. What is a subquery in SQL? What are the different types of subquery?
Ans. A subquery is a query within another query. When there is a query within a query, the outer query is called the main query, while the inner query is called a subquery. There are two types of a subquery:
- Correlated subquery: It obtains values from its outer query before it executes. When the subquery returns, it passes its results to the outer query.
- Non-Correlated subquery: It executes independently of the outer query. The subquery executes first and then passes its results to the outer query. Both inner and outer queries can run separately.
Also explore: Understanding Subqueries in SQL
Q17. What is collation sensitivity?
Ans. Collation sensitivity defines the rules to sort and compare the strings of character data, based on correct character sequence, case sensitivity, character width, and accent marks, among others.
Q18. What are the different types of collation sensitivity?
Ans. There are four types of collation sensitivity, which include –
- Accent sensitivity
- Case sensitivity
- Kana sensitivity
- Width sensitivity
Q19. What is a “scheduled job” or “scheduled task”?
Ans. Scheduled job or task allows automated task management on regular or predictable cycles. One can schedule administrative tasks and decide the order of the tasks.
Check out the best Programming courses.
Q20. Can you name different types of MySQL commands?
Ans. SQL commands are divided into the following –
- Data Definition Language (DDL)
- Data Manipulation Language (DML)
- Data Control Language (DCL)
- Transaction Control Language (TCL)
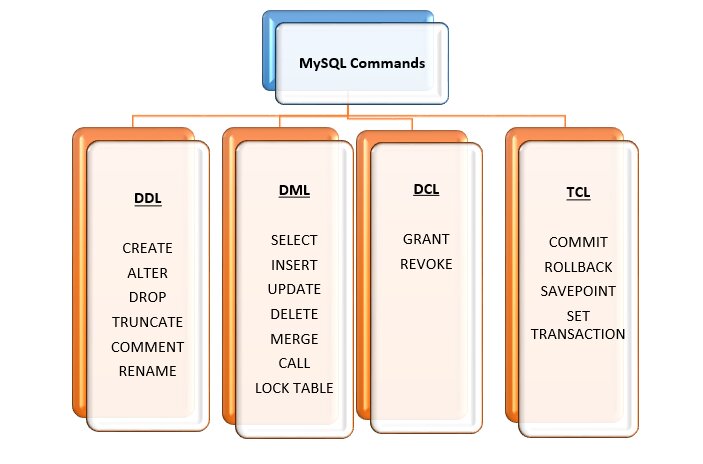
Q21. Explain different DDL commands in MySQL.
Ans. DDL commands include –
- CREATE – Used to create the database or its objects like table, index, function, views, triggers, etc.
- DROP – Used to delete objects
- ALTER – Used to change database structures
- TRUNCATE – It erases all records from a table, excluding its database structure
- COMMENT – Used to add comments to the data dictionary
- RENAME – Used to rename a database object
Q22. Explain different DML commands in MySQL.
Ans. This is one of the most popularly asked SQL interview questions.
DML commands include –
- SELECT – Used to select specific database data
- INSERT – Used to insert new records into a table
- UPDATE – It helps in updating existing records
- DELETE – Used to delete existing records from a table
- MERGE – Used to UPSERT operation (insert or update)
- CALL – It is used when you need to call a PL/SQL or Java subprogram
- EXPLAIN PLAN – Used to interpret data access path
- LOCK TABLE – Used to control concurrency
Q23. Explain different DCL commands in MySQL.
Ans. DCL commands are –
- GRANT – It provides user access privileges to the database
- DENY – Used to deny permissions to users
- REVOKE – Used to withdraw user access by using the GRANT command
Q24. Explain different TCL commands in MySQL.
Ans. DCL commands include –
- COMMIT – Used to commit a transaction
- ROLLBACK – Used to roll back a transaction
- SAVEPOINT – Used to roll back the transaction within groups
- SET TRANSACTION – Used to specify transaction characteristics
Q25. What are the different types of Database relationships in MySQL?
Ans. There are three types of Database Relationship –
- One-to-one – Both tables can have only one record
- One-to-many – The single record in the first table can be related to one or more records in the second table
- Many-to-many – Each record in both the tables can be related to any number of records
Q26. What is Normalization?
Ans. Normalization is a database design technique to organize tables to reduce data redundancy and data dependency.
Also explore: Introduction to Normalization – SQL Tutorial
Q27. What are the different types of Normalization?
Ans. There are six different types of Normalization –
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce-Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
- Fifth Normal Form (5NF)
Q28. What is Denormalization?
Ans. Denormalization is a database optimization technique for increasing a database infrastructure performance by adding redundant data to one or more tables.
Check out the list of Top Online IT Courses.
Q29. Is MySQL query case-sensitive?
Ans. MySQL queries are not case-sensitive by default. The following queries are the same.
SELECT * FROM `table` WHERE `column` = ‘value’
SELECT * FROM `table` WHERE `column` = ‘VALUE’
SELECT * FROM `table` WHERE `column` = ‘VaLuE’
Q30. How many TRIGGERS are allowed in the MySQL table?
Ans. 6 triggers are allowed in the MySQL table:
- BEFORE INSERT
- AFTER INSERT
- BEFORE UPDATE
- AFTER UPDATE
- BEFORE DELETE
- AFTER DELETE
Q31. What are the different column comparison operators in MySQL?
Ans. The =, <>, <=, <, >=, >, <<, >>, < = >, AND, OR or LIKE operator are the comparison operators in MySQL.
Comparisons operators are generally used with SELECT statements. They are used to compare one expression to another value or expression.
Q32. What syntax can we use to get a version of MySQL?
Ans. By using the given query in your phpmyadmin-
SELECT version();
Q33. What is Auto Increment in SQL?
Ans. Auto Increment allows a unique number to be generated whenever a new record is created in a table. Generally, it is the PRIMARY KEY field that we want to be created automatically every time a new record is inserted.
Q34. SQL Server runs in which TCP/IP port? Can it be changed?
Ans. SQL Server runs on port 1433, and it can be changed from the Network Utility TCP/IP properties.
Q35. Name symmetric key encryption algorithms supported in the SQL server.
Ans. SQL Server supports several symmetric key encryption algorithms, such as DES, Triple DES, RC2, RC4, 128-bit RC4, DESX, 128-bit AES, 192-bit AES, and 256-bit AES.
Q36. What is Database Relationship?
Ans. A Database Relationship is defined as the connection between two relational database tables. The primary table has a foreign key that references the primary key of another table. There are three types of Database Relationship –
- One-to-one
- One-to-many
- Many-to-many
Q37. What is faster between a table variable and a temporary table?
Ans. Between these, a table variable is faster mostly as it is stored in memory, whereas a temporary table is stored on disk. In case the size of the table variable exceeds memory size, then both the tables perform similarly.
Also Read>> Top Tableau Interview Questions and Answers
Q38. Mention the command used to get back the privileges offered by the GRANT command?
Ans. REVOKE command is used to get back the privileges offered by the GRANT command.
Q39. What is a Clause in SQL?
Ans. A clause in SQL is a part of a query that allows users to filter or customize how they want their data to be queried to them. It lets users limit the result set by providing a condition to the query. When there is a large amount of data stored in the database, Clause can be used to query and get data required by the user. The clause function helps filter and analyze data quickly.
For Example – WHERE clause, HAVING clause.
Q40. Explain the ‘WHERE’ Clause and the ‘HAVING’ Clause.
Ans. It is one of the most important SQL interview questions.
The WHERE clause is used to filter the records from the table or used while joining more than one table. It returns the particular value from the table if the specified condition in the WHERE clause is satisfied. It is used with SELECT, INSERT, UPDATE, and DELETE queries to filter data from the table or relation.
For Example:
SELECT * FROM employees
WHERE working_hour > 9;
The HAVING clause is used to filter the records from the groups based on the given condition in the HAVING Clause. It can only be used with the SELECT statement. It returns only those values from the groups in the final result that fulfills certain conditions.
For Example:
SELECT name, SUM(working_hour) AS “Total working hours”
FROM employees GROUP BY name
HAVING SUM(working_hour) > 6;
Q41. Explain the SELECT statement?
Ans. The SQL SELECT statement helps select data from a database. It returns a result set of records, from one or more tables.
Syntax:
SELECT * FROM myDB.employees;
Q42. What are the differences between the ‘WHERE’ Clause and the ‘HAVING’ Clause?
Ans. Below are the major differences between the ‘WHERE’ Clause and the ‘HAVING’ Clause:
| WHERE Clause | HAVING Clause |
| It performs filtration on individual rows based on the specified condition. | HAVING clause performs filtration on groups based on the specified condition. |
| It can be used without GROUP BY Clause. | It is always used with the GROUP BY Clause. |
| WHERE Clause is applied in row operations. | HAVING is applied in column operations. |
| We cannot use the WHERE clause with aggregate functions. | This clause works with aggregate functions. |
| WHERE comes before GROUP BY | HAVING comes after GROUP BY. |
| This clause acts as a pre-filter. | HAVING clause acts as a post-filter. |
| WHERE Clause can be used with SELECT, INSERT, UPDATE, and DELETE statements. | This Clause can only be used with the SELECT statement. |
Explore Popular Online Courses
Now, let’s move on to advanced-level SQL interview questions.
Advanced Level SQL Interview Questions
The following are the commonly asked advanced-level SQL and MySQL interview questions.
Q43. How to find:
duplicate records with one field?
duplicate records with more than one field?
Ans. Finding duplicate records with one field:
SELECT COUNT(field)
FROM table_name
GROUP BY field
HAVING COUNT(field) > 1
Finding duplicate records with more than one field:
SELECT field1,field2,field3, COUNT(*)
FROM table_name
GROUP BY field1,field2,field3
HAVING COUNT(*) > 1
Also Read>> Top Web Developer Interview Questions and Answers
Q44. What is a constraint, and how many levels of constraints are there?
Ans. Constraints are the representation of a column to enforce data entity and consistency. There are two levels of constraint –
- Column level – Limits only column data
- Table level – Limits whole table data
Following are the most used constraints that can be applied to a table:
- NOT NULL
- UNIQUE
- CHECK
- DEFAULT
- PRIMARY KEY
- FOREIGN KEY
Q45. What are the authentication modes in SQL Server?
Ans. SQL Server has two authentication modes –
- Windows Mode – Default. This SQL Server security model is integrated with Windows
- Mixed Mode – Supports authentication both by Windows and by SQL Server
We can change modes by selecting tools of SQL Server configuration properties and then hover over the security page.
Q46. What is PL/SQL?
Ans. PL/SQL or Procedural Language for SQL was developed by Oracle. It is an extension of SQL and enables the programmer to write code in a procedural format. Both PL/SQL and SQL run within the same server process and have features like – robustness, security, and portability of the Oracle Database.
Q47. What is SQL Profiler?
Ans. SQL Server Profiler is a graphical user interface for creating and saving data about each event of a file. It also allows a system administrator to analyze and replay trace results when a problem is being diagnosed. SQL Server Profiler is used to:
- Examine the problem queries to find the cause of the problem
- Diagnose slow-running queries
- Determine the Transact-SQL statements that lead to a problem
- Monitor the performance of the SQL Server
- Correlate performance counters to diagnose problems
Q48. What is the SQL Server Agent?
Ans. SQL Server Agent is a Microsoft Windows service that executes day-to-day tasks or jobs of SQL Server Database Administrator (DBA). This service enables the implementation of tasks on a scheduled date and time.
Also, Read>> Top Hadoop Interview Questions and Answers
Q49. What is Data Integrity?
Ans. Data integrity attributes to the accuracy, completeness, and consistency of the data in a database. It also refers to the safety and security of data and is maintained by a collection of processes, rules, and standards that were implemented during the design phase. Three types of data integrity are:
- Column Integrity
- Entity Integrity
- Referential Integrity
Q50. What is the difference between Rename and Alias?
Ans. Rename is actually changing the name of an object. Alias is giving another name (additional name) to an existing object. Rename involves changing the name of a database object and giving it a permanent name whereas Alias is a temporary name given to a database object.
Syntax of a table Alias:
SELECT column1, column2….
FROM table_name AS alias_name
WHERE [condition];
Syntax of a table Rename:
RENAME TABLE {tbl_name} TO {new_tbl_name};
Q51. Which are the main steps in Data Modeling?
Ans. Following are the main steps in Data Modeling:
- Identify and analyze business requirement
- Create a quality conceptual and logical data model
- Select the target database to create scripts for physical schema using a data modeling tool
Q52. What is Referential Integrity?
Ans. Referential integrity is a relational database concept that suggests that the accuracy and consistency of data should be maintained between primary and foreign keys.
Explore Free Online Courses with Certificates
Q53. What is Business Intelligence?
Ans. Business intelligence (BI) includes technologies and practices for collecting, integrating, analyzing, and presenting business information. It combines business analytics, data mining, data visualization, data tools and infrastructure, and best practices.
Q54. Mention the types of privileges available in SQL?
Ans. Following are the types of privileges used in SQL:
System Privilege: It deals with an object of a specific type and indicates actions on it which include admin that helps users to perform administrative tasks, alter any cache group, and alter any index.
Object Privilege: It helps users to perform actions on an object using commands like table, view, and indexes. There are other object privileges used in SQL EXECUTE, INSERT, SELECT, FLUSH, LOAD, INDEX, UPDATE, DELETE, REFERENCES, etc.
Q55. What is the difference between a clustered and non-clustered index?
Ans. Clustered Index – A clustered index is used to order the rows in a table. It has leaf nodes consisting of data pages. A table can possess only one clustered index.
Non-clustered Index – A non-clustered index stores the data and indices at different places. It also has leaf nodes that contain index rows. A table can possess numerous non-clustered indexes.
Q56. What is ERD?
Ans. ERD or Entity Relationship Diagram is a visual representation of the database structures and shows a relationship between the tables. The ER Diagrams have three basic elements:
- Entities – An entity is a person, place, thing, or event for which data is collected.
- Attributes – It refers to the data we want to collect for an entity. It is a property, trait, or characteristic of an entity, relationship, or another attribute.
- Relationships – It describes how entities interact.
Q57. How will you find the unique values, if a value in the column is repeatable?
Ans. To find the unique values when the value in the column is repeatable, we can use DISTINCT in the query, such as:
SELECT DISTINCT user_firstname FROM users;
We can also ask for several distinct values by using:
SELECT COUNT (DISTINCT user_firstname) FROM users;
Q58. Explain database white box testing.
Ans. White Box Testing is concerned with the internal structure of the database. The users are unaware of the specification details.
- Database white box testing includes testing of database triggers and logical views that support database refactoring.
- Validates database tables, data models, database schema
- Performs module testing of database functions and SQL queries
- Select default table values to check on database consistency
- Adheres to referential integrity rules
Q59. Exhibit the students who are having the same batch ID and study in the same department as student ids, 1002 and 1004.
Ans.
select x.student_id ,
x.department_id
from students x
where (department_id, batch_id)
in (Select department_id , batch_id
from students
where student_id in (1002,1004))
and x.student_id not in (1002, 1004)
Q60. What is the ACID property in SQL?
Ans. ACID is short for Atomicity, Consistency, Isolation, Durability. It ensures Data Integrity during a transaction.
Atomicity: It means either all the operations (insert, update, delete) inside a transaction take place or none. So, if one part of any transaction fails, the entire transaction fails and the database state is left unchanged.
Consistency: Consistency ensures that the data must meet all the validation rules. Irrespective of whatever happens in the middle of the transaction, Consistency property will never leave your database in a half-completed state.
Isolation: It means that every transaction is individual. One transaction can’t access the result of other transactions until the transaction is completed.
Durability: It implies that maintaining updates of committed transactions is important. These updates must never be lost. It refers to the ability of the system to recover committed transaction updates if either the system or the storage media fails.
Also Read>> Top MongoDB Interview Questions and Answers
Q61. Explain string functions in SQL?
Ans. SQL string functions are used for string manipulation.
Following are the extensively used SQL string functions:
- UPPER(): Converts character data to upper case
- LOWER(): Converts character data to lower case
- SUBSTRING() : Extracts characters from a text field
- RTRIM(): Removes all whitespace at the end of the string
- LEN(): Returns the length of the value in a text field
- REPLACE(): Updates the content of a string.
- LTRIM(): Removes all whitespace from the beginning of the string
- CONCAT(): Concatenates function combines multiple character strings
Q62. What are the differences between the Primary key and the Unique key?
Ans. Differences between the Primary key and the Unique key are:
| Primary Key | Unique Key |
| Enforces column uniqueness in a table | Determines a row that isn’t a primary key |
| Does not allow NULL values | Accepts one NULL value |
| Has only one primary key | Has more than one unique key |
| Creates clustered index | Creates non-clustered index |
| Primary Key on CREATE TABLE Syntax: CREATE TABLE Students ( ID int NOT NULL PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int); | Unique Key on CREATE TABLE Syntax: CREATE TABLE Students ( ID int NOT NULL UNIQUE, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int); |
Try explaining these differences in the answer for this basic SQL interview question.
Q63. Write the SQL query to convert the string to UPPERCASE and LOWERCASE.
Ans. The SQL query used to convert the string to UPPERCASE and LOWERCASE is:
STRING UPPER(“naukrilearning”); => NAUKRILEARNING
STRING LOWER(“LEARNERS”); => learners
Q64. What is the procedure to hide a specific table name of the schema?
Ans. By using SYNONYMS, we can hide a specific table name of the schema.
Syntax:
CREATE SYNONYM STU for STUDENTS;
After creating the above synonym, we can access the data of the STUDENTS table using STU as the table name below
SELECT * from STU;
Q65. What is the syntax to eliminate duplicate rows?
Ans. By using the DISTINCT keyword, we can eliminate duplicate records.
Syntax:
SELECT DISTINCT CLASS_ID
FROM STUDENTS;
Q66. Find out nth highest salary from emp table?
Ans. Syntax:
select salary from
(select salary, rownum EP from
(select salary from employees
order by salary desc))
where EP=n;
Q67. Name the encryption mechanisms in the SQL server.
Ans. This is one of the most popular SQL interview questions. The encryption mechanism used in SQL servers are –
- Transact-SQL functions – Individual items can be encrypted as they are inserted or updated using Transact-SQL functions.
- Asymmetric keys – It is made up of a private key and the corresponding public key. Each key can decrypt data encrypted by the other.
- Symmetric keys – It is used for both encryption and decryption.
- Certificates – Also known as a public key certificate, it binds the value of a public key to the identity of the person, device, or service that holds the corresponding private key.
- Transparent Data Encryption – It is a special case of encryption using a symmetric key that encrypts an entire database using that symmetric key.
Q68. What is the procedure to pass variables in a SQL routine?
Ans. Variables can be passed to a SQL routine by using:
- “&” symbol
- SQLPLUS command
Also Read>> Top Database Interview Questions and Answers
Q69. Can a view be updated/inserted/deleted? If yes, at what conditions?
Ans. It is not possible to add the data through a view if the view contains the following:
- Group by clause
- Group functions
- DISTINCT keyword
- Columns defined by expressions
- Pseudo column ROWNUM keyword
- NOT NULL column in the base table that is not selected by the view.
Q70. How can you create an SQL table from another table without copying any values from the old table?
Ans. Syntax:
CREATE TABLE new_table
AS (SELECT *
FROM old_table WHERE 1=2);
This will create a new table with the same structure as the old table with no rows copied.
Q71. Explain what is an inline view?
Ans. An inline view is a SELECT statement in the FROM-clause of another SELECT statement. In-line views are used to reduce complex queries by removing join operations and summarizing multiple separate queries into a single query.
Syntax:
SELECT SALARY FROM
(SELECT SALARY, ROWNUN EP FROM
(SELECT SALARY FROM EMPLOYEES ORDER BY SALARY DESC) )
WHERE EP=7
Q72. What command is used to create a table by copying the structure of another table?
Ans. Syntax:
CREATE TABLE STU AS
SELECT * FROM STUDENTS
WHERE 1=2
Invalid Condition
We have to give the invalid condition in the where clause, where the whole data will copy to the new table (STU table).
Q73. Mention the use of the DROP option in the ALTER TABLE command.
Ans. The use of the DROP option in the ALTER TABLE command is to drop a particular COLUMN.
Syntax:
ALTER TABLE TABLE_NAME
DROP COLUMN COLUMN_NAME
Q74. What are the aggregate functions in SQL?
Ans. SQL aggregate functions allow us to return a single value, which is calculated from values in a column.
Following are the aggregate functions in SQL:
- AVG() : This function returns the average value
- COUNT(): This function returns the number of rows
- MAX() : It returns the largest value
- MIN() : This function returns the smallest value
- ROUND(): This function rounds a numeric field to the number of decimals specified
- SUM() : It returns the sum
Q75. Write the SQL query to update the student names by removing leading and trailing spaces.
Ans. This can be done by using ‘Update’ command with ‘LTRIM’ and ‘RTRIM’ function.
Syntax:
UPDATE StudentDetails
SET FullName = LTRIM(RTRIM(FullName));
Q76. Write the SQL query to fetch alternate records from a table
Ans. Records can be fetched for odd and even row numbers:
- Syntax to fetch even numbers:
Select employeeId from (Select rowno, employeeId from employee) where mod(rowno,2)=0
- Syntax to fetch odd numbers:
Select employeeId from (Select rowno, employeeId from employee) where mod(rowno,2)=1
Q77. How do you return a hundred books starting from the 15th?
Ans. The syntax will be:
SELECT book_title FROM books LIMIT 15, 100.
The first number in LIMIT is the offset, and the second is the number.
Q78. How will the query select all teams that lost either 1, 3, 5, or 7 games?
Ans. We will use-
SELECT team_name FROM teams WHERE team_lost IN (1, 3, 5, 7)
Q79. How will you delete a column?
Ans. We can delete a column by –
ALTER TABLE techpreparation_answers DROP answer_user_id.
Q80. What is the meaning of this query – Select User_name, User_isp From Users Left Join Isps Using (user_id)?
Ans. It means:
SELECT user_name, user_isp FROM users LEFT JOIN isps WHERE users.user_id=isps.user_id
Q81. How will you see all indexes defined for a table?
Ans. By using:
SHOW INDEX FROM techpreparation_questions;
Q82. How would you change a table to InnoDB?
Ans. By using:
ALTER TABLE techpreparation_questions ENGINE InnoDB;
Q83. Name the default port for the MySQL server.
Ans. The default port for the MySQL server is 3306.
Q84. What is the possible way to add five minutes to a date?
Ans. By using:
ADDDATE(techpreparation_publication_date, INTERVAL 5 MINUTE)
Q85. What is the possible way to convert between Unix timestamps and Mysql timestamps?
Ans. Example:
UNIX_TIMESTAMP converts from MySQL timestamp to Unix timestamp
FROM_UNIXTIME converts from Unix timestamp to MySQL timestamp
Q86. How do you implement Enums and sets internally in MySQL?
Ans. To implement an ENUM column, use the given syntax:
CREATE TABLE table_name ( … col ENUM (‘value1′,’value2′,’value3’), … );
Q87. How can we restart SQL Server in the single user or the minimal configuration modes?
Ans. The command line SQLSERVER.EXE used with ‘–m’ will restart SQL Server in the single-user mode.
The command line SQLSERVER.EXE used with ‘–f’ will restart it in the minimal configuration mode.
Q88. What is the use of the tee command in Mysql?
Ans. Tee is a UNIX command that takes the standard output of a Unix command and writes it to both the terminal and a file. Tee followed by a filename turns on MySQL logging to a specified file. It can be paused by a command note.
Q89. Is it possible to save your connection settings to a conf file?
Ans. Yes, it is possible, and you can name it ~/.my.conf. You can also change the permissions on the file to 600 so that it’s not readable by others.
Q90. How to convert numeric values to character strings?
Ans. We can convert numeric values to character strings by using the CAST(value AS CHAR) function, as shown in the following examples:
SELECT CAST(4123.45700 AS CHAR) FROM DUAL;
4123.45700
Q91. Use mysqldump to create a copy of the database?
Ans. mysqldump -h mysqlhost -u username -p mydatabasename > dbdump.sql
Q92. What are federated tables?
Ans. Federated tables allow access to the tables situated on other databases on other servers in MySQL. It lets you access data from a remote MySQL database without using replication or cluster technology. Querying a local FEDERATED table pulls the data from the remote (federated) tables. Data is not stored on the local tables.
Q93. What are the different groups of data types in MySQL?
Ans. There are three groups of data types in MySQL, as listed below:
String Data Types – BINARY, VARBINARY, TINYBLOB, CHAR, NCHAR, VARCHAR, NVARCHAR, TINYTEXT, BLOB, TEXT, MEDIUMBLOB, LONGBLOB, LONGTEXT, ENUM, SET, MEDIUMTEXT.
Numeric Data Types – MEDIUMINT, INTEGER, BIGINT, FLOAT, BIT, TINYINT, BOOLEAN, SMALLINT, DOUBLE, REAL, DECIMAL.
Date and Time Data Types – TIMESTAMP, TIME, DATE, DATETIME, YEAR.
Q94. What is the procedure to concatenate two character strings?
Ans. To concatenate various character strings into one, you can use the CONCAT() function. Example:
SELECT CONCAT(’Naukri’,’ Learning’) FROM DUAL;
Shiksha Online
SELECT CONCAT(‘Learner’,’Thing’) FROM DUAL;
Learner Thing
Q95. What is the procedure to change the database engine in Mysql?
Ans. By using:
ALTER TABLE EnterTableName ENGINE = EnterEngineName;
Q96. What is the default storage engine in MySQL?
Ans. InnoDB is the default storage engine in MySQL.
Q97. What is COALESCE?
Ans. COALESCE returns the first non-NULL expression within its arguments from more than one column in the arguments.
The syntax for COALESCE is –
COALESCE (expression 1, expression 2, … expression n)
Q98. What syntax is used to create an index in MySQL?
Ans. By using-
CREATE INDEX [index name] ON [table name]([column name]);
Q99. How to store videos in SQL Server table?
Ans. We use the FILESTREAM datatype to store videos in SQL server table.
Q100. Explain the use of the NVL() function.
Ans. The NVL()function converts the Null value to the other value.
Q101. What are the different storage engines/table types present in MySQL?
Ans. MySQL supports two types of tables: transaction-safe tables (InnoDB and BDB) and non-transaction-safe tables (HEAP, ISAM, MERGE, and MyISAM).
- MyISAM: This is a default table type that is based on the Indexed Sequential Access Method (ISAM). It extends the former ISAM storage engine. These tables are optimized for compression and speed.
- HEAP: It allows fast data access. However, the data will be lost if there is a crash. HEAP table cannot have BLOB, TEXT, and AUTO_INCREMENT fields.
- BDB: It supports transactions using COMMIT and ROLLBACK. It is slower than the others.
- InnoDB: These tables fully support ACID-compliant and transactions.
- MERGE: Also known as the MRG_MyISAM engine, MERGE is a virtual table that combines multiple MyISAM tables that have a similar structure to one table.
Q102. What are the differences between and MyISAM and InnoDB?
Ans. The following are the differences between and MyISAM and InnoDB
| MyISAM | InnoDB |
| No longer supports transactions | Supports transactions |
| It supports Table-level Locking | It helps in Row-level Locking |
| No longer assist ACID (Atomicity, Consistency, Isolation, and Durability) | Supports ACID property |
| Supports FULLTEXT index | Does not support FULLTEXT index |
Q103. What drivers are available in MySQL?
Ans. Below are the drivers available in MySQL:
- PHP Driver
- C WRAPPER
- ODBC Driver
- JDBC Driver
- PYTHON Driver
- RUBY Driver
- PERL Driver
- CAP11PHP Driver
- Ado.net5.mxj
Q104. What is a Join? What are the different types of joins in MySQL?
Ans. Join is a query that retrieves related columns or rows. There are four types of joins in MySQL:
- Inner Join – it returns the rows if there is at least one match in two tables.
- Left Join – returns all the rows from the left table even if there is no match in the right table.
- Right Join – returns all the rows from the right table even if no matches exist in the left table.
- Full Join – would return rows when there is at least one match in the tables.
Q105. What is a pattern matching operator in SQL?
Ans. The pattern matching operator in SQL allows you to perform a pattern search in data if you have no clue as to what that word should be. Rather than writing the exact word, this operator uses wildcards to match a string pattern. The LIKE operator is used with SQL Wildcards to get the required information.
LIKE operator is used for pattern matching in the below format:
- % – It matches zero or more characters.
For Example – To search for any employee in the database with the last name beginning with the letter A
SELECT *
FROM employees
WHERE last_name LIKE ‘A%’
- _ (Underscore) – it matches exactly one character.
For Example – This example matches only if A appears at the third position of the last name
SELECT *
FROM employees
WHERE last_name LIKE ‘_ _A%’
Q106. What is a Stored Procedure? What are its advantages and disadvantages?
Ans. A Stored Procedure is an SQL function that consists of several SQL statements to access the database system. It can be stored for later use and can be used many times. If you have to perform a particular task, repeatedly, you won’t have to write the statements repeatedly, you will just have to call the stored procedure. This saves time and avoids writing code again.
Syntax: To create a stored procedure
CREATE PROCEDURE procedure_name
AS
sql_statement
GO;
Syntax: To execute a stored procedure
EXEC procedure_name;
Advantages of Stored Procedure:
- Execution becomes fast and efficient as stored procedures are compiled once and stored in executable form.
- A Stored Procedure can be used as modular programming. Once created and stored, it can be called repeatedly, whenever required.
- Maintaining a procedure on a server is easier than maintaining copies on different client machines.
- Better security.
Disadvantages of Stored Procedure:
- It can be executed only in the database and utilizes more memory in the database server.
- Any data errors in handling stored procedures are not generated until runtime.
- Version control is not supported.
Q107. Explain the STUFF and REPLACE functions.
Ans. This is one of the commonly asked SQL interview questions.
The STUFF function deletes a substring of a certain length of a string and replaces it with a new string. It inserts the string at a given position and deletes the number of characters specified from the original string.
Syntax:
STUFF (string_expression, start, length, replacement_string)
Parameters:
- string_expression: the main string in which the stuff is to be applied.
- start: starting position of the character in string_expression.
- length: length of characters that need to be replaced.
- replacement_string: a new string that is to be applied to the main string.
The REPLACE function replaces all occurrences of a specific string value with another string.
Syntax:
REPLACE (string_expression, search_string, replacement_string)
Parameters:
- string_expression: the main string that contains the substring to be replaced.
- Search_string: to locate the substring.
- replacement_string: the new replacement string.
Q108. What is a Database Cursor?
Ans. A database cursor is a mechanism that allows for traversal over the records in a database. Cursors also allow processing after traversal, like retrieval, addition, and deletion of database records. A cursor is behaviorally similar to the programming language iterator.
How to use a Database Cursor in SQL Procedures
- Declare variables.
- Declare a cursor that defines a result set. The cursor declaration must always be associated with a SELECT Statement.
- Open the cursor to initialize the result set.
- FETCH statement to retrieve and move to the next row in the result set.
- Close the cursor.
- Deallocate the cursor.
Q109. What are SQL Scalar functions? Name some.
Ans. An SQL scalar function returns a single value based on the user input. Below are some of the commonly used scalar functions:
| SQL Scalar Function | Format | Description |
| LCASE() | SELECT LCASE(column_name) FROM table_name; | converts the value of a field to lowercase |
| UCASE() | SELECT UCASE(column_name) FROM table_name; | converts the value of a field to uppercase |
| LEN() | SELECT LENGTH(column_name) FROM table_name; | returns the total length of the value in a text field |
| ROUND() | SELECT ROUND(column_name,decimals) FROM table_name; | rounds a numeric field to the number of decimals specified |
| NOW() | SELECT NOW() FROM table_name; | returns the current system date and time |
| FORMAT() | SELECT FORMAT(column_name,format) FROM table_name; | sets the format to display a collection of values |
Q110. What is the difference between SQL and PL/SQL?
Ans. This is an important question that you must prepare for your SQL interview.
Below are some of the major differences between SQL and PL/SQL:
| SQL | PL/SQL |
| SQL is a database Structured Query Language. | PL/SQL or Procedural Language/Structured Query Language is a database programming language using SQL. It is a dialect of SQL to enhance SQL capabilities. |
| It was developed by IBM Corporation and first appeared in 1974. | It was developed by Oracle Corporation in the early 90s. |
| Data variables are not available. | Data variables are available. |
| SQL is a declarative language. | PL/SQL is a procedural language. |
| It is data-oriented. | PL/SQL is application-oriented. |
| It can execute only a single query at a time. | It can execute a whole block of code at a time. |
| SQL can directly interact with the database server. | PL/SQL cannot directly interact with the database server. |
| It can be embedded in PL/SQL. | It cannot be embedded in SQL. |
| SQL is used to write queries, DDL, and DML statements. | It is used to write program blocks, functions, procedures triggers, and packages |
| SQL acts as the source of data that is to be displayed. | PL/SQL acts as a platform where SQL data will be displayed. |
Q111. Explain SQL comments.
Ans. SQL comments help in explaining the sections of the SQL statements. They also help in avoiding the execution of SQL statements. There are three types of comments:
- Single line comments: They start and end within a single line. Single line comments start with –. The text between — and the end of the line is not executed.
- Multi-line comments: These comments start in one line and end in a different one. Any text between /* and */ will not be executed.
- Inline comments: They are an extension of multi-line comments. We can write the comments between the statements enclosed within ‘/*’ and ‘*/.’
Conclusion
These are the top SQL interview questions that you should prepare. Elaborate on the simple questions, maintain honesty while approaching challenging questions, and be confident!
FAQs
What are the best online resources to learn SQL
There are various resources to learn SQL online like SQL courses, online tutorials, and ebooks. If you wish to take up an online course, then you can visit the Naukri Learning website. It is a one-stop destination for the best online courses. It lists the most popular courses covering various domains like technology, management, data science, and more from the top universities courses.
How can I start a career in the field of Database?
You can start a career in the field of Database by following this career path: 1. Take up an online Database course. 2. Learn SQL and Oracle. 3. Get hands-on experience through online case studies and practice cases. 4. Search for junior database developer roles. 5. Move into senior database jobs.
How long does it take to learn SQL?
If you are a beginner, it will take you around two to three weeks to understand the basic concepts of SQL and start working with SQL databases.
Is SQL hard to learn?
No. If you are an average learner, then it will not be difficult to learn SQL. It is also an English-like qury language that can be understood by anyone who understands English at a basic level.
Is SQL harder than Python?
No, SQL is not harder than Python. The syntax of SQL is much simpler than the syntax of Python.
What is the use of MySQL?
MySQL is an essential part of the modern web application. It is a popular database software which many of the world's largest organizations rely on for their critical business applications. The knowledge of MySQL is a common requirement for any web developeru2019s job.
What is the career outlook of database jobs?
There are huge opportunities for database professionals who are capable of analyzing, managing, and securing data because database management systems are widely used by organizations to increase organizational accessibility to data.
Can I get a job with SQL?
Job opportunities are extensive in the field of SQL and companies are ready to pay a good salary to the professionals with the right skill sets and knowledge.
Which are the top companies using MySQL?
The top companies using MySQL are Uber, Airbnb, Netflix, Amazon, and Twitter.
What are the educational requirements to become an SQL developer?
To become an SQL developer, you will need a bachelor's degree in computer science or a related field. You also need to be proficient in SQL programming and databases. In addition to this, candidates applying for senior-level SQL positions also need to have a few years of experience as an SQL developer or similar roles.
How much do SQL developers earn in India?
Entry-level SQL developers earn a salary of around Rs. 2,85,500 per year while a mid-level SQL developer can expect a salary of around Rs. 6,80,500 per year. An experienced SQL developer can earn about Rs. 12,00,000 per year.
