
K-fold Cross-validation
Cross-validation is a resampling technique used to validate machine learning models against a limited sample of data. In this article we will talk about K-fold Cross-validation and its advantages and disadvantages.Its working is shown with python program.

The concept of cross-validation is widely used in data science and machine learning. It’s a way to verify the performance of a predictive model before using it in an actual situation. Essentially, it helps you avoid creating inaccurate predictions. Using multiple training sets is crucial when performing cross-validation. You must have multiple test sets to ensure your model performs as expected.In this article we are going to learn about K-fold Cross-validation.
Table of contents
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
What is cross-validation?
Cross-validation is a resampling technique used to estimate the power of machine learning models. Cross-validation is primarily required to estimate your predictive model’s performance accuracy.
After training a model, it is not guaranteed that the model will perform well on unseen data. The model should be validated. This validation process is called cross-validation. Cross-validation is a standard procedure in data analysis, and it’s commonly used to determine the reliability of machine learning algorithms. It’s a vital step when building models for real-world applications. Consider a car that needs to be calibrated before driving. That person would verify that his vehicle operates safely before using it in the field. In the same way, an algorithm’s performance must be verified before being used in the field. Otherwise, it could lead to accidents or create invalid results for users.


 Read Later
Read Later

Also Read: How tech giants are using your data?
Also read:What is machine learning?
Also read :Machine learning courses
K-fold cross validation
In K-fold cross-validation, the data set is divided into a number of K-folds and used to assess the model’s ability as new data become available. K represents the number of groups into which the data sample is divided. For example, if you find the k value to be 5, you can call it 5-fold cross-validation. Each fold is used as a test set at some point in the process.
- Randomly shuffle the dataset.
- Divide the dataset into k folds
- For each unique group:
- Use one fold as test data
- Use remaining groups as training dataset
- Fit model on training set and evaluate on test set
- Keep Score
4. Get accuracy score by applying mean to all the accuracies received for all folds.
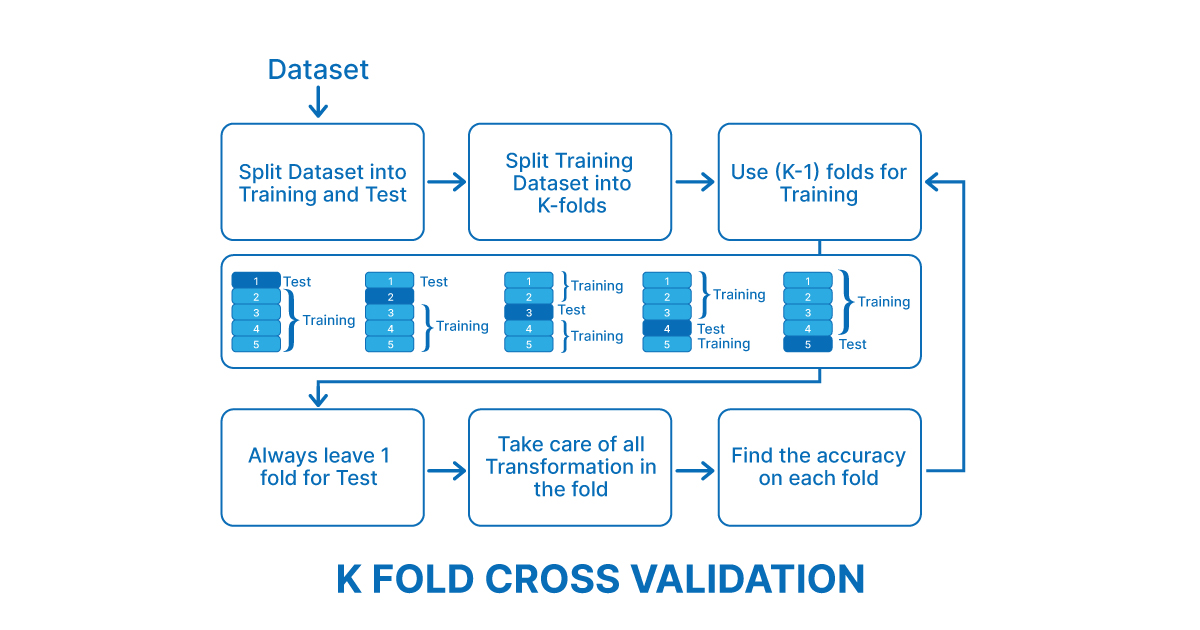

As you can see in the fig that there is a dataset which is Divided into 5 folds. That means there will be five iterations, and in each iteration, there will be one test fold, and the other four folds will be training folds. And in each iteration, test and training folds keep on changing. That means if we have 1000 records in our data set, then suppose 200 records are our test data, and 800 records are our training data.
So in the first iteration, (1-200) records will be test data, and (201-1000) will be training data. In the second iteration, (1-200) records plus (401-1000) represent training data, And (200 -400) will represent the test data. And so on…
Also read:Sensitivity vs. Specificity: What’s the Difference?
How to set the Value of K in K-fold cross-validation?
Choose a value for ‘k’ so the model can avoid large variance and significant distortion. In most cases, the choice of k is usually 5 or 10, but there is no formal rule. However, the Value of k depends on the size of the dataset. Running time of cross-validation algorithm and complexity for large values of k.
If you want to understand this with the python code, then
Check out How to choose the Value of k in K-fold Cross-Validation
Advantages of K-fold cross validation
- Stable accuracy: This will solve the random precision issue. In other words, stable accuracy can be achieved. The model is trained on a dataset split into multiple folds.
- Overfitting: This prevents the overfitting of the training data set.
- Model Generalization Validation: Cross-validation gives insight into how the model generalizes to unknown data sets
- Validate model performance: Cross-validation allows you to accurately estimate your model’s predictive performance.
Also read:Difference between Accuracy and Precision
Explore: How to Calculate R squared in Linear Regression
Explore: R-squared vs. adjusted R-squared
Disadvantages of K-fold cross validation
- Don’t work on an imbalanced dataset: If your data is imbalanced (if you have class “A” and class “B,” the training set has class “A” and the test set has class “B”), it doesn’t work well.
- Increased training time: Cross-validation requires training the model on multiple training sets.
- Computationally expensive: Cross-validation is computationally expensive as it needs to be trained on multiple training sets.
K-fold cross-validation python
About dataset
We implemented cancer_dataset, which is freely available on Kaggle.This dataset diagnosis cancer if it’s benign or malignant.
- id: ID number
- diagnosis: The diagnosis of breast tissues (M = malignant, B = benign)
- radius_mean: mean of distances from the center to points on the perimeter
- texture_mean: standard deviation of gray-scale values
- perimeter_mean: mean size of the core tumor
- area_mean: area of the tumor
- smoothness_mean: mean of local variation in radius lengths
- compactness_mean: mean of perimeter^2 / area – 1.0
- concavity_mean: mean of the severity of concave portions of the contour
- concave_points_mean: mean for a number of concave portions of the contour
- symmetry_mean
- fractal_dimension_mean: mean for “coastline approximation” – 1
- radius_se: standard error for the mean of distances from the center to points on the perimeter
- texture_se: standard error for a standard deviation of gray-scale values
- perimeter_se
- area_se
- smoothness_se: standard error for local variation in radius lengths
- compactness_se: standard error for perimeter^2 / area – 1.0
- concavity_se: standard error for the severity of concave portions of the contour
- concave_points_se: standard error for the number of concave portions of the contour
- symmetry_se
- fractal_dimension_se: standard error for “coastline approximation” – 1
- radius_worst: “worst” or largest mean Value for the mean of distances from the center to points on the perimeter
- texture_worst: “worst” or largest mean Value for a standard deviation of gray-scale values
- perimeter_worst
- area_worst
- smoothness_worst: “worst” or largest mean Value for local variation in radius lengths
- compactness_worst: “worst” or largest mean Value for perimeter^2 / area – 1.0
- concavity_worst: “worst” or largest mean value for the severity of concave portions of the contour
- concave_points_worst: “worst” or largest mean value for a number of concave portions of the contour
- symmetry_worst
- fractal_dimension_worst: “worst” or largest mean Value for “coastline approximation” – 1
Importing libraries and loading dataset
import pandas as pdimport numpy as npdf= pd.read_csv('cancer_dataset.csv') df

Independent And dependent features
X=df.iloc[:,2:]y=df.iloc[:,1]X=X.dropna(axis=1)X
Splitting data into training and testing data
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=4)
Implementing k fold cross validation and logistic regression
from sklearn.ensemble import RandomForestClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import KFoldkfold_validation=KFold(10)lr = LogisticRegression(solver='liblinear',multi_class='ovr')lr.fit(X_train, y_train)lr.score(X_test, y_test)
Output: 0.9181286549707602
Implementing random forest algorithm
rf = RandomForestClassifier(n_estimators=40)rf.fit(X_train, y_train)rf.score(X_test, y_test)
Output: 0.935672514619883
Now check the accuracies of these two models using K-fold validation technique.
Checking accuracy of linear regression after k fold cross validation
from sklearn.model_selection import cross_val_scoreresults=cross_val_score(lr,X,y,cv=kfold_validation)print(results)print(np.mean(results))
Output
0.950814536340852
Checking the accuracy of a random forest after k-fold cross validation
results=cross_val_score(rf,X,y,cv=kfold_validation)print(results)print(np.mean(results))
Output
0.9490288220551377
Summary
| Algorithm | Before applying k-Fold cross validation | After applying k-Fold cross validation |
| Linear regression | 0.91 | 0.95 |
| Random forest | 0.93 | 0.94 |
We can conclude that afer implementing K-fold cross validation linear regression and random forest showed improved accuracies.
Conclusion
Cross-validation is an important tool that every data scientist should use, or at least be well mastered. This will allow us to make better use of all the data and help data scientists, machine learning engineers, and researchers better understand the performance of their algorithms. Confidence in the model is important for future deployment and for the model to be effective and perform well.
