
Handling missing data: Mean, Median, Mode
So what all steps do we actually perform in what kind of order to complete the feature engineering process. Now in a data science project if we just consider feature engineering it takes somewhere around 30 % of the entire project time so it is a big amount of time. The most important step in feature engineering is handling missing data.

While doing a machine learning project, we get confused that what should be the exact order after getting the raw data? What should I do first? The steps are:
- Feature engineering
- Feature selection
- Model creation
- Hyperparameter tuning
- Model deployment
- Incremental learning
and there are many more steps as such but the most important crux of the entire data science project is feature engineering because you will be cleaning the data you will be doing a lot of steps. Data cleaning is required in the starting because we are suppose collecting data from different sources may be from different websites. So the unprocessed data must be containing:
- Missing values
- Outliers
- Unstructured manner
- Imbalanced data
- Categorical data(which needs to be converted to numerical variables)
NOTE: This unprocessed data has to be handled first.
We have started a series of blogs on the topic ‘Feature Engineering’.We have already covered blogs on handling numerical and categorical values. In the previous blogs, we had talked about the missing values-For beginners. Specifically we covered Interpolation(),fillna(),dropna() in that.

NOTE-In the end, there is an assignment for your practice. Try to understand the code and do that assignment.
Feature engineering steps:
- Exploratory Data Analysis
- Handling missing values
- Handling imbalanced dataset
- Handling outliers
- Scaling down the data(Standardization and Normalisation)
- Converting categorical data to numerical data(One hot encoding, Label encoding)
- Feature extraction(This is not exactly included in feature engineering)
NOTE: Don’t think that you’ll just be able to do the feature engineering process in one day or two days. If you have a small data set then you will be able to do it in three to four hours but dealing with a large dataset requires more time.
Table of contents
- Why are there missing values?
- What are the different types of Missing Data?
- Mean/ Median /Mode imputation
- Advantages and Disadvantages of Mean/Median Imputation
- Python code
- Assignment
- Endnotes

 Read Later
Read Later

Why is there missing data?
Missing data causes problems when a machine learning model is applied to the dataset. Mostly machine learning models don’t process the data with missing values.
- They hesitate to put down the information
- Survey information is not that valid
- Hesitation is sharing the information
- People may have died—-NAN
Data Science Projects—Dataset should be collected from multiple sources
What are the different types of Missing data?
- Missing Completely at Random(MCAR)
A variable is missing completely at random (MCAR) if the probability of being missing is the same for all the observations. When data is MCAR, there is absolutely no relationship between the missing data and any other values, observed or missing, within the dataset. In other words, those missing data points are a random subset of the data. There is nothing systematic going on that makes some data more likely to be missing than others.
- Missing Data Not At Random(MNAR)
Systematic missing Values There is absolutely some relationship between the data missing and any other values, observed or missing, within the dataset. In this case, the missingness of a value is dependent on the value itself. For example, in surveys, students with lower marks, are less likely to respond to questions about how much they scored, and therefore the lower values are missing because they’re low.
Mean/ Median /Mode imputation
We solve this missing value problem by replacing the NAN values with the Mean/ Median /Mode
- Mean: It is the average value.
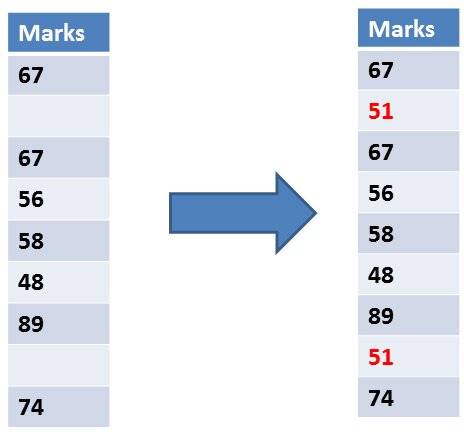
In this, we calculated the mean(average) of all the observed data and got 51 as the mean and replaced it in place of missing values.
2. Median: It is the midpoint value.

In this, we calculated the median(center value) of all the present values and got 58 as the median, and replaced it in place of missing data.
3. Mode: It is the most common value.

In this, we calculated the mode(most frequently occurring value) of all the present values and got 67 as mode, and replaced it in place of missing values.
This is the most common method of data imputation, where you just replace all the missing data with the mean, median, or mode of the column. If you’re in a rush this is useful because it’s easy and fast, it changes the statistical nature of the data. The drawback is it skews the histograms and also underestimates the variance in the data. No doubt, this practice is very common, but it should be avoided. It should never be used if your data is MNAR.
- Mean-It is preferred if data is numeric and not skewed.
- Median-It is preferred if data is numeric and skewed.
- Mode-It is preferred if the data is a string(object) or numeric.
When should we apply Mean/Median?
Mean/median imputation has the assumption that the data are missing completely at random(MCAR). After handling the outliers try to handle the missing data by the median in short if you don’t want the impact of the outliers you can directly use median or mode right
Advantages and Disadvantages of Mean/Median Imputation
Advantages
- Simple to implement(Robust to outliers)
- The faster way to fill the missing values in the complete dataset
Disadvantages
- Change in the original variance
- It impacts the Correlation
Python code: Handling missing data
In this, we used the ‘titanic’ dataset. This dataset contains data related to passengers like their age, sex, survived, etc. In this, we are doing preprocessing by filling missing data using mean/median/mode. This dataset is freely available on kaggle.com.You can download it from there.
1. Importing and reading the file
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline df = pd.read_csv("train.csv", usecols=['Age','Fare','Survived']) df
This dataset contains other columns also but we have selected only three columns to make the example easily understandable for you.

2. Check how many NaN values are there
df.isnull().sum() Output: Survived 4 Age 179 Fare 2dtype: int64
We are checking how many missing values are there in it.
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')

3. Replacing the missing data with a mean value
df['Age'].fillna(df['Age'].mean(), inplace = True) df

All the NaN values are replaced by the mean of the Age column i.e. 29.68
4. Finding the median and replacing the NaN values with the median value

All the NaN values are replaced by the median of the Age column i.e. 28
5. Replacing the NaN with the mode value
df = pd.read_csv("train.csv", usecols=['Age','Fare','Survived']) df df['Age'].fillna(df['Age'].mode(), inplace = True) df

All the NaN values are replaced by the mode of the Age column i.e. 24
Assignment
I suggest that just reading the code won’t help you. So try to implement this for your practice:
- Download any dataset having a missing value. Else you can down the titanic.csv data set and start working.
- You can use JupyterNotebook or Google Colab browser version and start working if you don’t have this software installed on your computer.
- I have taken only three columns from this dataset you can handle the missing values of some other columns.
Endnotes
There is no single method to handle missing values. In the previous blog, we tried handling missing values by dropping the rows, using the interpolating method, and filling the values with some random variable or with 0. So before applying any methods, we have to understand the type datatype of missing values, then check the skewness of the missing column, and then apply the method which is best for a particular problem.
If you liked this blog then do share it with other data science aspirants. If you are interested in going into the data science field then you find different study material on this page.
