
Mean squared error in machine learning
In this article we will talk about Mean squared error with example.It also explains how to calculate mean squared error.Mean squared error is calculated using python programming.

Technological advancements are not free of error even though we make technological advancements with the intention of improving our life that intention does not guarantee success in factor common as people make is over estimating the capabilities of new technologies or processes this is where the mean squared error comes into play. MSE is a standard deviation that describes how far the prediction deviation from the actual output. Essentially,MSE helps you identify errors in your decision so that you can correct them and improve them before going forward. In this article we will understand the relationship of this method to the regression line.
Table of contents
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
What is mean squared error?
In statistics, the mean squared error (MSE) is defined as the mean or average of the squared differences between the actual and estimated values. Mean Squared Error (MSE) measures the amount of error in a statistical model. Evaluate the mean squared difference between observed and predicted values. If the model has no errors, the MSE is zero. Its value increases as the model error increases. The mean squared error is also known as the mean squared deviation (MSD). For example, in regression, the mean squared error represents the mean squared residual.
Where is the actual value
yi is the predicted value
And n is the number of observations
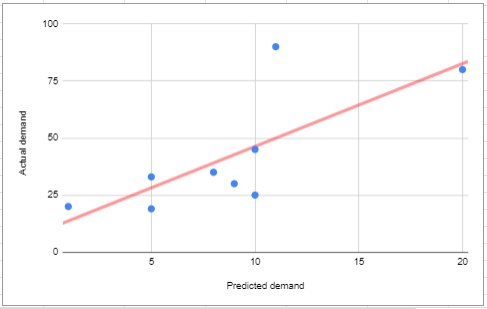
Blue dots indicate data points. The blue line represents the line fitted to the data points. Blue dots indicate predicted values. The red dotted line shows a loss. As you can see, the predicted values are far from the actual values , indicating a loss. This gives the difference between the predicted and actual values. This can be done for every data point.

Interpreting the Mean Squared Error
The interpretation could be more intuitive because square units are used instead of natural data units. Squaring the difference serves several purposes.
Squaring the difference eliminates the negative values of the difference and ensures that the mean squared error is always greater than or equal to zero. Most of the time, it is a positive value. Only perfect models with no errors produce an MSE of zero. And it doesn’t happen.
Also, squaring increases the effect of larger errors. Large errors are disproportionately penalized in these calculations over small errors. This property is important if you want to include minor errors in your model.
If the value of mean squared error(MSE) is higher, the predicted values are away from the actual values. So less MSE is required while predicting.

 Read Later
Read Later

Also Read: How tech giants are using your data?
Also read:What is machine learning?
Also read :Machine learning courses
How to calculate mean squared error
Suppose we want to predict the demand of sales for Reebok shoes. We have a data set having values of demand and predicted demand. The below data can be represented by this graph in which we have a regression line.
| Actual demand (yi) | Predicted demand (yi) | Actual demand- Predicted demand | Error(yi- yi) | Squared Error(yi- yi)2 |
| 11 | 90 | 51.45 | -38.55 | 1486.1025 |
| 10 | 45 | 48.30 | 3.30 | 10.89 |
| 5 | 19 | 32.55 | 13.55 | 183.6025 |
| 8 | 35 | 42.00 | 7.00 | 49 |
| 10 | 25 | 48.30 | 23.30 | 542.89 |
| 20 | 80 | 79.80 | -0.20 | 0.04 |
| 1 | 20 | 19.95 | -0.05 | 0.0025 |
| 9 | 30 | 45.15 | 15.15 | 229.5225 |
| 5 | 33 | 32.55 | -0.45 | 0.2025 |
| Equation of line= 3.15x+16.8 | Mean squared error=2502.25 |
General procedure for calculating MSE from a set of X and Y values:
- Find the regression line. You can do that easily by using Ms excel, where you have the option to make a scatter graph.
- Find a new y value (Y`), i.e., predicted demand, by plugging the x value into the linear regression equation. You can easily find the line equation by using an online line calculator. We got the equation of line as 3.15x +16.8.
Put the values like this-
3.15x+16.8= 3.15(11) +16.8= 51.4
3.15x+16.8= 3.15(10) +16.8=48.30
3.15x+16.8= 3.15(5) +16.8=32.55
3.15x+16.8= 3.15(8) +16.8=42.00
3.15x+16.8= 3.15(10) +16.8=48.30
3.15x+16.8= 3.15(20) +16.8=79.80
3.15x+16.8= 3.15(1) +16.8=19.95
3.15x+16.8= 3.15(9) +16.8=45.15
3.15x+16.8= 3.15(5) +16.8=32.55
- Subtract the predicted demand from the actual demand value to get the error. Square the error.
- Sum the errors (Σ in the formula is sum notation). Find the average. You will get a mean squared error.
Mean squared error python
Problem statement
We have to predict the weight of the fish.
About data set
This dataset contains seven species of fish data for market sale. We will perform it using python. The dataset used for this is Multiple Linear Regression Fish Weight Prediction, freely available on Kaggle.
1. Species–species name of fish
2. Weight- the weight of fish in Gram
3. Length1-vertical length in cm
4. Length2- diagonal length in cm
5. Length3- cross length in cm
6. Height-height in cm
7. Width-diagonal width in cm
What is a root mean square?
Root mean squared error (RMSE) is the square root of the mean of the square of all of the errors. RMSE is widespread, and it is considered an excellent general-purpose error metric for numerical predictions.

In other words, MSE is analogous to variance, and RMSE is related to standard deviation.
1. Importing Libraries and reading dataset
import pandas as pd
import numpy as np
df=pd.read_csv('Fish.csv')
df

2. Drop the categorical feature
dataset=dataset.drop(['Species'],axis=1)
In this dataset, we have one categorical feature, ‘species.’So we have two options here: either we can convert it into a numerical feature using one hot encoding. We have explained this topic in detail in our blog.
Please refer to Handling categorical variables with one-hot encoding
Also read: One hot encoding for multi-categorical variables
3. Dependent and independent variables
#Get Target data
y = dataset['Weight']
#Load X Variables into a Pandas Dataframe with columns
X = dataset.drop(['Weight'], axis = 1)
4. Splitting dataset into Training and Testing Set
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Next, split both x and y into training and testing sets with the help of the train_test_split() function. In this training data set is 0.8, which means 80%.
5. Importing and fitting Linear Regression to the Training set
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
X_train = X_train
model=regressor.fit(X_train,y_train)
6. Predicting the Test set results
# Predicting the test set results
y_pred = model.predict(X_test)
print(y_pred)
Output
[82.73439589 -161.53195552 408.44743721 304.46989813 184.13570068
779.30121032 -220.93220498 271.94477243 270.60857515 1158.4646432
605.18970226 792.83357948 580.72067025 169.08221724 658.47407202
794.45679379 932.49512526 352.99193875 263.13034668 587.15382293
-182.62160433 623.09360459 522.79407093 509.73730015 798.33212205
917.84252931 224.89937089 309.84893122 -244.62222252 -184.50495819
719.01865993 23.57308002 4.56036718 845.48962663 357.89814785
174.02241262 177.89225989 121.74113261 219.69595529 825.52690006
669.66357689 782.65263847 -220.70034112 169.37889455 173.91518347
31.15705015 138.49933509 634.65137188]
7. Checking the mean squared error
from sklearn.metrics import r2_score,mean_squared_error
print(“r2 score of our model is:”, r2_score(y_test,y_pred))
print(“mean absolute error of our model is:”, mean_squared_error(y_test,y_pred))
Output
r2 score of our model is: 0.8676045498644966
mean absolute error of our model is: 16217.627414316428
Conclusion
In statistics, mean squared error (MSE) is a risk function that measures squared error. If you think your targets are normally distributed and want to penalize more significant errors than smaller ones, use MSE when running the regression.
