
Multiple linear regression
Multiple linear regression refers to a statistical technique that is used to predict the outcome of a variable based on the value of two or more variables. In this article we are talking about multiple linear regression using real-life example.It is expalined by explaining python programming example also.
Most of the people are confused between linear regression and multiple linear regression algorithm. Multiple linear regression is the extension of linear regression. These both are used for regression problems. We have already covered linear regression. So lets learn about multiple linear regression now.
Table of contents
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
What is Multiple linear regression?
Multiple linear regression is a statistical technique for predicting the outcome of one variable based on the values of two or more variables. Sometimes called multiple regression, it is an extension of linear regression. The variable we want to predict is called the dependent variable, and the variables we use to predict the value of the dependent variable are called the independent or explanatory variables.

In other words, MLR analyses how multiple independent variables are related to the dependent variable. Once each independent factor for predicting the dependent variable is determined, information about multiple variables can be used to accurately predict the magnitude of their impact on the outcome variable. The model establishes a straight-line (linear) relationship that best fits the individual data points. Multiple linear regression can be used for checking
- The strength of the relationship between one dependent variable and two or more independent variables(e.g., how salary is calculated on the basis of a number of years of experience, number of certifications done, level of education).
- The dependent variable’s value is given the independent variables’ values (e.g., the expected salary depends on the given number of years of experience, the number of certifications done, and level of education).

 Read Later
Read Later

Also explore:
Real-life example of multiple linear regression
Suppose we have a dataset in which we have one independent feature like work experience(years) and salary as a dependent feature which means salary prediction is dependent on working experience. So we can use linear regression here.

But if we have more than one independent feature in our dataset. For, eg.
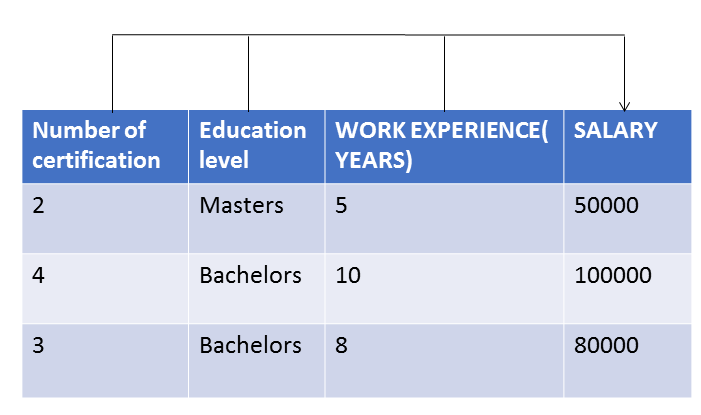
In this data set, we have independent features like the number of certifications, education level, and work experience, and the dependent feature is salary. So these independent features(the factors you suspect impact your dependent variable) are used to predict the salary. So now the question here comes can we use a linear regression model for this dataset? The answer is NO. Here we have to use a multi-linear regression model for salary prediction.

We have shown a small dataset in the below fig but is suppose we have a lot of data entries in employee_salary data set then our graph would look like this(as shown in fig above).The difference between graphs of linear and multiple regression is that in linear regression we get 2-D plot and in multiple linear regression we get 3-D plot.So we have x(axis)=Salary,y(axis)=Education level and z(axis)=Working experience. And another difference is that in linear regression we have regression line but in multiple linear regression we have hyperplane as shown in fig.
Also explore:
Programming Online Courses and Certification
Python Online Courses and Certifications
Data Science Online Courses and Certifications
Machine Learning Online Courses and Certifications
How to perform a multiple linear regression
Multiple linear regression formula
The formula for multiple linear regression is:
y= 0+1 X1+2 X2+………+n Xn
- y= the predicted value of the dependent variable
- 0= the y-intercept (value of y when all other parameters are set to 0)
- 1 X1= the regression coefficient (1) of the first independent variable (X1) (a.k.a. the effect that increasing the value of the independent variable has on the predicted y value).
- n Xn= the regression coefficient of the last independent variable
Multiple Linear Regression Assumptions
Multiple linear regression makes the same assumptions as simple linear regression.Normality: The data follow a normal distribution.
1. Observation Independence
Observations in the data set were collected using statistically valid methods and have no hidden relationships between variables.In multiple linear regression, some independent variables may be correlated with each other, so it is essential to check these before developing the regression model. If two independent variables are too strongly correlated (r2 > ~0.6), only one of them should be used in the regression model.
2. Homogeneity of variance (homogeneity of variances)
The magnitude of the prediction error does not vary significantly across the values of the independent variables.
3. Linearity
The best-fit line going through the data points is a straight line, not a curve or grouping factor.
Multiple linear regression sklearn
About data set
This dataset contains 7 species of fish data for market sale.We have to predict the weight of fish.We will perform it using python.The dataset uesd for this is Multiple Linear Regression Fish Weight Prediction which is freely available on kaggle.
1.Species–species name of fish
2. Weight- weight of fish in Gram
3. Length1-vertical length in cm
4. Length2- diagonal length in cm
5. Length3- cross length in cm
6. Height-height in cm
7. Width-diagonal width in cm
1. Importing Libraries and reading dataset
import pandas as pdimport numpy as npdataset= pd.read_csv('/content/Fish.csv') dataset

2. Plotting the graph between height and Weight
Plotting the graph between height and Weightdf = dataset[dataset['Species'] == 'Bream']import matplotlib.pyplot as plt plt.scatter(df['Weight'],df['Height'])

We are here trying to make scatter plot between weight and height for one specie(Bream).We make this scatterplot to check if the data is linear in nature.
3. Drop the categorical feature
Drop the categorical featuredataset=dataset.drop(['Species'],axis=1)
In this dataset we have one categorical feature ‘species’.So we have two options here either we can convert it into numerical feature using one hot encoding.
we have expleined this topic i detail in our blog
Please refer Handling categorical variables with one-hot encoding
One hot encoding for multi categorical variables
One hot encoding vs label encoding in Machine Learning
Else we can simply drop it if it dont have much relavance in predicting the output.
4. Dependent and independent variables
#Get Target data y = dataset['Weight'] #Load X Variables into a Pandas Dataframe with columns X = dataset.drop(['Weight'], axis = 1)
5. Splitting dataset into Training and Testing Set
# Splitting the dataset into the Training set and Test setfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Next, split both x and y into training and testing sets with the help of the train_test_split() function. In this training data set is 0.8 which means 80%.
6. Importing and fitting Linear Regression to the Training set
from sklearn.linear_model import LinearRegressionregressor = LinearRegression()X_train = X_trainmodel=regressor.fit(X_train,y_train)
7. Predicting the Test set results
y_pred = regressor.predict(X_test) from sklearn.metrics import r2_scorescore=r2_score(y_test,y_pred)score0.863
8. Find correlation to check if we can remove features
import seaborn as snsimport matplotlib.pyplot as plt #Using Pearson Correlationplt.figure(figsize=(12,10))cor = dataset.corr()sns.heatmap(cor, annot=True, cmap=plt.cm.CMRmap_r)plt.show()

From this heatmap we can conclude that weight feature have high corelation with all the features.So reoving feature here won’t help in improving accuracy score.
Conclusion
Multiple linear regression is used to evaluate predictors for continuously distributed outcome variables. This procedure computes a coefficient for each independent variable (predictor) that best fits the observed data in the sample.
