
Introduction to Neural Networks in Deep Learning
This article goes through explaining Neural Networks in Deep Learning under Machine Learning. It also covers various components and types of Neural Networks.

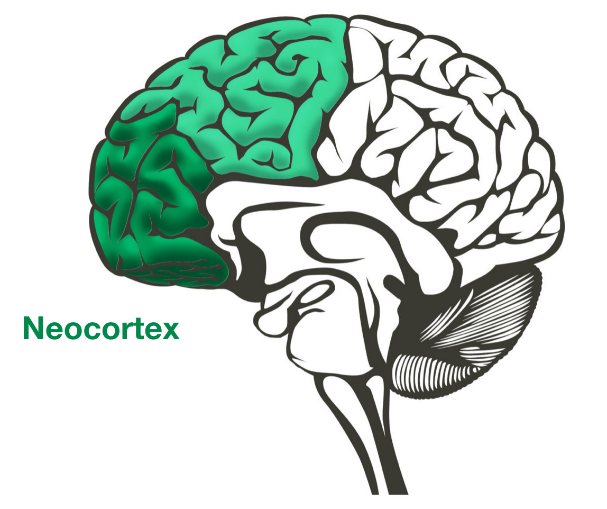
Deep Learning is a subfield of Machine Learning that is inspired by the way a human brain functions. To put it in the simplest form, just as humans learn and improve from experience, a deep learning algorithm learns from examples. Neural Networks, also referred to as Artificial Neural Networks (ANN) are at the heart of Deep Learning algorithms. Deep learning attempts to mimic the activity in the layers of neuron cells (in the neocortex part of the brain, as shown) through neural networks.
Also, Read: Deep Learning vs Machine Learning – Concepts, Applications, and Key Differences
This article will provide you with a brief introduction to the massive field of Deep Learning through Neural Networks. We will be covering the following sections today:
- What is Deep Learning?
- How Deep Learning Mimics Human Brain?
- Components of a Basic Neural Network
- What is the Perceptron?
- Artificial Neural Networks in Deep Learning
- Types of Neural Networks in Deep Learning
What is Deep Learning?
And how is it different from Machine Learning?
Deep Learning is conventionally different from Machine Learning in a way that it has shifted the focus from training machines to think and act with less human intervention, to training them to LEARN to think and act using neural networks modeled on the human brain.


Deep learning can work with complex images, videos, and unstructured data in ways that machine learning algorithms are not equipped to handle.
However, one must keep in mind that deep learning algorithms can be computationally expensive as they often require high-end GPUs for processing large volumes of data over numerous hours. So, for fairly simpler problems that require far less computational effort, we can use machine learning. ML algorithms are also a preferred choice for making predictions based on comparatively smaller datasets.
How Deep Learning Mimics Human Brain?
Whenever we receive new information, our brain tries to compare it with known objects. The same concept is used by deep learning! Let’s see how:

Let me vaguely brush up on your high school biology here – the dendrites, as shown above, receive stimuli signals and transmit them to the cell body. Here, the signals are processed to check if a response is required. In which case, a chemical transmission is triggered that passes through the axon to axon terminals, and then to other neuron cells.
The neural networks in a deep learning algorithm mimic this operation of the human brain – each artificial neuron or node takes an input, performs some operation on it, then passes it forward as an output. Lots of interconnected nodes interact and work together in this manner to pass information to each other and create some magic! Let’s understand how:
Components of a Basic Neural Network
The simplest neural network includes an input layer (on the left), an output or target layer (on the right), and a hidden layer in between. These layers are linked via nodes.

As the number of hidden layers increases, more complex neural networks are formed. These hidden layers are like a black box where all the magic happens!
To understand what goes on in these hidden layers and how a neural network works, let’s talk about a simple neural network that we call the Perceptron:
What is the Perceptron?
A single-layer perceptron, also called the perceptron, is the oldest simple neural network, created by Frank Rosenblatt in 1958. It represents a single unit of the neural network – pretty much the artificial equivalent of a neuron cell. Though its use has become obsolete as it has been replaced by more modern ‘neurons’, understanding its working is essential to our knowledge because a neural network works the same way.
The perceptron consists of 5 parts:
- Input layer
- Weights
- Summation & Bias
- Activation Function
- Output layer
Let’s understand how the perceptron works through its structure given below:

- Data is fed through the input layer that consists of one node for each component present in the input data x={x1 , x2 , x3 .. . xn}.
- Each input component is multiplied by their respective weights {w1, w2, w3 .. . wn}. Weights basically demonstrate the importance or strength of a particular input component – components of higher importance are assigned more weights.
- The input layer communicates to the hidden layer, which is a single node in the perceptron. The data is processed by this node through a system of weighted connections, commonly referred to as w (weights) and b (biases).
When the weighted inputs are received by the node, it calculates the weighted sum of inputs. Then adds Bias to the summation.
- The result is then applied to a pre-set Activation function. The above structure has an example of a step function. But there are more sophisticated examples such as sigmoid (σ), rectifier (relu), and hyperbolic tangent (tnh). The activation function decides whether a signal should be fired (output 0) or activated (output).
- The final output is triggered as either 1 or 0, as per the above example. Thus, a perceptron is a binary classifier.
Why is a Bias value-added?
The bias value is the threshold value that is added to the weighted sum to avoid passing no (0) output.
So,
i=1nwixi+bias could also be written as i=1nwixi=-bias=threshold, where the activation function (step function in the above case) would be given as:
fx={1=if wixi≥threshold 0=if wixi<threshold
.
Why use Activation Functions?
An activation function is a form of non-linear function that is used to map the input between the desired output values such (0, 1) or (-1, 1).
In neural networks with multiple layers, the activation functions determine the extent to which a signal must progress through the network to affect the final output.
Without an activation function, the network output would just be a simple linear function (one-degree polynomial) with very limited power. In which case, the algorithm would not be able to learn and model complex problems such as identifying facial features.
The results or outputs of the activation function are called activations. The cause of activations is learned by the network by adjusting the weights and biases.
Artificial Neural Networks in Deep Learning
An Artificial Neural Network is a network of interconnected (artificial) neurons or nodes, where each node represents a single information processing unit (single-layer perceptron), much like a neuron cell in the human brain.
The ‘deep’ in deep learning basically refers to creating numerous (>100) artificial neural networks with several hidden layers that are interlinked to pass information to each other in the following ways:
Feedforward networks:
- These are basically the simplest neural networks where the connections are formed through ‘forward pass’ and hence, have no loops.
- This type of organization is referred to as bottom-up or top-down. The input is fed into the network in a single direction.
- Such networks find extensive applications in pattern recognition.
Feedback networks:
- When the connections in a network are moving in both directions, it is called a feedback network.
- Here, the output derived from the network is given back to it (forming a loop) to improve its performance.
- These are dynamic networks that are complex, but also comparatively more powerful than feedforward networks.
Must Read – Machine Learning Projects to Help You Build Practical Machine Learning Skills
Types of Neural Networks
The most common types are given below:
Multi-layer Perceptron (MLP)
MLP is basically a feedforward artificial neural network with one or more hidden layers. Let’s look at the figure below to get the picture:

The above neural network is an MLP that consists of 4 interconnected layers:
- An input layer – 3 input nodes
- Hidden Layer 1 – 4 hidden nodes/4 single-layer perceptron
- Hidden layer 2 – 4 hidden nodes
- Output layer – 1 output node
As you can see, the connections in this network move in one direction only (feedforward manner).
In the real-world, however, most problems are non-linear. Hence, modern neural networks are actually comprised of sigmoid neurons and not perceptions.
Also Explore – Deep Learning Interview Questions and Answers
Convolutional Neural Network (CNN)
CNN’s are similar to regular neural networks but have nodes arranged in three dimensions. So, there’s a height, width, and depth to the networks. These are specifically designed to take images as input and are used for problems such as image recognition and face detection.
Recurrent Neural Network (RNN)
RNNs are feedforward networks that take input from the previous and/or same layers (backpropagation). The recurrent memory loops give them the unique capability to model along the time dimension and arbitrary sequence of events and inputs.
Also Explore – Top Machine Learning Interview Questions and Answers by Naukri
Endnotes
Deep learning is a vast domain and far more complex than what we have discussed in this article. From virtual assistants such as Siri and Alexa to self-driving cars like Tesla – Deep Learning has had its hands behind most major innovations in the last decade. Mastering deep learning is an endless quest and its implications are insane. Interested in learning more about this expansive field? Explore related articles here.
Top Trending Tech Articles:
Career Opportunities after BTech Online Python Compiler What is Coding Queue Data Structure Top Programming Language Trending DevOps Tools Highest Paid IT Jobs Most In Demand IT Skills Networking Interview Questions Features of Java Basic Linux Commands Amazon Interview Questions
______________
Recently completed any professional course/certification from the market? Tell us what liked or disliked in the course for more curated content.
Click here to submit its review with Shiksha Online.
