
Difference Between Precision and Recall
Discover the key differences between Precision and Recall in our latest article. Dive into examples and Python programming to understand how these metrics, based on relevance, measure the percentage of correctly identified instances. Perfect for Data Science enthusiasts!

Precision and Recall often top the list of confusing concepts for machine learning experts and data scientists. Frequently brought up in interviews, these terms can perplex beginners with incomplete explanations. In simple terms, Precision and Recall are metrics used to assess the effectiveness of classification or information retrieval systems. Precision measures the proportion of relevant instances among all retrieved instances, while Recall, also known as 'sensitivity,' gauges the fraction of retrieved instances out of all relevant ones. Ideally, a flawless classifier would score 1 in both Precision and Recall.
Before starting this blog, first, learn the essential terms which we are going to use in this article.
Important terms and their meaning
1. True Positive(TP):
- You predicted positive, and it’s true.
2. True Negative(TN):
- You predicted negative, and it’s true.
3. False Positive(FP): (Type 1 Error)
- You predicted positive, and it’s false
4. False Negative(FN): (Type 2 Error)
- You predicted negative, and it’s false.
All these terms are used in the confusion matrix.
Also read: Difference between Type 1 and Type 2 Error
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
Table of contents
- What is Precision?
- What is Recall?
- What is accuracy?
- Combining Precision and Recall
- When to use Precision and recall?
- Precision recall Python
What is Precision?
The precision metric checks the prediction accuracy of the positive class. Precision represents how many recognized/detected items are actually relevant. It is calculated by dividing true positives by total positives.

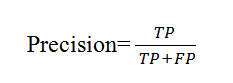
Let's take an example
Suppose the model is supposed to detect the malicious document when different documents are given to it. This model aims to prevent malicious documents from getting stored on the computer. Now try to understand these important terms corresponding to this problem.

Continuing the same example above, we have the values of true positives, false positives, true negatives, and false negatives from this confusion matrix. If you want to learn more about the confusion matrix, we have a separate blog. Just replace these values in the Precision formula.
For e.g Precision = 560/560+60 = 560/620 = 0.8
Here 0.8 means 80% precision. This means 80% of the positives were identified correctly.
You can see Precision ignores the negative class completely and considers only the positive class into account, so alone, it could be more helpful. When the classifier perfectly classifies all the positive values, the Score is ‘1’ in that case.

 Read Later
Read Later

Also Read: How tech giants are using your data?
Also read: What is machine learning?
Also read: Machine learning courses.
What is Recall?
The model’s ability to find all relevant cases in a dataset. Mathematically, we define recall as the number of true positives divided by the number of true positives and the number of false negatives.

Recall=560/560+50 = 560/610 = 0.918
If the recall value is 0.918, this means 91.8% of actual positive values were correctly classified.
Must Read: Recall Formula
Also read: Sensitivity vs. Specificity: What’s the Difference?
What is accuracy?
The accuracy in the confusion matrix tells about the correctly classified values. It tells us how accurately our classifiers are performing. It is the sum of all true values(TP and TN) divided by the total number of values.
The ability of a classification model to identify only relevant data points. Mathematically specifies the number of true positives divided by the number of true positives and the number of false positives.

Accuracy=560+330/560+330+60+50 = 890/1000 = 0.89 = 89% accuracy.
If the accuracy is 89%, then this means the model correctly classified 89% of values(TP+TN).
Also read: Difference between Accuracy and Precision
Explore: How to Calculate R squared in Linear Regression
Explore: R-squared vs. adjusted R-squared
Combining Precision and Recall
In some situations, you may need to maximize either recall or Precision at the expense of other metrics. For example, preliminary disease screening of patients for follow-up requires a recall and precision close to 1.0. We want to find all patients who have the disease but can accept a lower accuracy. However, if you want to find the best combination of Precision and recall,then use the F1 Score, which can combine the two metrics. The formula is-
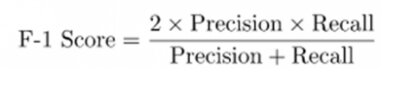
Precision and recall are two numbers used together to evaluate the performance of a classification or information retrieval system. Accuracy is defined as the percentage of relevant instances among all retrieved instances. Recall, also called “sensitivity,” is the percentage of retrieved instances among all relevant instances. A perfect classifier has both Precision and recall equal to 1.
When to use Precision and recall?
Scenario 1:
- The document is malicious but is declared non-malicious by the model.
- This indicates that the model has a high false positive (FP) rate.
- If the false positive rate is more important for solving a classification problem, then it is suggested to use Precision.
Scenario 2:
- Classification models failed to identify malicious documents and allow them to be stored.
- This situation indicates that the model has a high false negative rate.
- Recall is suggested if the false negative rate is more important according to your classification problem.
- If the class imbalance ratio is 20:80 (imbalanced data), recall is more valuable than accuracy because it can provide information about how well the machine learning model identified rarer events.
Precision recall Python
We have to predict the species of the fish.
About data set
This dataset contains seven species of fish data for market sale. We will perform it using Python. The dataset is freely available on Kaggle.
1. Species–species name of fish
2. Weight- the weight of fish in Gram
3. Length1- vertical length in cm
4. Length2- diagonal length in cm
5. Length3- cross length in cm
6. Height- height in cm
7. Width- diagonal width in cm
Importing Libraries and Reading Datasets
import pandas as pdimport numpy as npdf=pd.read_csv('Fish.csv')df
Dependent and Independent Variable
#Get Target datay = dataset[‘Species’]#Load X Variables into a Pandas Dataframe with columnsX = dataset.drop(['Species'], axis = 1)
Splitting Dataset into Training and Testing Set
# Splitting the dataset into the Training set and Test setfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Next, split both x and y into Training and testing sets with the help of the train_test_split() function. In this training, the data set is 0.8, which means 80%.
Importing and fitting Logistic Regression to the Training set
# Fitting Multiple Logistic Regression to the Training setfrom sklearn.linear_model import LogisticRegressionregressor = LogisticRegression()model=regressor.fit(X_train,y_train)
Predicting the Test set results
# Predicting the test set resultsy_pred = model.predict(X_test)print(y_pred)
Checking the accuracy score
from sklearn.metrics import accuracy_score,confusion_matrixscore= accuracy_score(y_test,y_pred)score
Output 0.83333
Checking Precision, recall and F1 Score
from sklearn.metrics import classification_reportprint(classification_report(y_test,y_pred))

Conclusion
The difference between Precision and recall in machine learning is a quick way to assess an algorithm’s performance. Recall measures how many relevant examples the algorithm can find out, while Precision measures how many right answers the algorithm can get. A high level of Precision and recall indicates that an algorithm has performed well in learning.

Comments