
How to Calculate the Degrees of Freedom
Degrees of freedom in statistics is the maximum number of logically independent values in any data sample. This article will discuss the definition, formula and how to calculate the degrees of freedom.

Degree of Freedom in statistics refers to a maximum number of logically independent values, which are values that have the freedom to vary. This article will briefly discuss the degree of freedom, its formula, and how to calculate it.
So, let’s move forward to learn more about the Degree of Freedom in statistics.
Table of Content
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
What is the Degrees of Freedom
Degree of freedom (DF) is a term that refers to the number of independent variables or observations that are available in a statistical model or analysis. In the context of linear regression, degree of freedom refers to the number of observations or data points that are used to fit the model, and it plays a crucial role in determining the precision of the model’s predictions.

Linear regression is a statistical method used to model the linear relationship between a dependent variable (also known as the response variable) and one or more independent variables (also known as predictor variables). The goal of linear regression is to find the best-fitting line that represents the relationship between the dependent and independent variables. This line is called the regression line, and it is typically represented by an equation of the form:
y = b0 + b1 * x1 + b2 * x2 + … + bn * xn
where y is the dependent variable, x1, x2, …, xn are the independent variables, and b0, b1, b2, …, bn are the regression coefficients. The regression coefficients represent the slope of the line for each independent variable and are used to predict the value of the dependent variable based on the values of the independent variables.
Degree of Freedom in Linear Regression
The degree of freedom in linear regression refers to the number of observations or data points that are used to fit the model. The number of observations is important because it determines the amount of information that is available to estimate the regression coefficients. The more observations that are available, the more precise the estimates of the coefficients will be.
There are two types of degree of freedom in linear regression:
- Residual degree of freedom
- Total degree of freedom
Residual degree of freedom (DFres) is the number of observations minus the number of regression coefficients that are being estimated. It is calculated using the following formula:
DFres = n – k
where
n is the number of observations
k is the number of regression coefficients being estimated.
The residual degree of freedom is used to determine the precision of the regression coefficients. The larger the residual degree of freedom, the more precise the estimates of the coefficients will be.
Total degree of freedom (DFtot) is the number of observations minus one. It is calculated using the following formula:
DFtot = n – 1
The total degree of freedom is used to determine the precision of the predictions made by the regression model. The larger the total degree of freedom, the more precise the predictions will be.
Factors affecting Degree of Freedom
There are several factors that can affect the degree of freedom in linear regression. One of the most important factors is the number of observations or data points that are used to fit the model. The more observations that are available, the more precise the estimates of the coefficients will be and the more precise the predictions made by the model will be.
Another factor that can affect the degree of freedom in linear regression is the number of independent variables or predictor variables that are included in the model. The more predictor variables that are included, the more coefficients need to be estimated, which can reduce the degree of freedom.
There are also statistical techniques that can be used to increase the degree of freedom in linear regression. One such technique is called multicollinearity, which involves using multiple independent variables that are highly correlated with each other to predict the dependent variable. This can increase the degree of freedom and improve the precision of the model’s predictions.
Applications of Degree of Freedom
It is important to note that the degree of freedom can also be used to test the significance of the regression coefficients and the overall fit of the model. In statistical hypothesis testing, the degree of freedom is used to determine the appropriate statistical test and to calculate the p-value, which is a measure of the likelihood that the results were obtained by chance.
For example, in linear regression, the t-test is often used to test the significance of the regression coefficients. The t-test is based on the t-distribution, which is a probability distribution that is used to calculate the p-value for a given degree of freedom. The t-distribution is used to determine the likelihood that the observed results could have occurred by chance, given the degree of freedom.
The degree of freedom also plays a role in the calculation of the standard errors of the regression coefficients and the overall fit of the model.
The standard error of a regression coefficient is a measure of the precision of the estimate of the coefficient. It is calculated as the standard deviation of the sampling distribution of the coefficient, and it is used to construct confidence intervals around the estimated coefficient. A smaller standard error indicates a more precise estimate of the coefficient.
The standard error of the regression coefficient bk is calculated using the following formula:
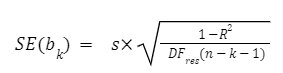
where s is the standard deviation of the residuals, DFres is the residual degree of freedom, R2 is the coefficient of determination, and n is the number of observations.
The standard error of the regression coefficient is used to calculate the t-value of the coefficient, which is used to test the hypothesis that the coefficient is significantly different from zero. The t-value is calculated using the following formula:
t = bk / SE(bk)
The t-value is then compared to a critical value from the t-distribution to determine the p-value. If the p-value is less than the specified alpha level (usually 0.05), then the hypothesis that the coefficient is significantly different from zero is rejected.
In addition to the standard errors of the regression coefficients, the degree of freedom is also used to calculate the standard error of the prediction. The standard error of the prediction is a measure of the precision of the model’s predictions and is calculated using the following formula:

where DFtot is the total degree of freedom, s is the standard deviation of the residuals, x is the value of the predictor variable, x is the mean of the predictor variable, and n is the number of observations.
The standard error of the prediction is used to construct confidence intervals around the predicted values of the dependent variable. A smaller standard error of the prediction indicates a more precise prediction.
| Programming Online Courses and Certification | Python Online Courses and Certifications |
| Data Science Online Courses and Certifications | Machine Learning Online Courses and Certifications |
Degree of Freedom in Machine Learning
In the context of machine learning, degree of freedom can be an important consideration when fitting a linear regression model. In machine learning, the goal is often to build a model that can accurately predict the value of a target variable based on a set of input features. Linear regression is a commonly used technique for this purpose, as it allows you to model the relationship between the target variable and the input features using a linear equation.
The degree of freedom in linear regression can have an impact on the performance of the model in a number of ways. First, as mentioned earlier, a larger degree of freedom can lead to more precise estimates of the regression coefficients and more precise predictions made by the model. This can be particularly useful when working with small datasets, as it can help to reduce the variance of the model and improve its generalization performance.
However, it is important to note that a large degree of freedom can also lead to overfitting, which is when a model fits the training data too closely and fails to generalize well to new data. This can occur if the model is too complex and has too many parameters, which can lead to overfitting. In this case, it may be necessary to use regularization techniques, such as L1 or L2 regularization, to reduce the complexity of the model and prevent overfitting.
In addition to the number of observations and predictor variables, the degree of freedom can also be affected by the inclusion of higher-order terms or interactions in the model. Higher-order terms and interactions can increase the complexity of the model and reduce the degree of freedom, which can lead to overfitting. It is often useful to include higher-order terms and interactions in the model if they are known to have a significant impact on the target variable, but it is important to carefully consider the trade-off between model complexity and degree of freedom to avoid overfitting.
In summary, degree of freedom can be an important consideration when fitting a linear regression model in machine learning. A larger degree of freedom can lead to more precise estimates of the regression coefficients and more precise predictions, but it can also increase the risk of overfitting. It is important to carefully consider the trade-off between model complexity and degree of freedom to ensure that the model is able to generalize well to new data.
Calculation of Degree of Freedom in Python
By using ‘statsmodel’ Library:
In Python, you can use the statsmodels library to fit a linear regression model and calculate the degree of freedom.
To begin, you will need to install the statsmodels library. You can do this by running the following command:
pip install statsmodels
Next, you will need to import the necessary modules and prepare your data. Here is an example of how to do this:
import statsmodels.api as smimport numpy as np
# prepare the datax = np.array([1, 2, 3, 4, 5])y = np.array([1, 2, 3, 4, 5])
# add a column of ones to the input dataX = sm.add_constant(x)
Now, you can use the OLS (Ordinary Least Squares) function from the statsmodels.api module to fit a linear regression model to the data. The OLS function takes the input data X and the target variable y as arguments and returns a fitted model.
# fit the linear regression modelmodel = sm.OLS(y, X).fit()
To calculate the degree of freedom, you can use the df_resid attribute of the fitted model. This attribute returns the residual degree of freedom, which is the number of observations minus the number of regression coefficients being estimated.
# calculate the residual degree of freedomdf_resid = model.df_resid
print(df_resid) # Output: 4
To calculate the total degree of freedom, you can use the df_model attribute of the fitted model. This attribute returns the total degree of freedom, which is the number of observations minus one.
# calculate the total degree of freedomdf_model = model.df_modelprint(df_model) # Output: 1
You can also use the summary method of the fitted model to view a summary of the regression results, including the degree of freedom and the standard errors of the regression coefficients.
# view a summary of the regression resultsprint(model.summary())
By using ‘scikit-learn’ Library:
In addition to the statsmodels library, you can also use the scikit-learn library to fit a linear regression model in Python. The scikit-learn library provides a LinearRegression class that can be used to fit a linear regression model to the data.
To use the LinearRegression class, you will need to import it from the sklearn.linear_model module and create an instance of the class. Then, you can use the fit method of the LinearRegression class to fit the model to the data.
from sklearn.linear_model import LinearRegression
# create an instance of the LinearRegression classlr = LinearRegression()
# fit the model to the datalr.fit(x.reshape(-1, 1), y)
To calculate the degree of freedom, you can use the df_model_ and df_resid_ attributes of the LinearRegression object. These attributes return the total degree of freedom and the residual degree of freedom, respectively.
# calculate the total degree of freedomdf_model = lr.df_model_
print(df_model) # Output: 1
# calculate the residual degree of freedomdf_resid = lr.df_resid_
print(df_resid) # Output: 4
Conclusion
In summary, degree of freedom is an important concept in linear regression and statistical analysis. It refers to the number of observations or data points that are used to fit the model and determines the precision of the model’s predictions. It is affected by the number of observations and predictor variables that are included in the model and can be used to test the significance of the regression coefficients and the overall fit of the model. Understanding degree of freedom can help you to choose the appropriate statistical tests and make informed decisions about the reliability of your results.
Contributed By: Somya Dipayan
Top Trending Article
Top Online Python Compiler | How to Check if a Python String is Palindrome | Feature Selection Technique | Conditional Statement in Python | How to Find Armstrong Number in Python | Data Types in Python | How to Find Second Occurrence of Sub-String in Python String | For Loop in Python |Prime Number | Inheritance in Python | Validating Password using Python Regex | Python List |Market Basket Analysis in Python | Python Dictionary | Python While Loop | Python Split Function | Rock Paper Scissor Game in Python | Python String | How to Generate Random Number in Python | Python Program to Check Leap Year | Slicing in Python
Interview Questions
Data Science Interview Questions | Machine Learning Interview Questions | Statistics Interview Question | Coding Interview Questions | SQL Interview Questions | SQL Query Interview Questions | Data Engineering Interview Questions | Data Structure Interview Questions | Database Interview Questions | Data Modeling Interview Questions | Deep Learning Interview Questions |
FAQs
What is degree of freedom in linear regression?
Degree of freedom in linear regression refers to the number of observations or data points that are used to fit the model. It plays a crucial role in determining the precision of the model's predictions and is affected by the number of observations and predictor variables that are included in the model.
What are the types of degree of freedom in linear regression?
There are two types of degree of freedom in linear regression: residual degree of freedom and total degree of freedom. The residual degree of freedom is the number of observations minus the number of regression coefficients being estimated, and the total degree of freedom is the number of observations minus one.
How is degree of freedom used in linear regression?
Degree of freedom is used to determine the precision of the estimates of the regression coefficients and the precision of the predictions made by the model. It is also used to test the significance of the regression coefficients and the overall fit of the model using statistical tests such as the t-test.
How does the number of observations affect the degree of freedom in linear regression?
The number of observations has a direct effect on the degree of freedom in linear regression. A larger number of observations leads to a larger degree of freedom, which can result in more precise estimates of the regression coefficients and more precise predictions made by the model.
How does the number of predictor variables affect the degree of freedom in linear regression?
The number of predictor variables also affects the degree of freedom in linear regression. A larger number of predictor variables leads to the estimation of more coefficients, which can reduce the degree of freedom. This can lead to less precise estimates of the coefficients and less precise predictions made by the model.
Can degree of freedom be increased in linear regression?
There are several ways to increase the degree of freedom in linear regression. One way is to use multicollinearity, which involves using multiple independent variables that are highly correlated with each other to predict the dependent variable. This can increase the degree of freedom and improve the precision of the model's predictions. Other methods for increasing the degree of freedom include using higher-order terms or interactions in the model or increasing the number of observations.
Can degree of freedom be decreased in linear regression?
There are several ways to decrease the degree of freedom in linear regression. One way is to use regularization techniques, such as L1 or L2 regularization, which can reduce the complexity of the model and decrease the degree of freedom. Another way to decrease the degree of freedom is to use a smaller number of predictor variables or observations in the model.
How does degree of freedom affect the t-test in linear regression?
The degree of freedom plays a crucial role in the t-test in linear regression. The t-test is a statistical test that is used to determine the significance of the regression coefficients and the overall fit of the model. The t-test is based on the t-distribution, which is a probability distribution that is used to calculate the p-value for a given degree of freedom. A larger degree of freedom can lead to a smaller p-value, which means that the results are less likely to be obtained by chance and are more statistically significant.
Can degree of freedom be negative in linear regression?
It is not possible for the degree of freedom to be negative in linear regression. The degree of freedom is calculated based on the number of observations and predictor variables that are included in the model, and both of these quantities are always positive.
How do I interpret the degree of freedom in linear regression?
The interpretation of the degree of freedom in linear regression depends on the context in which it is used. In general, a larger degree of freedom can lead to more precise estimates of the regression coefficients and more precise predictions made by the model. However, a large degree of freedom can also increase the risk of overfitting, which is when a model fits the training data too closely and fails to generalize well to new data. It is important to carefully consider the trade-off between model complexity and degree of freedom to ensure that the model is able to generalize well to new data.
