
Introduction to Bellman Ford Algorithm
Bellman Ford Algorithm is a Dynamic programming-based single source shortest path algorithm. Bellman Ford begins with a vertex and finds the shortest distance between other vertices.

Bellman ford algorithm makes use of the bottom-up approach in dynamic programming. Dynamic programming is known to provide the most optimized result of any problem, dynamic programming divides a problem into multiple smaller subproblems and solves each problem Dynamic programming has three elements that are overlapping sub-problems, optimal substructure, and memoization. Overlapping sub-problems reduces computation time as the same problem need not be computed every time, it can be stored using memoization for future usage.
In this article, we are going to discuss what is bellman ford algorithm, the role of negative weight in the bellman ford algorithm, working along with examples, and conclude this article with time complexity and applications of the algorithm.
Also explore: Understanding Data Structures in C: Types And Operations
Bellman Ford algorithm
Bellman ford is a single source shortest path algorithm based on the bottom-up approach of dynamic programming. It starts from a single vertex and calculates the shortest path from the starting vertex to all the nodes in a weighted graph.

In data structures, there are various other algorithms for the shortest path like the Dijkstra algorithm, Kruskal’s algorithm, Prim’s algorithm, etc. But all these algorithms work only when the given edge weight is positive in a graph. No algorithm provides an accurate solution when there is an edge with a negative weight.
So, Bellman Ford’s algorithm deals with graphs that have negative edge weights and guarantees to calculate the correct and optimized shortest path between vertices.
Bellman-Ford algorithm is based on the “Principle of Relaxation”
Negative edge weights of the graph can generate a negative cycle in the graph and with Dijkstra and another algorithm it is very difficult to find the shortest path when there is a negative edge in the graph, so bellman ford algorithm resolves this problem.
You can also explore: Tree Traversal in Data Structure
Best-suited Data Structures and Algorithms courses for you
Learn Data Structures and Algorithms with these high-rated online courses

Role of Negative Weight
Negative edge in a weighted graph can lead to a negative cycle in the graph which produces an incorrect result. The shortest path algorithm like Dijkstra may fall into a negative cycle and results in a shorter path because in each cycle it may result in a negative and more small value.
The negative weight of the graph must be taken care otherwise it will lead to incorrect results.
Explore: Data Structures Online Courses & Certifications

 Read Later
Read Later
The idea behind Bellman Ford Algorithm
The main idea behind the working of the bellman ford algorithm is, it begins with a single source and estimates the distance to each node. Initially, the distance is unknown and estimated as infinity, later on the algorithm relaxes those path by finding out few shorter paths. That’s why it is said that the algorithm is based on the “Principle of relaxation”.
To ensure that the obtained result is optimized or not, repeat the steps for all the vertices. If you find any new shorter path for any vertex, this means previous result was not optimized.
You can also explore: Introduction to Linked List Data Structure
Working
Now, let’s know the working of the bellman ford algorithm, and how exactly the algorithm deals with negative edges using dynamic programming approaches. the step-by-step working of the algorithm is as follows:
Step-1: Initialize the distance value Infinite to every other vertex and set distance value 0 to the source node itself.
Step-2: Visit each edge and relax the path if the previous path was not accurate. To relax the path for vertices and for edge u-v:
If, (d(u) + c(u , v) < d(v))
d(v) = d(u) + c(u , v)
the above equation means if the sum of distance value of source node and cost of moving from source to destination is less than distance of source vertex. Then, the distance value of destination vertex from the source vertex will be equals to distance value of the source and cost of reaching the destination from source.
Step-3: If the new distance value is less than the previous one, then update the distance value in each iteration for the edges. The distance value to every node is the total distance from the starting vertex to that particular vertex.
Step-4: Repeat the above steps multiple iterations, to ensure the obtained result is optimized.
You can also explore: Introduction to Huffman Coding
Example
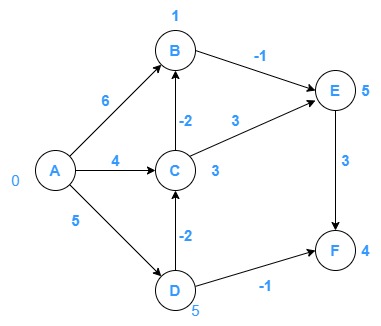
Consider the following graph, and find the shortest path using the bellman ford algorithm.

Solution:
Initially, the distance of each vertex will be infinity from the source vertex and source-to-source distance value would be zero. So, considering A to be source vertex

Relax all the edges n-1 times, where n is the number of vertices
If, [(d(u) + c(u , v) < d(v)) ]
d(v) = d(u) + c(u , v)
So, for this problem, there will be total 5 iteration as (6-1).
List out all the edges in the graph.
(A, B), (A, C), (A, D), (B, E), (D, C), (D, F) (C, E), (C, B), (E, F)
First iteration:
Let’s take (A, B), here d(u) is 0, d(v) is ∞ and c(u, v) is 6.
putting, these value in “Principle of relaxation”
If, [0 + 6 < ∞]…… True
So, [d(B) = 6]
Now, let’s take (A, C)
On putting “Principle of relaxation”
[ d(C) = 4 ]
Now, let’s take (A, D)
On putting “Principle of relaxation”
[ d(D) = 5 ]
Now, let’s take (B, E)
On putting “Principle of relaxation”
If, [6 + (-1) < ∞]…… True
So, [ d(E) = 5 ]
Now, let’s take (C, E)
On putting “Principle of relaxation”
If, [4 + 3 < 5]…… False
So, Don’t update.
Now, let’s take (D, C)
On putting “Principle of relaxation”
If, [5+ (-2) < 4]…… True
So, [ d(C) = 3 ]
Now, let’s take (D, F)
On putting “Principle of relaxation”
If, [5+ (-1) < ∞]…… True
So, [ d(F) = 4 ]
Now, let’s take (E, F)
On putting “Principle of relaxation”
If, [5+ 3 < 4]…… False
So, Don’t Update
Now, let’s take (C, B)
On putting “Principle of relaxation”
If, [3+ (-2) < 6]…… True
So, [ d(B) = 1 ]
The graph after first iteration looks as follows:
Second Iteration:
Let’s take (A, B),
putting, these value in “Principle of relaxation”
If, [0 + 6 < 1]…… False
So, Don’t update
Now, let’s take (A, C)
On putting “Principle of relaxation”
If, [0 + 4 < 3]…… False
So, Don’t update
Now, let’s take (A, D)
On putting “Principle of relaxation”
If, [0 + 5 < 5]…… False
So, Don’t update
Now, let’s take (B, E)
On putting “Principle of relaxation”
If, [1 + (-1) < 5]…… True
So, [ d(E) = 0 ]
Now, let’s take (C, E)
On putting “Principle of relaxation”
If, [3 + 3 < 0]…… False
So, Don’t update.
Now, let’s take (D, C)
On putting “Principle of relaxation”
If, [5+ (-2) < 3]…… False
So, Don’t Update
Now, let’s take (D, F)
On putting “Principle of relaxation”
If, [5+ (-1) < 4]…… False
So, Don’t Update
Now, let’s take (E, F)
On putting “Principle of relaxation”
If, [0+ 3 < 4]…… True
So, [d(F) = 3]
Now, let’s take (C, B)
On putting “Principle of relaxation”
If, [3+ (-2) < 6]…… False
So, Don’t Update
The Graph after second iteration

Third Iteration:
Let’s take (A, B),
putting, these values in the “Principle of relaxation”
If, [0 + 6 < 1]…… False
So, Don’t update
Now, let’s take (A, C)
On putting “Principle of relaxation”
If, [0 + 4 < 3]…… False
So, Don’t update
Now, let’s take (A, D)
On putting “Principle of relaxation”
If, [0 + 5 < 5]…… False
So, Don’t update
Now, let’s take (B, E)
On putting “Principle of relaxation”
If, [1 + (-1) < 0……. False
So, Don’t update
Now, let’s take (C, E)
On putting “Principle of relaxation”
If, [3 + 3 < 0]…… False
So, Don’t update.
Now, let’s take (D, C)
On putting “Principle of relaxation”
If, [5+ (-2) < 3]…… False
So, Don’t Update
Now, let’s take (D, F)
On putting “Principle of relaxation”
If, [5+ (-1) < 3]…… False
So, Don’t Update
Now, let’s take (E, F)
On putting “Principle of relaxation”
If, [0+ 3 < 3]…… False
So, Don’t Update
Now, let’s take (C, B)
On putting “Principle of relaxation”
If, [3+ (-2) < 6]…… False
So, Don’t Update
The graph after the third iteration is
According to the relaxation condition, we need at most five iterations, as we can see there are no updations or changes in the third iteration itself. So, we will stop here and write the shortest path of each vertex from A.
So, the cost for each vertex from A is
A- A: 0
A- B: 1
A- C: 3
A- D: 5
A- E: 0
A- F: 3
Psuedo Code
A path distance value is maintained for each vertex. this value can be stored in an array of size v, v is the number of a vertex in the graph.
To know the shortest path and length of the shortest path. We need to map each vertex and the latest path length to that vertex.
The pseudo-code for the bellman ford algorithm is as follows:
Bford(G, S)
for each vertex V in G
dist[V] ←infinite
prev[V] ← NULL
dist[S] ← 0
for each vertex V in G
for each edge (U, V) in G
tempDist ← dist[U] + edge_weight(U, V)
if tempDist < dist[V]
dist[V] ← tempDist
prev[V] ← U
for each edge (U,V) in G
if dist[U] + edge_weight(U, V) < dist[V}
Error: Negative Cycle Exists
return dist[], prev[]
Python Code

This implementation assumes that the graph is represented as an adjacency matrix, where the weight of the edge from vertex i to vertex j is stored in the matrix[i][j].
The function takes in two arguments: the graph represented as an adjacency matrix, and the source vertex. It returns two arrays: dist, which stores the distance from the source vertex to all other vertices, and pred, which stores the predecessor of each vertex on the shortest path from the source vertex.
The implementation consists of three steps:
- Initialization: We initialize the distance of all vertices from the source vertex to infinity, except for the source vertex itself, which is initialized to 0. We also create an array to keep track of the predecessor of each vertex on the shortest path.
- Relaxation: We iterate through all the edges in the graph, relaxing each edge. Relaxing an edge means checking if the distance to the destination vertex through the current edge is shorter than the current distance. If it is, we update the distance and the predecessor. We repeat this process for a total of V-1 iterations, where V is the number of vertices in the graph.
- Check for negative cycles: After the V-1 iterations, we check for negative cycles in the graph by iterating through all the edges again. If we find a shorter path, it means that there is a negative cycle in the graph.
Note that the time complexity of the Bellman-Ford algorithm is O(V*E), where V is the number of vertices and E is the number of edges in the graph. This is because we relax all the edges in graph V-1 times.
Complexity
Time Complexity:
| Best Case | O (E) |
| Average Case | O (VE) |
| Worst Case | O (VE) |
Space complexity: O (V)
Here, V is the number of vertices and E is the number of edges
Applications
- Network Routing: The algorithm can be used to find the shortest path in a network with negative weights, such as the internet.
- Robot Navigation: The algorithm can be used to find the shortest path for a robot to navigate in an environment with obstacles.
- Resource Allocation: The algorithm can be used to allocate resources optimally, such as assigning tasks to workers in a factory.
- Image Processing: This algorithm can be used to find the shortest path between two points in an image, it can be useful in image segmentation and object recognition.
- Game Theory: This algorithm can be used to find the optimal strategy for players in a game, such as in the game of chess.
- Genetics: The algorithm can be used to find the shortest path in a genetic network, which can be used to analyze genetic interactions and identify potential drug targets.
Drawback:
- Bellman-Ford algorithm will fail if the graph will having any negative edge cycle.
Key Takeaway:
It may seem like Negative weight is an unrealistic and hypothetical concept, how weight or distance could be negative or how an edge can be negative.
Negative weights represent a lot, like cash flow, and heat absorption/ release in any chemical reaction. Negative weights are realistic and useful.
FAQs
How does the Bellman-Ford algorithm work?
The algorithm starts by assigning a tentative distance value to all vertices, with the distance of the source vertex set to 0 and all other vertices set to infinity. It then iterates through all the edges multiple times, relaxing the edges by updating the tentative distance values. In each iteration, the algorithm considers all edges and checks if a shorter path to a vertex can be found by going through the current vertex. This process continues until no more updates to the tentative distances are possible or until a negative cycle is detected.
What is the significance of the Bellman-Ford algorithm?
The Bellman-Ford algorithm is widely used in network routing protocols, such as the Border Gateway Protocol (BGP), to find the shortest paths in networks with dynamic link weights. It is also used in applications where negative edge weights are present or when it is necessary to detect negative cycles in a graph.
Are there any limitations or drawbacks of the Bellman-Ford algorithm?
One limitation of the Bellman-Ford algorithm is its relatively higher time complexity compared to Dijkstra's algorithm, which can make it less efficient for large graphs. Additionally, the algorithm may enter an infinite loop if a negative cycle exists in the graph. To handle this, it is important to detect and handle negative cycles appropriately to avoid erroneous results.
