
Ensemble learning: Beginners tutorial
The ensemble methods in machine learning combine the insights obtained from multiple learning models to facilitate accurate and improved decisions. In this article we will focus on ensemble learning and its different types.This concept is explaind with real-life examples.
The pre-trained model you are using may only perform optimal for some classes in your dataset.Similarly, another pretrained model may work well for other classes of the same data. Therefore, we need a method that can combine the performance of all these models and provide a better solution for all data distributions. This is how the concept of ensemble learning comes into play. And let me tell you – it’s a real game changer.
In this article, we will learn about ensemble learning which helps improve machine learning results by combining multiple models. This approach can produce better predictive performance compared to a single model. The basic idea is to train a set of classifiers (experts) and give them a chance to vote.

Table of contents
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses
What is ensemble learning?
The ensemble method is a machine learning technique that combines multiple base models/weak learners to create an optimal predictive model. Machine learning ensemble techniques combine insights from multiple weak learners to drive accurate and improved decision-making.
Averaging is an approach to ensemble learning in which each weak learner contributes to the final prediction.
Why ensemble learning?
The performance of the model weights the contribution of each model/weak learner to the final prediction.
There are two main reasons for choosing an ensemble over a single model.
- Performance: Ensembles can make better predictions and perform better than single-contribution models.
- Robustness: Ensemble learning reduces the spread or dispersion of the predictions and model performance.

 Read Later
Read Later

Also explore: How to evaluate the machine learning model.
Also explore: How to improve the machine learning model
Real-life example of ensemble learning
Example 1
Whether buying furniture or electronics, going to college, or watching a movie, ask your friends and family for their input and base your final decision on that. So the same applies to ensemble learning. Suppose a student wants to choose a course after 10+2 and needs help deciding which course to take based on their abilities. So he consulted different people: teachers, his parents, cousins, students, and professionals. Ultimately, after consulting with various people, the course proposed by most people will be decided.
Example 2
When you go to amazon to buy anything, you check the ratings of that product which different customers give. You buy product by checking the ratings of that product. Suppose the rating is 4.5 and is given by only one customer. Then you don’t believe that rating as it’s the view of only one person. But if different people are given the ratings, the overall rating turns out to be 4.5. Then you consider it more accurate.
In the same way, when the different models give the output, then the final output is taken considering the output of all these models. Then that output tends to be more accurate.
Also explore: How to choose a data science course
Also read: Check Out Our Data Science Courses
Simple Ensemble Techniques
In this section, we will look at a few simple but powerful techniques, namely:
1. Max Voting
The maximum vote method is commonly used for classification problems. This technique uses multiple models to make predictions for each data point. Predictions from each model are considered “votes.” The predictions from most of the models are used as final predictions.
For example,
Let’s take an example where we have three classifiers with the following predictions:
Classifier 1 – Class B
Classifier 2 – Class B
Classifier 3 – Class A
The final prediction here will be class B with the most votes.
Such a method is suitable for binary classification problems where there are only two candidates that the classifier can vote for. However, many classes fail due to problems, as often, every class has a clear majority of votes.
2. Averaging
With averaging, the final output will be the average of all predictions. This applies to regression problems. For example, in random forest regression, the final result is the average of predictions from individual decision trees.
Let’s look at an example of three regression models that predict commodity prices as follows:
Regressor 1 – 500
Regressor 2 – 200
Regressor 3 – 100
The final prediction will be the average of 500, 200, and 100.
3. Weighted Averaging
A weighted average emphasizes the underlying model with high predictive power. In the price forecast example, each regressor is assigned a weight. Because the model weights are only small positive values and the sum of all weights equals 1, the weights can indicate each model’s confidence or expected performance percentage.
Suppose the regressors are given weights of 0.35, 0.2, and 0.1, respectively. The final model prediction can be computed as
P=W1*p1+ W2*p2+ W3*p3
Where W1, W2, W3 are the weights.
And p1,p2, and p3 are predictions by different models.
P=Final prediction
0.35 * 100 + 0.2 * 200 + 0.1 * 500 = 285.
Also read: Machine Learning Online Courses & Certifications
Advanced Ensemble Methods
1. Bagging
An ensemble learning method reduces errors by training homogeneous weak learners in parallel on different random samples from the training set. The results of these base learners are combined by voting or averaging to create a more robust and accurate ensemble model.
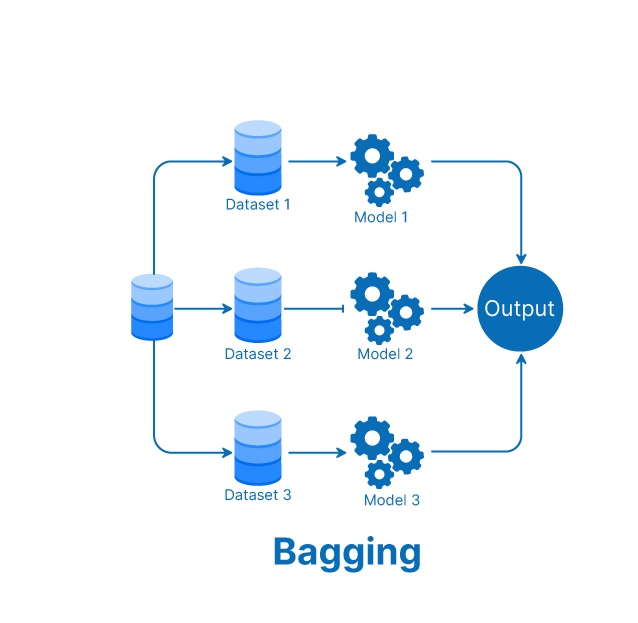
Bagging primarily focuses on obtaining an ensemble model with less variance than the underlying models composing it. Therefore, the bagging technique helps avoid overfitting the model.
Steps of bagging technique
- To create randomly sampled data sets of the original training data bootstrapping
- To build and fit several classifiers.
- To make a final overall prediction ensemble learning methods, take an average of the predictions.
2. Boosting
It is an ensemble learning method in which homogeneous weak learners are trained sequentially such that the base model depends on previously fitted base models. Then we combine all these base learners in a highly adaptive way to get an ensemble model. In simple words the ensemble model is the weighted sum of all configuration-based learners in boosting.

Steps of boosting technique
Suppose we have 3 weak learners classifier 1, classifier 2, and classifier 3To train a classifier 1 that best classifies the data with respect to accuracy.
- To identify regions where classifier 1 produces errors, add weights to them, and produce classifier 2.
- To aggregate those samples for which classifier 1 gives a different result from classifier 2 and produces classifier
- Repeat step 2 for the new classifier.
3. Stacking
Stacking is the process of combining different estimators to reduce bias. Predictions from each estimator are stacked and used as input to a final estimator (usually called a metamodel or metaclassifier) that computes the final prediction. The final estimator is trained by cross-validation.
Stacking can be performed on both regression and classification problems.

How is random forest an ensemble learning model?
Random forest is an excellent example of ensemble machine learning. It combines various decision trees to produce a more generalized model by reducing the notorious overfitting tendency of decision trees. Random forests are utilized to produce correlated decision trees. It creates random subsets of the features; smaller trees are built using these subsets, creating tree diversity.
Note-To overcomes overfitting, diverse sets of decision trees required boosting.
Conclusion
Ensemble models are usually more accurate than single models. This is to mitigate the overfitting problem while combining the strengths of different models.
Ensemble modeling can exponentially improve model performance and be the deciding factor separating first and second place! We’ve seen how the techniques are applied to machine learning algorithms.
This article will give you a solid understanding of this topic. If you want to explore more, we have a separate blog on bagging and boosting techniques.
KEEP SHARING!!!
HAPPY LEARNING!!!
